 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMoE: Neural Architecture Search for Efficient Sparsely Activated Transformers
Paper and Code

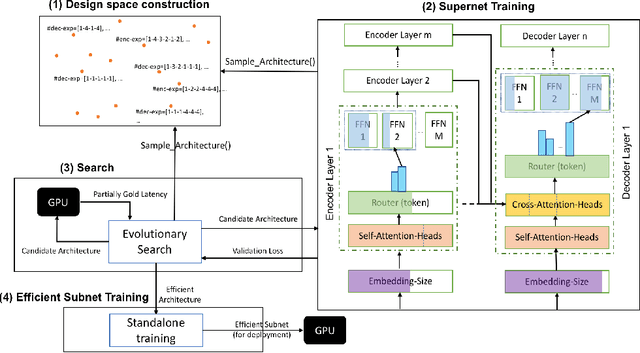


Neural architecture search (NAS) has demonstrated promising results on identifying efficient Transformer architectures which outperform manually designed ones for natural language tasks like neural machine translation (NMT). Existing NAS methods operate on a space of dense architectures, where all of the sub-architecture weights are activated for every input. Motivated by the recent advances in sparsely activated models like the Mixture-of-Experts (MoE) model, we introduce sparse architectures with conditional computation into the NAS search space. Given this expressive search space which subsumes prior densely activated architectures, we develop a new framework AutoMoE to search for efficient sparsely activated sub-Transformers. AutoMoE-generated sparse models obtain (i) 3x FLOPs reduction over manually designed dense Transformers and (ii) 23% FLOPs reduction over state-of-the-art NAS-generated dense sub-Transformers with parity in BLEU score on benchmark datasets for NMT. AutoMoE consists of three training phases: (a) Heterogeneous search space design with dense and sparsely activated Transformer modules (e.g., how many experts? where to place them? what should be their sizes?); (b) SuperNet training that jointly trains several subnetworks sampled from the large search space by weight-sharing; (c) Evolutionary search for the architecture with the optimal trade-off between task performance and computational constraint like FLOPs and latency. AutoMoE code, data and trained models are available at https://github.com/microsoft/AutoMoE.