 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Synthetic Data adoption in regulated domains
Apr 13, 2022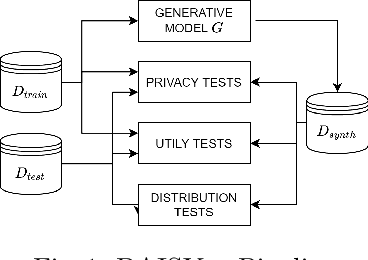
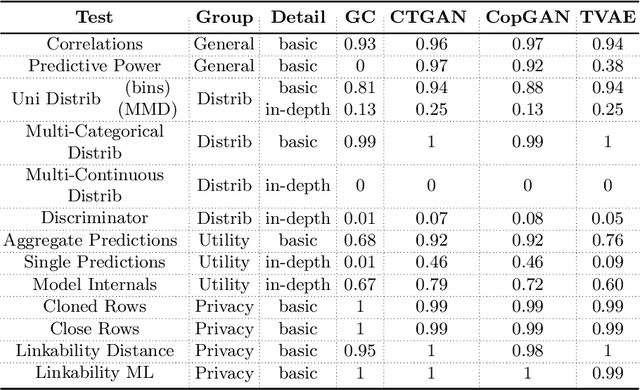
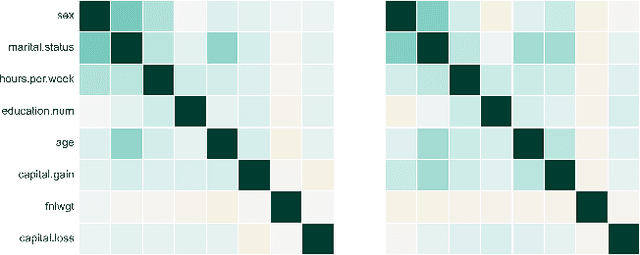

The switch from a Model-Centric to a Data-Centric mindset is putting emphasis on data and its quality rather than algorithms, bringing forward new challenges. In particular, the sensitive nature of the information in highly regulated scenarios needs to be accounted for. Specific approaches to address the privacy issue have been developed, as Privacy Enhancing Technologies. However, they frequently cause loss of information, putting forward a crucial trade-off among data quality and privacy. A clever way to bypass such a conundrum relies on Synthetic Data: data obtained from a generative process, learning the real data properties. Both Academia and Industry realized the importance of evaluating synthetic data quality: without all-round reliable metrics, the innovative data generation task has no proper objective function to maximize. Despite that, the topic remains under-explored. For this reason, we systematically catalog the important traits of synthetic data quality and privacy, and devise a specific methodology to test them. The result is DAISYnt (aDoption of Artificial Intelligence SYnthesis): a comprehensive suite of advanced tests, which sets a de facto standard for synthetic data evaluation. As a practical use-case, a variety of generative algorithms have been trained on real-world Credit Bureau Data. The best model has been assessed, using DAISYnt on the different synthetic replicas. Further potential uses, among others, entail auditing and fine-tuning of generative models or ensuring high quality of a given synthetic dataset. From a prescriptive viewpoint, eventually, DAISYnt may pave the way to synthetic data adoption in highly regulated domains, ranging from Finance to Healthcare, through Insurance and Education.
Process discovery on deviant traces and other stranger things
Sep 30, 2021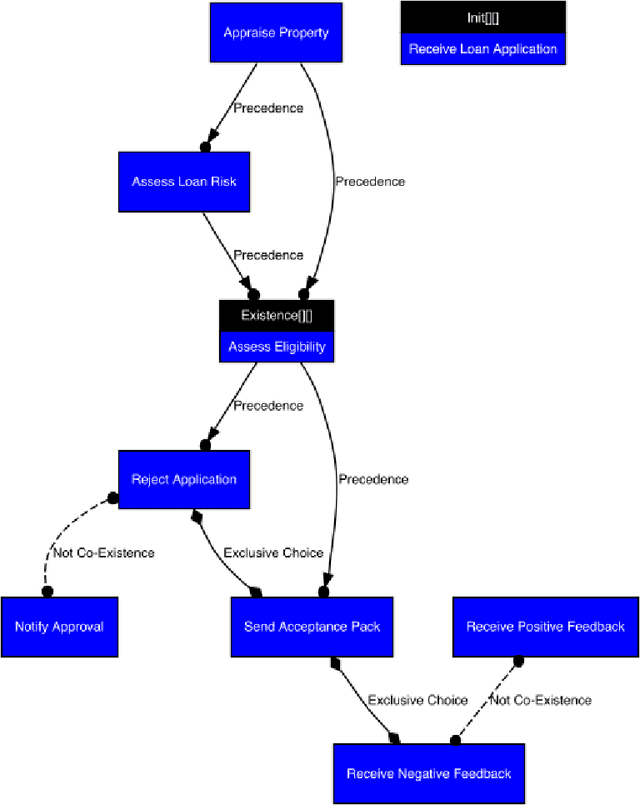
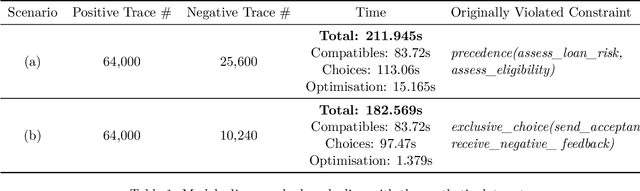
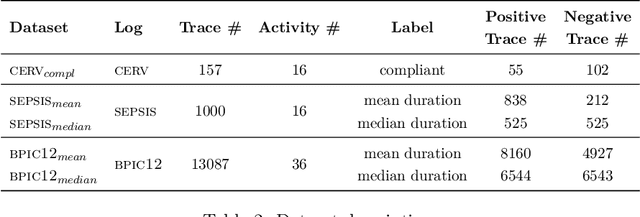

