 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpotify at TREC 2020: Genre-Aware Abstractive Podcast Summarization
Paper and Code
Apr 07, 2021
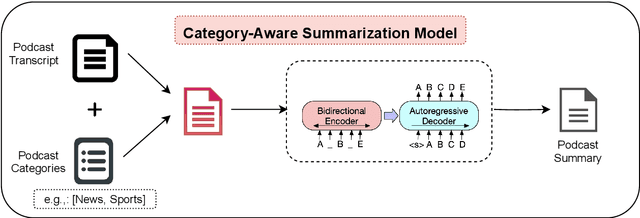
This paper contains the description of our submissions to the summarization task of the Podcast Track in TREC (the Text REtrieval Conference) 2020. The goal of this challenge was to generate short, informative summaries that contain the key information present in a podcast episode using automatically generated transcripts of the podcast audio. Since podcasts vary with respect to their genre, topic, and granularity of information, we propose two summarization models that explicitly take genre and named entities into consideration in order to generate summaries appropriate to the style of the podcasts. Our models are abstractive, and supervised using creator-provided descriptions as ground truth summaries. The results of the submitted summaries show that our best model achieves an aggregate quality score of 1.58 in comparison to the creator descriptions and a baseline abstractive system which both score 1.49 (an improvement of 9%) as assessed by human evaluators.