Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention, please! A Critical Review of Neural Attention Models in Natural Language Processing
Paper and Code


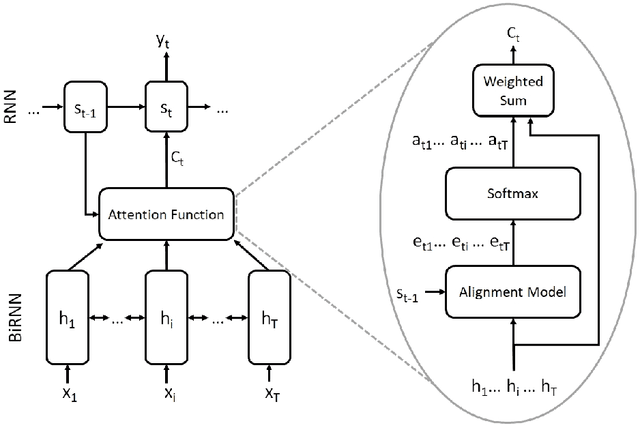
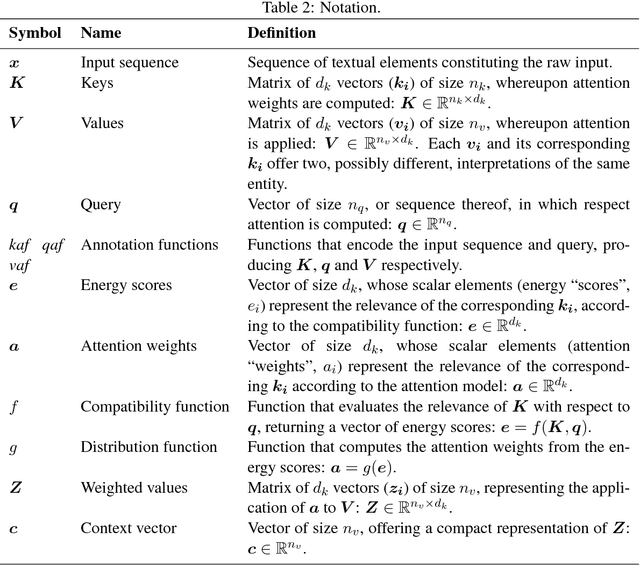
Attention is an increasingly popular mechanism used in a wide range of neural architectures. Because of the fast-paced advances in this domain, a systematic overview of attention is still missing. In this article, we define a unified model for attention architectures for natural language processing, with a focus on architectures designed to work with vector representation of the textual data. We discuss the dimensions along which proposals differ, the possible uses of attention, and chart the major research activities and open challenges in the area.
View paper on