As the need to understand and formalise business processes into a model has grown over the last years, the process discovery research field has gained more and more importance, developing two different classes of approaches to model representation: procedural and declarative. Orthogonally to this classification, the vast majority of works envisage the discovery task as a one-class supervised learning process guided by the traces that are recorded into an input log. In this work instead, we focus on declarative processes and embrace the less-popular view of process discovery as a binary supervised learning task, where the input log reports both examples of the normal system execution, and traces representing "stranger" behaviours according to the domain semantics. We therefore deepen how the valuable information brought by both these two sets can be extracted and formalised into a model that is "optimal" according to user-defined goals. Our approach, namely NegDis, is evaluated w.r.t. other relevant works in this field, and shows promising results as regards both the performance and the quality of the obtained solution.
Explanations of Machine Learning predictions: a mandatory step for its application to Operational Processes
Dec 30, 2020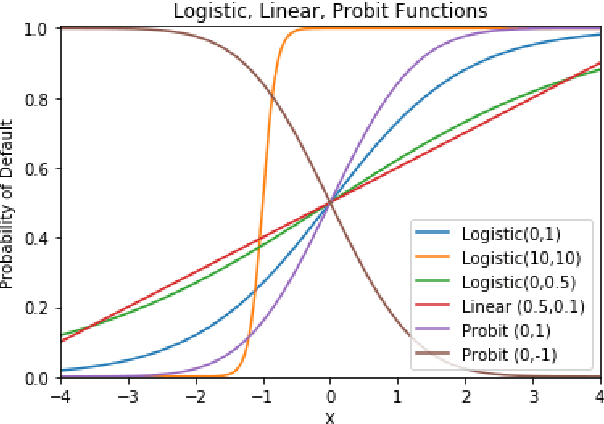
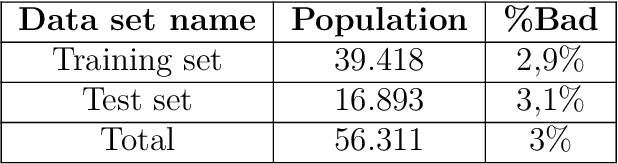
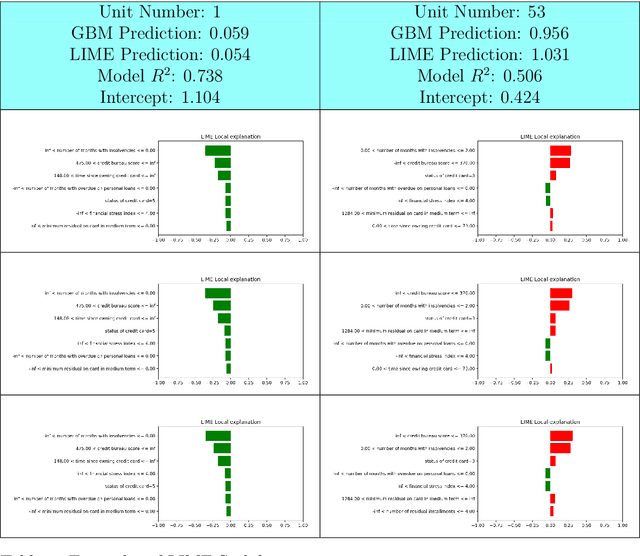
In the global economy, credit companies play a central role in economic development, through their activity as money lenders. This important task comes with some drawbacks, mainly the risk of the debtors not being able to repay the provided credit. Therefore, Credit Risk Modelling (CRM), namely the evaluation of the probability that a debtor will not repay the due amount, plays a paramount role. Statistical approaches have been successfully exploited since long, becoming the most used methods for CRM. Recently, also machine and deep learning techniques have been applied to the CRM task, showing an important increase in prediction quality and performances. However, such techniques usually do not provide reliable explanations for the scores they come up with. As a consequence, many machine and deep learning techniques fail to comply with western countries' regulations such as, for example, GDPR. In this paper we suggest to use LIME (Local Interpretable Model-agnostic Explanations) technique to tackle the explainability problem in this field, we show its employment on a real credit-risk dataset and eventually discuss its soundness and the necessary improvements to guarantee its adoption and compliance with the task.
