 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReddit After Roe: A Computational Analysis of Abortion Narratives and Barriers in the Wake of Dobbs
Mar 23, 2026The 2022 U.S. Supreme Court decision in Dobbs v. Jackson Women's Health Organization reshaped the reproductive rights landscape, introducing new uncertainty and barriers to abortion access. We present a large-scale computational analysis of abortion discourse on Reddit, examining how barriers to access are articulated across information-seeking and information-sharing behaviors, different stages of abortion (before, during, after), and three phases of the Dobbs decision in 2022. Drawing on more than 17,000 posts from four abortion-related subreddits, we employed a multi-step pipeline to classify posts by information type, abortion stage, barrier category, and expressed emotions. Using a codebook of eight barrier types, including legal, financial, emotional, and social obstacles, we analyzed their associations with emotions and information behaviors. Topic modeling of model-generated barrier rationales further revealed how discourse evolved in response to shifting legal and cultural contexts. Our findings show that emotional and psychological barriers consistently dominate abortion narratives online, with emotions such as nervousness, confusion, fear, and sadness prevalent across discourse. By linking information behaviors, barriers, emotions, and temporal dynamics, this study provides a multi-dimensional account of how abortion is navigated in online communities.
Like a Therapist, But Not: Reddit Narratives of AI in Mental Health Contexts
Jan 28, 2026Large language models (LLMs) are increasingly used for emotional support and mental health-related interactions outside clinical settings, yet little is known about how people evaluate and relate to these systems in everyday use. We analyze 5,126 Reddit posts from 47 mental health communities describing experiential or exploratory use of AI for emotional support or therapy. Grounded in the Technology Acceptance Model and therapeutic alliance theory, we develop a theory-informed annotation framework and apply a hybrid LLM-human pipeline to analyze evaluative language, adoption-related attitudes, and relational alignment at scale. Our results show that engagement is shaped primarily by narrated outcomes, trust, and response quality, rather than emotional bond alone. Positive sentiment is most strongly associated with task and goal alignment, while companionship-oriented use more often involves misaligned alliances and reported risks such as dependence and symptom escalation. Overall, this work demonstrates how theory-grounded constructs can be operationalized in large-scale discourse analysis and highlights the importance of studying how users interpret language technologies in sensitive, real-world contexts.
A Transformer and Prototype-based Interpretable Model for Contextual Sarcasm Detection
Mar 14, 2025Sarcasm detection, with its figurative nature, poses unique challenges for affective systems designed to perform sentiment analysis. While these systems typically perform well at identifying direct expressions of emotion, they struggle with sarcasm's inherent contradiction between literal and intended sentiment. Since transformer-based language models (LMs) are known for their efficient ability to capture contextual meanings, we propose a method that leverages LMs and prototype-based networks, enhanced by sentiment embeddings to conduct interpretable sarcasm detection. Our approach is intrinsically interpretable without extra post-hoc interpretability techniques. We test our model on three public benchmark datasets and show that our model outperforms the current state-of-the-art. At the same time, the prototypical layer enhances the model's inherent interpretability by generating explanations through similar examples in the reference time. Furthermore, we demonstrate the effectiveness of incongruity loss in the ablation study, which we construct using sentiment prototypes.
