 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Backdoor: Towards Stealthy Real-world Poisoning Attack on Vision-Language-Action Model in State Space
Jan 07, 2026Vision-Language-Action (VLA) models are widely deployed in safety-critical embodied AI applications such as robotics. However, their complex multimodal interactions also expose new security vulnerabilities. In this paper, we investigate a backdoor threat in VLA models, where malicious inputs cause targeted misbehavior while preserving performance on clean data. Existing backdoor methods predominantly rely on inserting visible triggers into visual modality, which suffer from poor robustness and low insusceptibility in real-world settings due to environmental variability. To overcome these limitations, we introduce the State Backdoor, a novel and practical backdoor attack that leverages the robot arm's initial state as the trigger. To optimize trigger for insusceptibility and effectiveness, we design a Preference-guided Genetic Algorithm (PGA) that efficiently searches the state space for minimal yet potent triggers. Extensive experiments on five representative VLA models and five real-world tasks show that our method achieves over 90% attack success rate without affecting benign task performance, revealing an underexplored vulnerability in embodied AI systems.
Wan: Open and Advanced Large-Scale Video Generative Models
Mar 26, 2025



This report presents Wan, a comprehensive and open suite of video foundation models designed to push the boundaries of video generation. Built upon the mainstream diffusion transformer paradigm, Wan achieves significant advancements in generative capabilities through a series of innovations, including our novel VAE, scalable pre-training strategies, large-scale data curation, and automated evaluation metrics. These contributions collectively enhance the model's performance and versatility. Specifically, Wan is characterized by four key features: Leading Performance: The 14B model of Wan, trained on a vast dataset comprising billions of images and videos, demonstrates the scaling laws of video generation with respect to both data and model size. It consistently outperforms the existing open-source models as well as state-of-the-art commercial solutions across multiple internal and external benchmarks, demonstrating a clear and significant performance superiority. Comprehensiveness: Wan offers two capable models, i.e., 1.3B and 14B parameters, for efficiency and effectiveness respectively. It also covers multiple downstream applications, including image-to-video, instruction-guided video editing, and personal video generation, encompassing up to eight tasks. Consumer-Grade Efficiency: The 1.3B model demonstrates exceptional resource efficiency, requiring only 8.19 GB VRAM, making it compatible with a wide range of consumer-grade GPUs. Openness: We open-source the entire series of Wan, including source code and all models, with the goal of fostering the growth of the video generation community. This openness seeks to significantly expand the creative possibilities of video production in the industry and provide academia with high-quality video foundation models. All the code and models are available at https://github.com/Wan-Video/Wan2.1.
MetaDD: Boosting Dataset Distillation with Neural Network Architecture-Invariant Generalization
Oct 07, 2024



Dataset distillation (DD) entails creating a refined, compact distilled dataset from a large-scale dataset to facilitate efficient training. A significant challenge in DD is the dependency between the distilled dataset and the neural network (NN) architecture used. Training a different NN architecture with a distilled dataset distilled using a specific architecture often results in diminished trainning performance for other architectures. This paper introduces MetaDD, designed to enhance the generalizability of DD across various NN architectures. Specifically, MetaDD partitions distilled data into meta features (i.e., the data's common characteristics that remain consistent across different NN architectures) and heterogeneous features (i.e., the data's unique feature to each NN architecture). Then, MetaDD employs an architecture-invariant loss function for multi-architecture feature alignment, which increases meta features and reduces heterogeneous features in distilled data. As a low-memory consumption component, MetaDD can be seamlessly integrated into any DD methodology. Experimental results demonstrate that MetaDD significantly improves performance across various DD methods. On the Distilled Tiny-Imagenet with Sre2L (50 IPC), MetaDD achieves cross-architecture NN accuracy of up to 30.1\%, surpassing the second-best method (GLaD) by 1.7\%.
