 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Preserving Code Generation: Differentially Private Code Language Models
Dec 12, 2025Large language models specialized for code (CodeLLMs) have demonstrated remarkable capabilities in generating code snippets, documentation, and test cases. However, despite their promising capabilities, CodeLLMs can inadvertently memorize and reproduce snippets from their training data, which poses risks of privacy breaches and intellectual property violations. These risks restrict the deployment of CodeLLMs in sensitive domains and limit their training datasets to publicly available sources. To mitigate the memorization risk without compromising their task performance, we apply Differential Privacy (DP) to CodeLLMs. To the best of our knowledge, this is the first comprehensive study that systematically evaluates the effectiveness of DP in CodeLLMs. DP adds calibrated noise to the training process to protect individual data points while still allowing the model to learn useful patterns. To this end, we first identify and understand the driving reasons of the memorization behaviour of the CodeLLMs during their fine-tuning. Then, to address this issue, we empirically evaluate the effect of DP on mitigating memorization while preserving code generation capabilities. Our findings show that DP substantially reduces memorization in CodeLLMs across all the tested snippet types. The snippet types most prone to memorization are also the most effectively mitigated by DP. Furthermore, we observe that DP slightly increases perplexity but preserves, and can even enhance, the code generation capabilities of CodeLLMs, which makes it feasible to apply DP in practice without significantly compromising model utility. Finally, we analyze the impact of DP on training efficiency and energy consumption, finding that DP does not significantly affect training time or energy usage, making it a practical choice for privacy-preserving CodeLLMs training.
Can We Make Code Green? Understanding Trade-Offs in LLMs vs. Human Code Optimizations
Mar 26, 2025The rapid technological evolution has accelerated software development for various domains and use cases, contributing to a growing share of global carbon emissions. While recent large language models (LLMs) claim to assist developers in optimizing code for performance and energy efficiency, their efficacy in real-world scenarios remains under exploration. In this work, we explore the effectiveness of LLMs in reducing the environmental footprint of real-world projects, focusing on software written in Matlab-widely used in both academia and industry for scientific and engineering applications. We analyze energy-focused optimization on 400 scripts across 100 top GitHub repositories. We examine potential 2,176 optimizations recommended by leading LLMs, such as GPT-3, GPT-4, Llama, and Mixtral, and a senior Matlab developer, on energy consumption, memory usage, execution time consumption, and code correctness. The developer serves as a real-world baseline for comparing typical human and LLM-generated optimizations. Mapping these optimizations to 13 high-level themes, we found that LLMs propose a broad spectrum of improvements--beyond energy efficiency--including improving code readability and maintainability, memory management, error handling while the developer overlooked some parallel processing, error handling etc. However, our statistical tests reveal that the energy-focused optimizations unexpectedly negatively impacted memory usage, with no clear benefits regarding execution time or energy consumption. Our qualitative analysis of energy-time trade-offs revealed that some themes, such as vectorization preallocation, were among the common themes shaping these trade-offs. With LLMs becoming ubiquitous in modern software development, our study serves as a call to action: prioritizing the evaluation of common coding practices to identify the green ones.
LEXTREME: A Multi-Lingual and Multi-Task Benchmark for the Legal Domain
Jan 30, 2023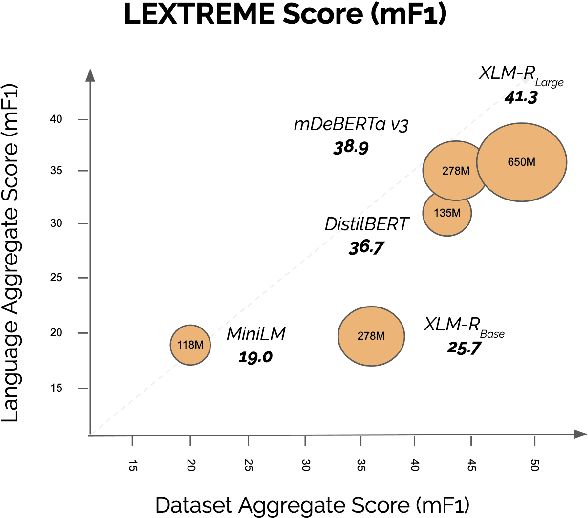
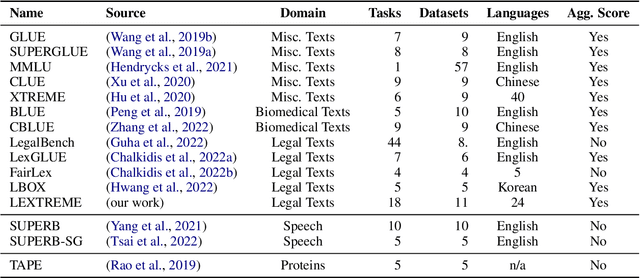
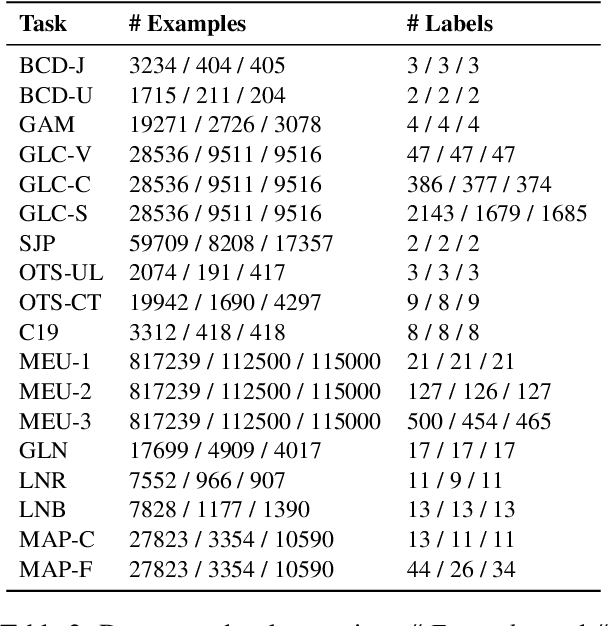
Lately, propelled by the phenomenal advances around the transformer architecture, the legal NLP field has enjoyed spectacular growth. To measure progress, well curated and challenging benchmarks are crucial. However, most benchmarks are English only and in legal NLP specifically there is no multilingual benchmark available yet. Additionally, many benchmarks are saturated, with the best models clearly outperforming the best humans and achieving near perfect scores. We survey the legal NLP literature and select 11 datasets covering 24 languages, creating LEXTREME. To provide a fair comparison, we propose two aggregate scores, one based on the datasets and one on the languages. The best baseline (XLM-R large) achieves both a dataset aggregate score a language aggregate score of 61.3. This indicates that LEXTREME is still very challenging and leaves ample room for improvement. To make it easy for researchers and practitioners to use, we release LEXTREME on huggingface together with all the code required to evaluate models and a public Weights and Biases project with all the runs.