From #Dr00gtiktok to #harmreduction: Exploring Substance Use Hashtags on TikTok
Jan 27, 2025
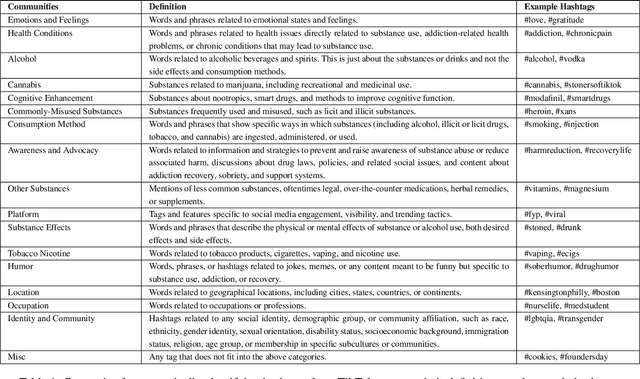
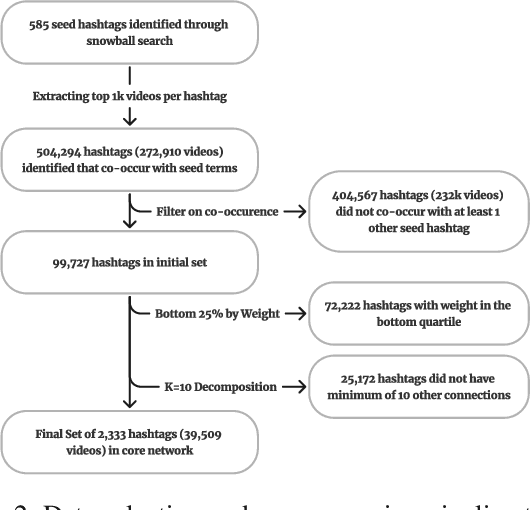
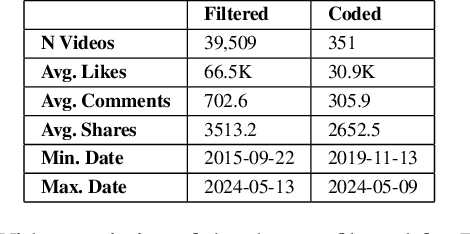
The rise of TikTok as a primary source of information for youth, combined with its unique short-form video format, creates urgent questions about how substance use content manifests and spreads on the platform. This paper provides the first in-depth exploration of substance use-related content on TikTok, covering all major substance categories as classified by the Drug Enforcement Agency. Through social network analysis and qualitative coding, we examined more than 2,333 hashtags across 39,509 videos, identified 16 distinct hashtag communities and analyzed their interconnections and thematic content. Our analysis revealed a highly interconnected small-world network where recovery-focused hashtags like #addiction, #recovery, and #sober serve as central bridges between communities. Through manual coding of 351 representative videos, we found that Recovery Advocacy content (33.9%) and Satirical content (28.2%) dominate, while direct substance depiction appears in only 26% of videos, with active use shown in just 6.5% of them. This suggests TikTok functions primarily as a recovery support platform rather than a space promoting substance use. We found strong alignment between hashtag communities and video content, indicating organic community formation rather than attempts to evade content moderation. Our findings inform how platforms can balance content moderation with preserving valuable recovery support communities, while also providing insights for the design of social media-based recovery interventions.
From Conversation to Automation: Leveraging Large Language Models to Analyze Strategies in Problem Solving Therapy
Jan 10, 2025
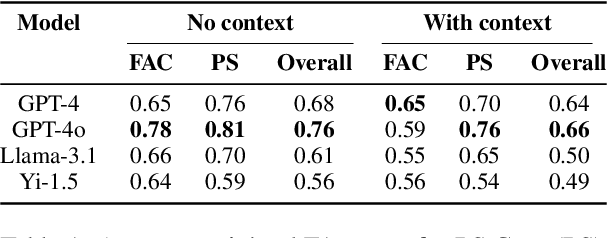
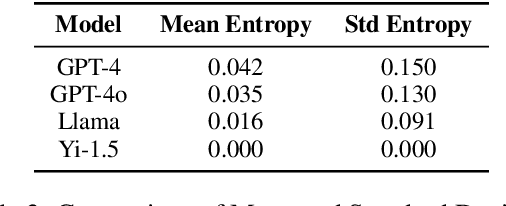
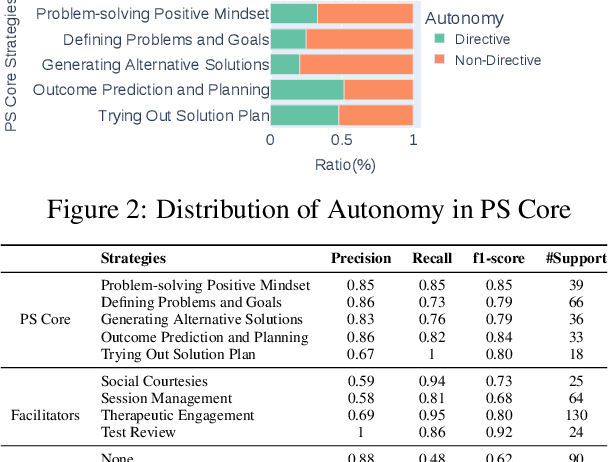
Problem-solving therapy (PST) is a structured psychological approach that helps individuals manage stress and resolve personal issues by guiding them through problem identification, solution brainstorming, decision-making, and outcome evaluation. As mental health care increasingly integrates technologies like chatbots and large language models (LLMs), understanding how PST can be effectively automated is important. This study leverages anonymized therapy transcripts to analyze and classify therapeutic interventions using various LLMs and transformer-based models. Our results show that GPT-4o achieved the highest accuracy (0.76) in identifying PST strategies, outperforming other models. Additionally, we introduced a new dimension of communication strategies that enhances the current PST framework, offering deeper insights into therapist-client interactions. This research demonstrates the potential of LLMs to automate complex therapeutic dialogue analysis, providing a scalable, efficient tool for mental health interventions. Our annotation framework can enhance the accessibility, effectiveness, and personalization of PST, supporting therapists in real-time with more precise, targeted interventions.
