 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess discovery on deviant traces and other stranger things
Sep 30, 2021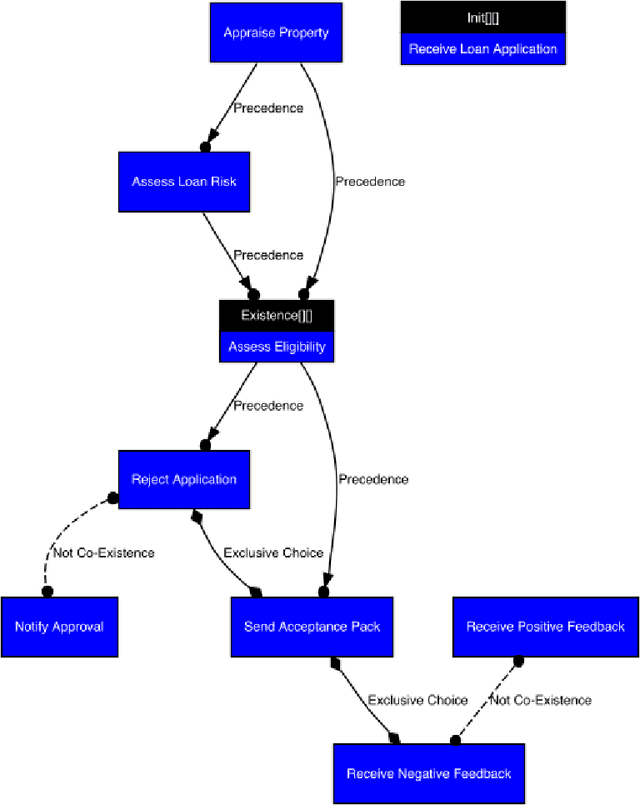
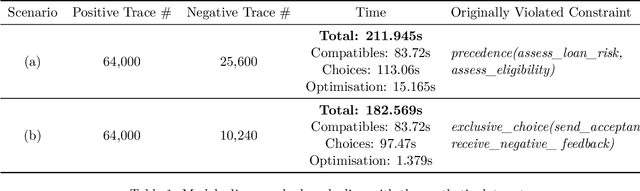
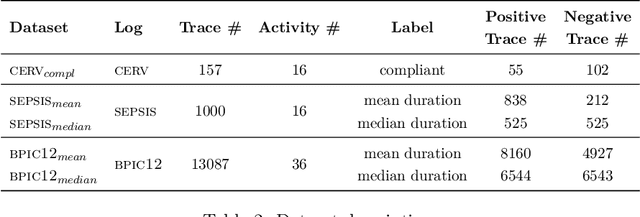

As the need to understand and formalise business processes into a model has grown over the last years, the process discovery research field has gained more and more importance, developing two different classes of approaches to model representation: procedural and declarative. Orthogonally to this classification, the vast majority of works envisage the discovery task as a one-class supervised learning process guided by the traces that are recorded into an input log. In this work instead, we focus on declarative processes and embrace the less-popular view of process discovery as a binary supervised learning task, where the input log reports both examples of the normal system execution, and traces representing "stranger" behaviours according to the domain semantics. We therefore deepen how the valuable information brought by both these two sets can be extracted and formalised into a model that is "optimal" according to user-defined goals. Our approach, namely NegDis, is evaluated w.r.t. other relevant works in this field, and shows promising results as regards both the performance and the quality of the obtained solution.
Parallelizing Machine Learning as a Service for the End-User
May 29, 2020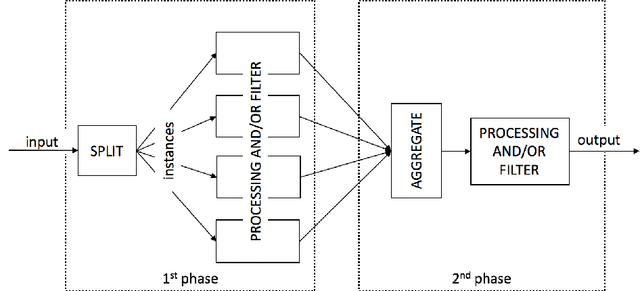
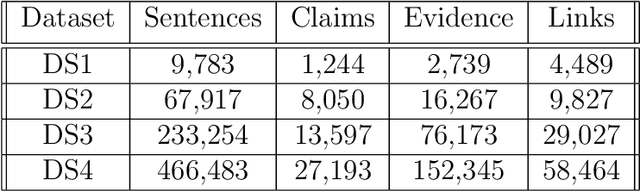

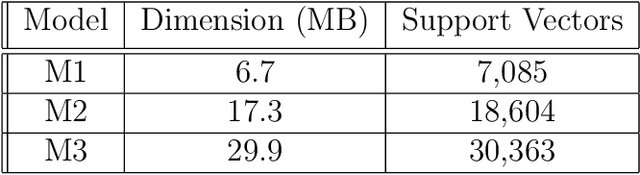
As ML applications are becoming ever more pervasive, fully-trained systems are made increasingly available to a wide public, allowing end-users to submit queries with their own data, and to efficiently retrieve results. With increasingly sophisticated such services, a new challenge is how to scale up to evergrowing user bases. In this paper, we present a distributed architecture that could be exploited to parallelize a typical ML system pipeline. We propose a case study consisting of a text mining service and discuss how the method can be generalized to many similar applications. We demonstrate the significance of the computational gain boosted by the distributed architecture by way of an extensive experimental evaluation.