 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTuningIQA: Fine-Grained Blind Image Quality Assessment for Livestreaming Camera Tuning
Aug 25, 2025



Livestreaming has become increasingly prevalent in modern visual communication, where automatic camera quality tuning is essential for delivering superior user Quality of Experience (QoE). Such tuning requires accurate blind image quality assessment (BIQA) to guide parameter optimization decisions. Unfortunately, the existing BIQA models typically only predict an overall coarse-grained quality score, which cannot provide fine-grained perceptual guidance for precise camera parameter tuning. To bridge this gap, we first establish FGLive-10K, a comprehensive fine-grained BIQA database containing 10,185 high-resolution images captured under varying camera parameter configurations across diverse livestreaming scenarios. The dataset features 50,925 multi-attribute quality annotations and 19,234 fine-grained pairwise preference annotations. Based on FGLive-10K, we further develop TuningIQA, a fine-grained BIQA metric for livestreaming camera tuning, which integrates human-aware feature extraction and graph-based camera parameter fusion. Extensive experiments and comparisons demonstrate that TuningIQA significantly outperforms state-of-the-art BIQA methods in both score regression and fine-grained quality ranking, achieving superior performance when deployed for livestreaming camera tuning.
FakeScope: Large Multimodal Expert Model for Transparent AI-Generated Image Forensics
Mar 31, 2025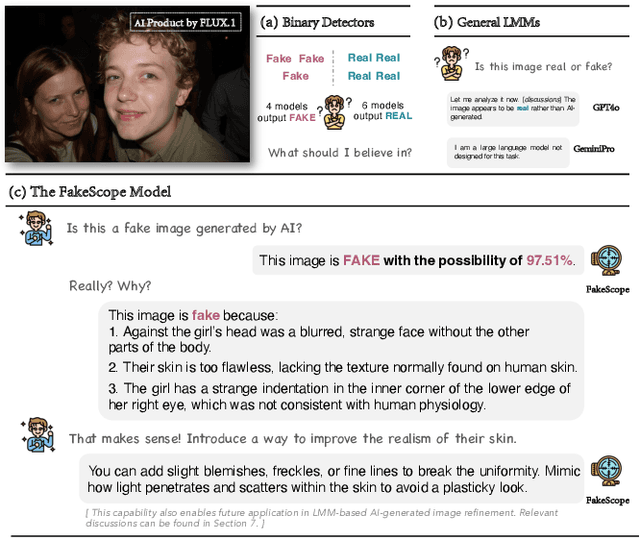



The rapid and unrestrained advancement of generative artificial intelligence (AI) presents a double-edged sword: while enabling unprecedented creativity, it also facilitates the generation of highly convincing deceptive content, undermining societal trust. As image generation techniques become increasingly sophisticated, detecting synthetic images is no longer just a binary task: it necessitates interpretable, context-aware methodologies that enhance trustworthiness and transparency. However, existing detection models primarily focus on classification, offering limited explanatory insights into image authenticity. In this work, we propose FakeScope, an expert multimodal model (LMM) tailored for AI-generated image forensics, which not only identifies AI-synthetic images with high accuracy but also provides rich, interpretable, and query-driven forensic insights. We first construct FakeChain dataset that contains linguistic authenticity reasoning based on visual trace evidence, developed through a novel human-machine collaborative framework. Building upon it, we further present FakeInstruct, the largest multimodal instruction tuning dataset containing 2 million visual instructions tailored to enhance forensic awareness in LMMs. FakeScope achieves state-of-the-art performance in both closed-ended and open-ended forensic scenarios. It can distinguish synthetic images with high accuracy while offering coherent and insightful explanations, free-form discussions on fine-grained forgery attributes, and actionable enhancement strategies. Notably, despite being trained exclusively on qualitative hard labels, FakeScope demonstrates remarkable zero-shot quantitative capability on detection, enabled by our proposed token-based probability estimation strategy. Furthermore, FakeScope exhibits strong generalization and in-the-wild ability, ensuring its applicability in real-world scenarios.
AesExpert: Towards Multi-modality Foundation Model for Image Aesthetics Perception
Apr 15, 2024



The highly abstract nature of image aesthetics perception (IAP) poses significant challenge for current multimodal large language models (MLLMs). The lack of human-annotated multi-modality aesthetic data further exacerbates this dilemma, resulting in MLLMs falling short of aesthetics perception capabilities. To address the above challenge, we first introduce a comprehensively annotated Aesthetic Multi-Modality Instruction Tuning (AesMMIT) dataset, which serves as the footstone for building multi-modality aesthetics foundation models. Specifically, to align MLLMs with human aesthetics perception, we construct a corpus-rich aesthetic critique database with 21,904 diverse-sourced images and 88K human natural language feedbacks, which are collected via progressive questions, ranging from coarse-grained aesthetic grades to fine-grained aesthetic descriptions. To ensure that MLLMs can handle diverse queries, we further prompt GPT to refine the aesthetic critiques and assemble the large-scale aesthetic instruction tuning dataset, i.e. AesMMIT, which consists of 409K multi-typed instructions to activate stronger aesthetic capabilities. Based on the AesMMIT database, we fine-tune the open-sourced general foundation models, achieving multi-modality Aesthetic Expert models, dubbed AesExpert. Extensive experiments demonstrate that the proposed AesExpert models deliver significantly better aesthetic perception performances than the state-of-the-art MLLMs, including the most advanced GPT-4V and Gemini-Pro-Vision. Source data will be available at https://github.com/yipoh/AesExpert.
AesBench: An Expert Benchmark for Multimodal Large Language Models on Image Aesthetics Perception
Jan 16, 2024With collective endeavors, multimodal large language models (MLLMs) are undergoing a flourishing development. However, their performances on image aesthetics perception remain indeterminate, which is highly desired in real-world applications. An obvious obstacle lies in the absence of a specific benchmark to evaluate the effectiveness of MLLMs on aesthetic perception. This blind groping may impede the further development of more advanced MLLMs with aesthetic perception capacity. To address this dilemma, we propose AesBench, an expert benchmark aiming to comprehensively evaluate the aesthetic perception capacities of MLLMs through elaborate design across dual facets. (1) We construct an Expert-labeled Aesthetics Perception Database (EAPD), which features diversified image contents and high-quality annotations provided by professional aesthetic experts. (2) We propose a set of integrative criteria to measure the aesthetic perception abilities of MLLMs from four perspectives, including Perception (AesP), Empathy (AesE), Assessment (AesA) and Interpretation (AesI). Extensive experimental results underscore that the current MLLMs only possess rudimentary aesthetic perception ability, and there is still a significant gap between MLLMs and humans. We hope this work can inspire the community to engage in deeper explorations on the aesthetic potentials of MLLMs. Source data will be available at https://github.com/yipoh/AesBench.