Words Matter: Reducing Stigma in Online Conversations about Substance Use with Large Language Models
Aug 15, 2024Stigma is a barrier to treatment for individuals struggling with substance use disorders (SUD), which leads to significantly lower treatment engagement rates. With only 7% of those affected receiving any form of help, societal stigma not only discourages individuals with SUD from seeking help but isolates them, hindering their recovery journey and perpetuating a cycle of shame and self-doubt. This study investigates how stigma manifests on social media, particularly Reddit, where anonymity can exacerbate discriminatory behaviors. We analyzed over 1.2 million posts, identifying 3,207 that exhibited stigmatizing language towards people who use substances (PWUS). Using Informed and Stylized LLMs, we develop a model for de-stigmatization of these expressions into empathetic language, resulting in 1,649 reformed phrase pairs. Our paper contributes to the field by proposing a computational framework for analyzing stigma and destigmatizing online content, and delving into the linguistic features that propagate stigma towards PWUS. Our work not only enhances understanding of stigma's manifestations online but also provides practical tools for fostering a more supportive digital environment for those affected by SUD. Code and data will be made publicly available upon acceptance.
Decoding the Narratives: Analyzing Personal Drug Experiences Shared on Reddit
Jun 17, 2024Online communities such as drug-related subreddits serve as safe spaces for people who use drugs (PWUD), fostering discussions on substance use experiences, harm reduction, and addiction recovery. Users' shared narratives on these forums provide insights into the likelihood of developing a substance use disorder (SUD) and recovery potential. Our study aims to develop a multi-level, multi-label classification model to analyze online user-generated texts about substance use experiences. For this purpose, we first introduce a novel taxonomy to assess the nature of posts, including their intended connections (Inquisition or Disclosure), subjects (e.g., Recovery, Dependency), and specific objectives (e.g., Relapse, Quality, Safety). Using various multi-label classification algorithms on a set of annotated data, we show that GPT-4, when prompted with instructions, definitions, and examples, outperformed all other models. We apply this model to label an additional 1,000 posts and analyze the categories of linguistic expression used within posts in each class. Our analysis shows that topics such as Safety, Combination of Substances, and Mental Health see more disclosure, while discussions about physiological Effects focus on harm reduction. Our work enriches the understanding of PWUD's experiences and informs the broader knowledge base on SUD and drug use.
