Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Extraneous Content in Podcasts
Paper and Code
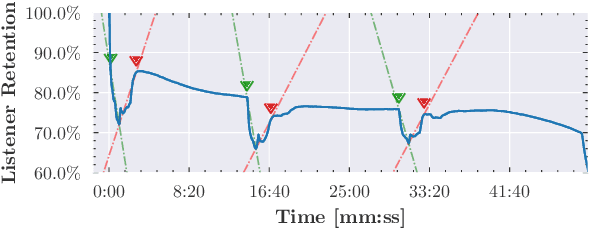
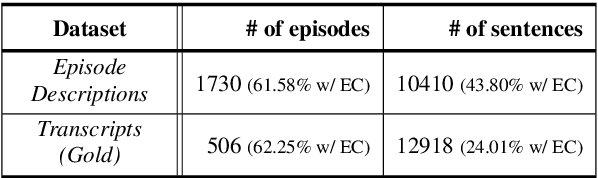
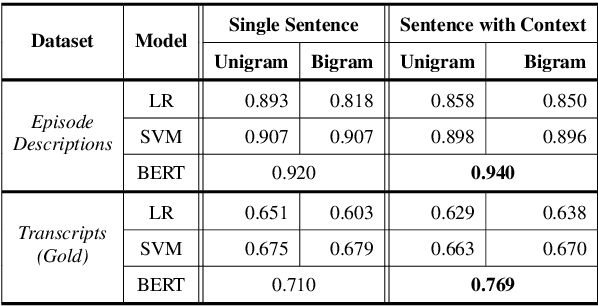
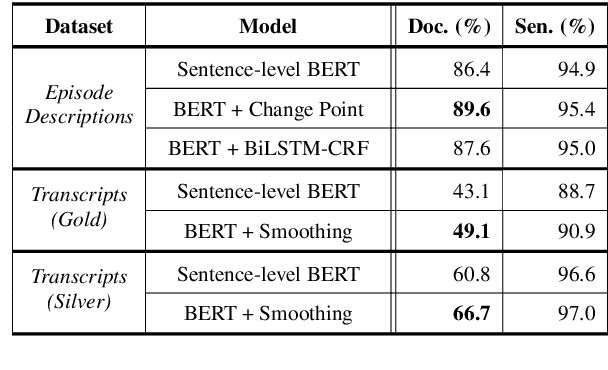
Podcast episodes often contain material extraneous to the main content, such as advertisements, interleaved within the audio and the written descriptions. We present classifiers that leverage both textual and listening patterns in order to detect such content in podcast descriptions and audio transcripts. We demonstrate that our models are effective by evaluating them on the downstream task of podcast summarization and show that we can substantively improve ROUGE scores and reduce the extraneous content generated in the summaries.
* EACL 2021
View paper on