 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Diffusion Policy Optimization
Paper and Code
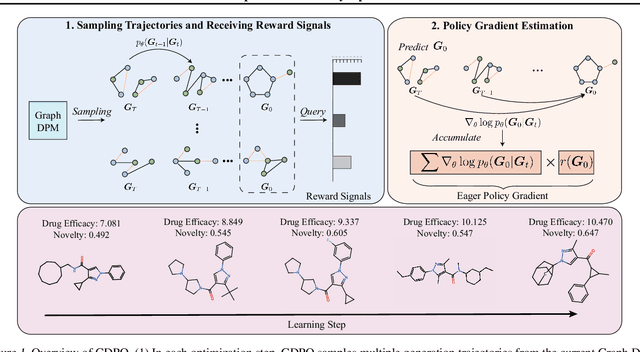


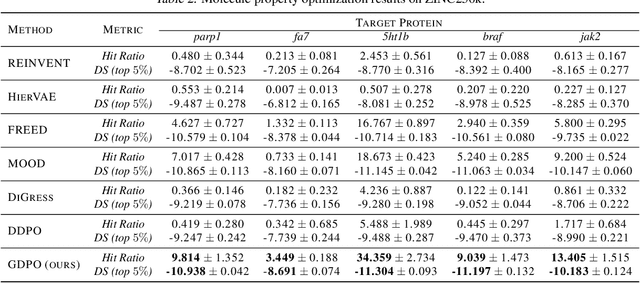
Recent research has made significant progress in optimizing diffusion models for specific downstream objectives, which is an important pursuit in fields such as graph generation for drug design. However, directly applying these models to graph diffusion presents challenges, resulting in suboptimal performance. This paper introduces graph diffusion policy optimization (GDPO), a novel approach to optimize graph diffusion models for arbitrary (e.g., non-differentiable) objectives using reinforcement learning. GDPO is based on an eager policy gradient tailored for graph diffusion models, developed through meticulous analysis and promising improved performance. Experimental results show that GDPO achieves state-of-the-art performance in various graph generation tasks with complex and diverse objectives. Code is available at https://github.com/sail-sg/GDPO.