The Evolution of Substance Use Coverage in the Philadelphia Inquirer
Jul 03, 2023
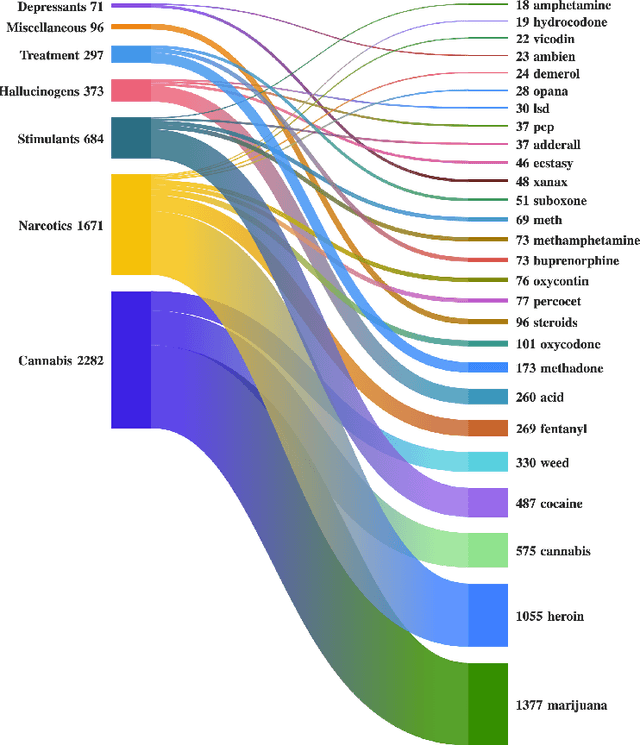
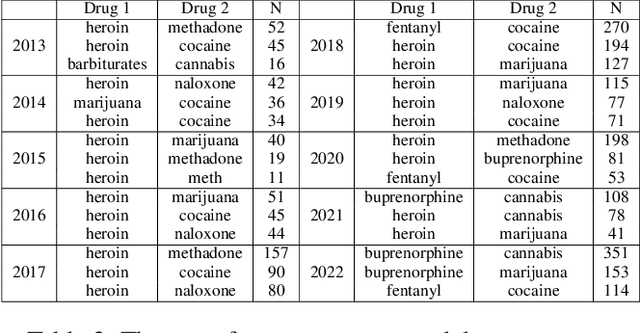
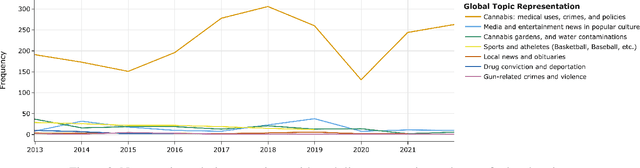
The media's representation of illicit substance use can lead to harmful stereotypes and stigmatization for individuals struggling with addiction, ultimately influencing public perception, policy, and public health outcomes. To explore how the discourse and coverage of illicit drug use changed over time, this study analyzes 157,476 articles published in the Philadelphia Inquirer over a decade. Specifically, the study focuses on articles that mentioned at least one commonly abused substance, resulting in a sample of 3,903 articles. Our analysis shows that cannabis and narcotics are the most frequently discussed classes of drugs. Hallucinogenic drugs are portrayed more positively than other categories, whereas narcotics are portrayed the most negatively. Our research aims to highlight the need for accurate and inclusive portrayals of substance use and addiction in the media.