Graph Diffusion Policy Optimization
Feb 26, 2024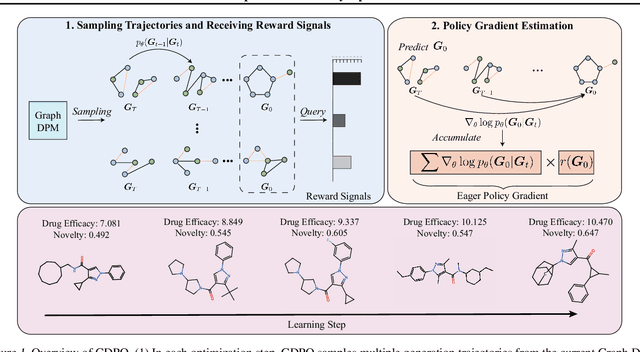


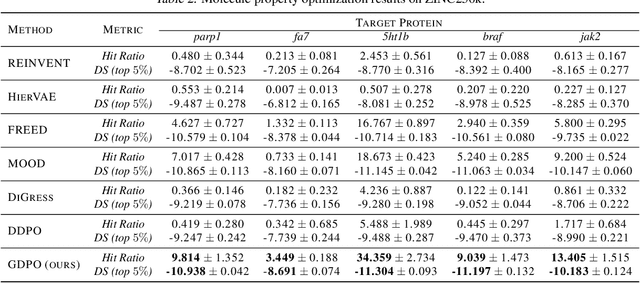
Recent research has made significant progress in optimizing diffusion models for specific downstream objectives, which is an important pursuit in fields such as graph generation for drug design. However, directly applying these models to graph diffusion presents challenges, resulting in suboptimal performance. This paper introduces graph diffusion policy optimization (GDPO), a novel approach to optimize graph diffusion models for arbitrary (e.g., non-differentiable) objectives using reinforcement learning. GDPO is based on an eager policy gradient tailored for graph diffusion models, developed through meticulous analysis and promising improved performance. Experimental results show that GDPO achieves state-of-the-art performance in various graph generation tasks with complex and diverse objectives. Code is available at https://github.com/sail-sg/GDPO.
Using Terminal Circuit for Power System Electromagnetic Transient Simulation
Jul 01, 2021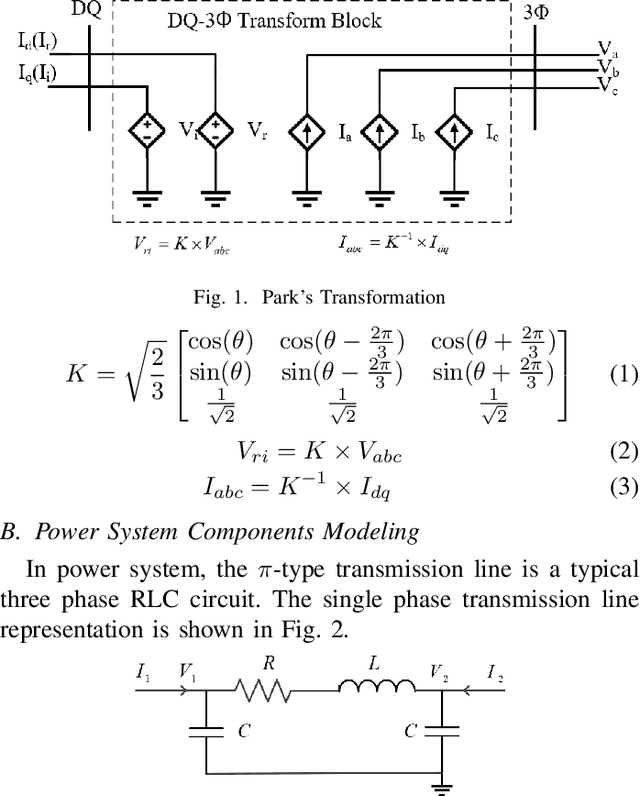
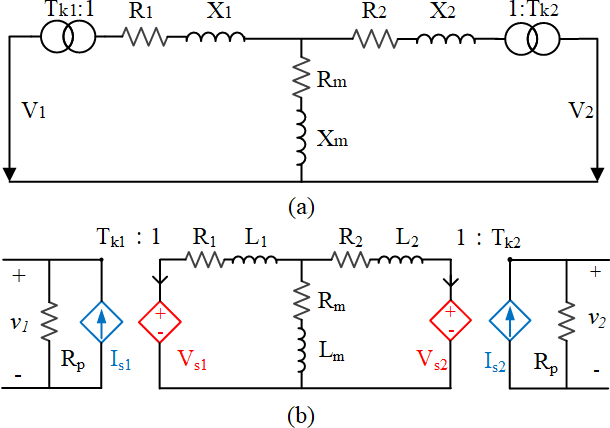
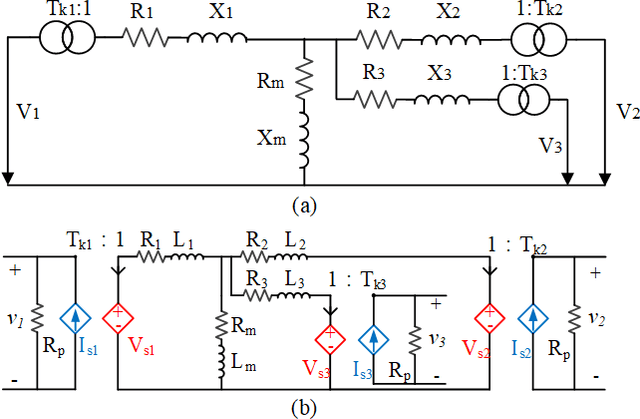
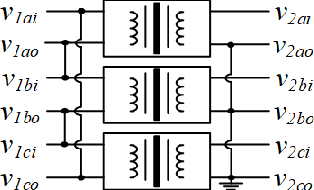
The modern power system is evolving with increasing penetration of power electronics introducing complicated electromagnetic phenomenon. Electromagnetic transient (EMT) simulation is essential to understand power system behavior under disturbance which however is one of the most sophisticated and time-consuming applications in power system. To improve the electromagnetic transient simulation efficiency while keeping the simulation accuracy, this paper proposes to model and simulate power system electromagnetic transients by very large-scale integrated circuit (VLSI) as a preliminary exploration to eventually represent power system by VLSI circuit chip avoiding numerical calculation. To proof the concept, a simple 5 bus system is modeled and simulated to verify the feasibility of the proposed approach.
