 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Unified Framework for Unsupervised Complex Tabular Reasoning
Paper and Code

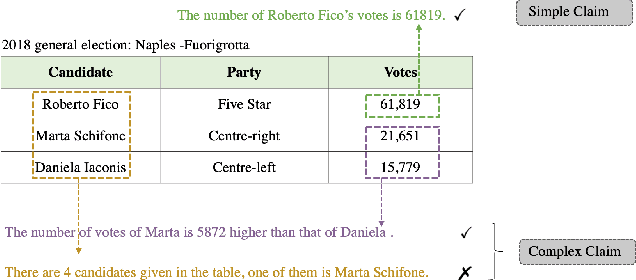

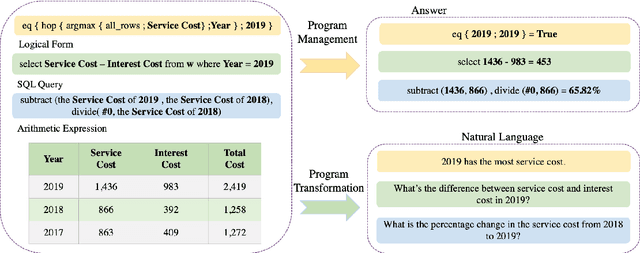
Structured tabular data exist across nearly all fields. Reasoning task over these data aims to answer questions or determine the truthiness of hypothesis sentences by understanding the semantic meaning of a table. While previous works have devoted significant efforts to the tabular reasoning task, they always assume there are sufficient labeled data. However, constructing reasoning samples over tables (and related text) is labor-intensive, especially when the reasoning process is complex. When labeled data is insufficient, the performance of models will suffer an unendurable decline. In this paper, we propose a unified framework for unsupervised complex tabular reasoning (UCTR), which generates sufficient and diverse synthetic data with complex logic for tabular reasoning tasks, assuming no human-annotated data at all. We first utilize a random sampling strategy to collect diverse programs of different types and execute them on tables based on a "Program-Executor" module. To bridge the gap between the programs and natural language sentences, we design a powerful "NL-Generator" module to generate natural language sentences with complex logic from these programs. Since a table often occurs with its surrounding texts, we further propose novel "Table-to-Text" and "Text-to-Table" operators to handle joint table-text reasoning scenarios. This way, we can adequately exploit the unlabeled table resources to obtain a well-performed reasoning model under an unsupervised setting. Our experiments cover different tasks (question answering and fact verification) and different domains (general and specific), showing that our unsupervised methods can achieve at most 93% performance compared to supervised models. We also find that it can substantially boost the supervised performance in low-resourced domains as a data augmentation technique. Our code is available at https://github.com/leezythu/UCTR.