Spotify at TREC 2020: Genre-Aware Abstractive Podcast Summarization
Apr 07, 2021
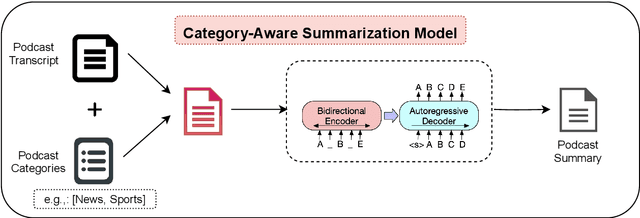
This paper contains the description of our submissions to the summarization task of the Podcast Track in TREC (the Text REtrieval Conference) 2020. The goal of this challenge was to generate short, informative summaries that contain the key information present in a podcast episode using automatically generated transcripts of the podcast audio. Since podcasts vary with respect to their genre, topic, and granularity of information, we propose two summarization models that explicitly take genre and named entities into consideration in order to generate summaries appropriate to the style of the podcasts. Our models are abstractive, and supervised using creator-provided descriptions as ground truth summaries. The results of the submitted summaries show that our best model achieves an aggregate quality score of 1.58 in comparison to the creator descriptions and a baseline abstractive system which both score 1.49 (an improvement of 9%) as assessed by human evaluators.
Detecting Extraneous Content in Podcasts
Mar 03, 2021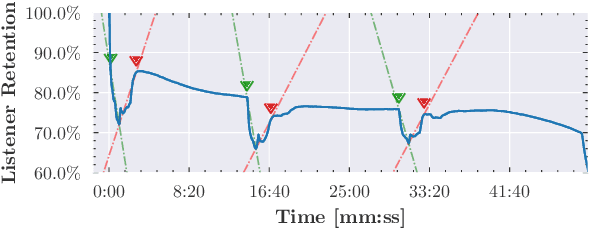
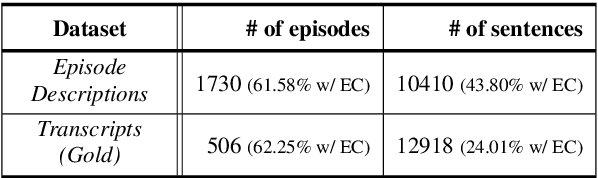
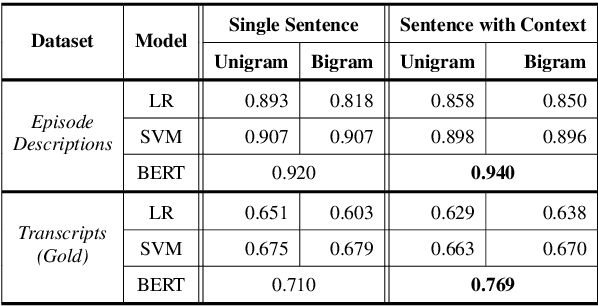
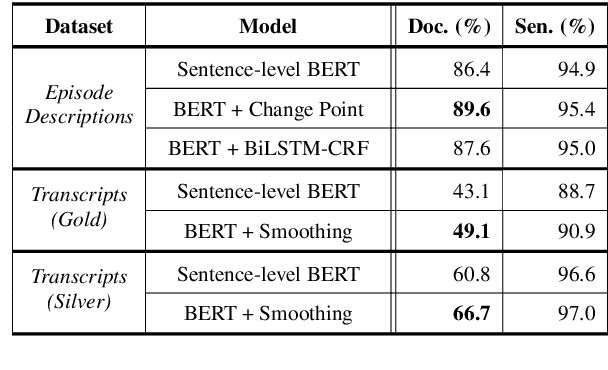
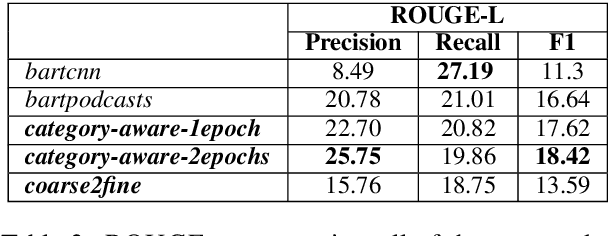
Podcast episodes often contain material extraneous to the main content, such as advertisements, interleaved within the audio and the written descriptions. We present classifiers that leverage both textual and listening patterns in order to detect such content in podcast descriptions and audio transcripts. We demonstrate that our models are effective by evaluating them on the downstream task of podcast summarization and show that we can substantively improve ROUGE scores and reduce the extraneous content generated in the summaries.