Power System Transient Modeling and Simulation using Integrated Circuit
Jun 06, 2021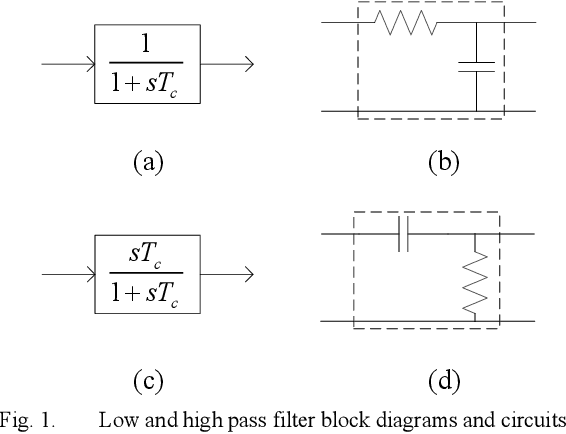
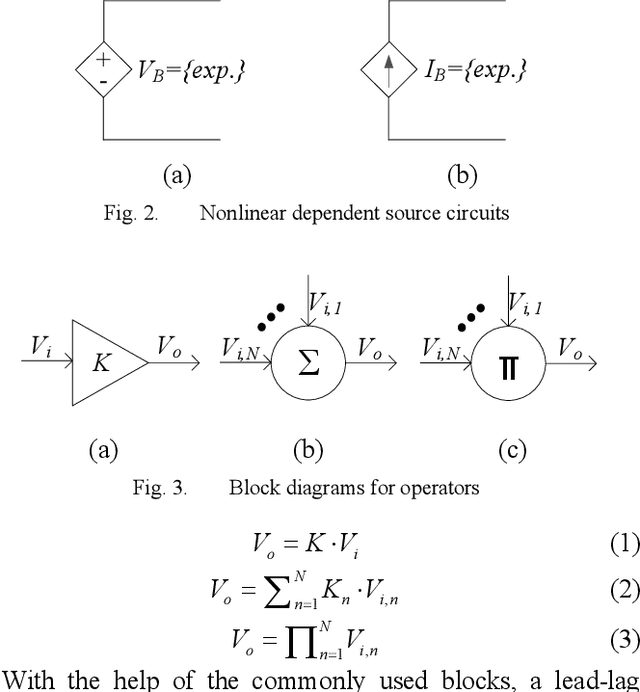
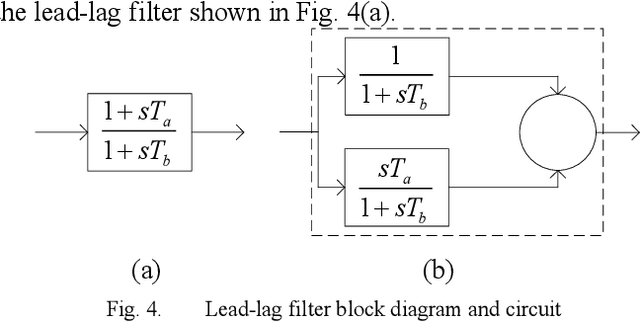
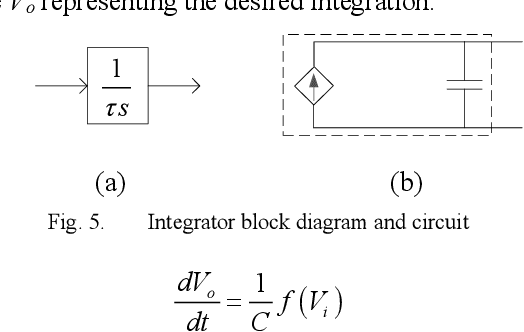
Transient stability analysis (TSA) plays an important role in power system analysis to investigate the stability of power system. Traditionally, transient stability analysis methods have been developed using time domain simulation by means of numerical integration method. In this paper, a new approach is proposed to model power systems as an integrated circuit and simulate the power system dynamic behavior by integrated circuit simulator. The proposed method modeled power grid, generator, governor, and exciter with high fidelity. The power system dynamic simulation accuracy and efficiency of the proposed approach are verified and demonstrated by case study on an IEEE standard system.