OptiLIME: Optimized LIME Explanations for Diagnostic Computer Algorithms
Jun 10, 2020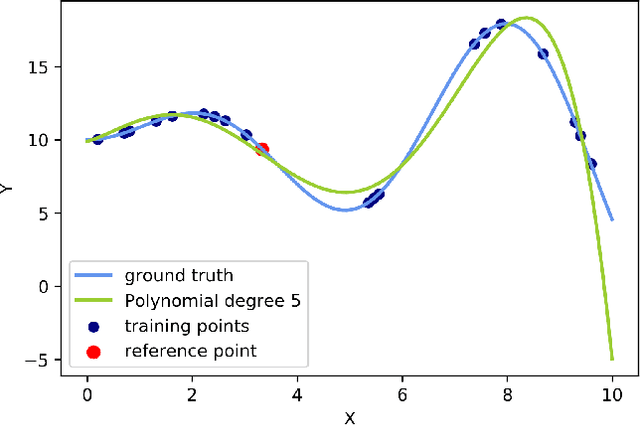
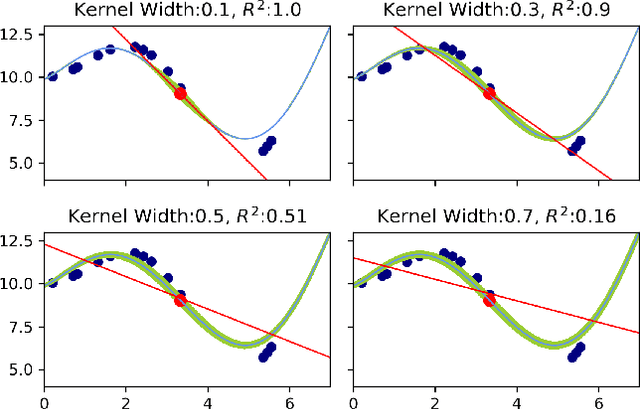
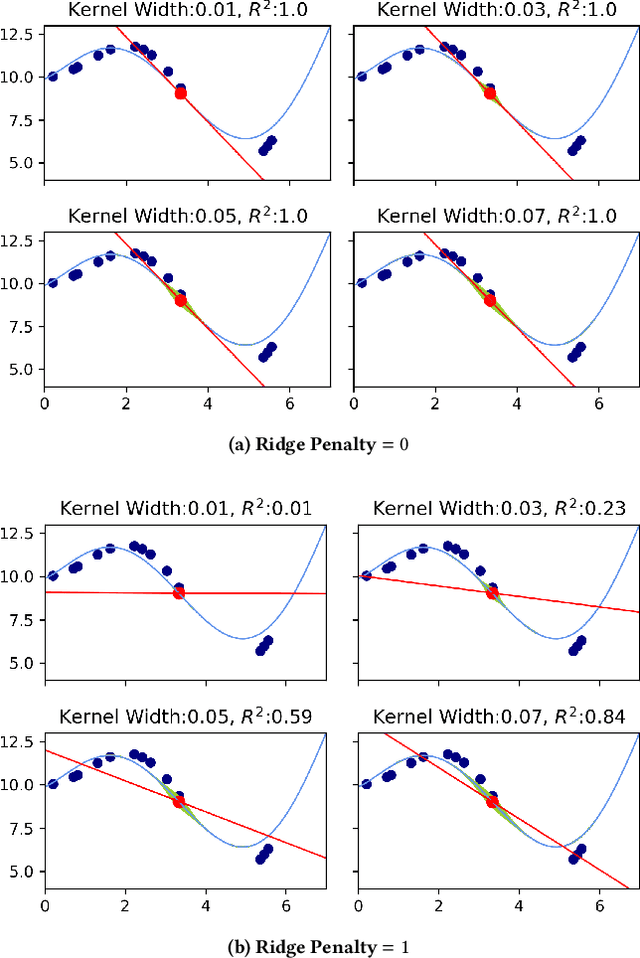
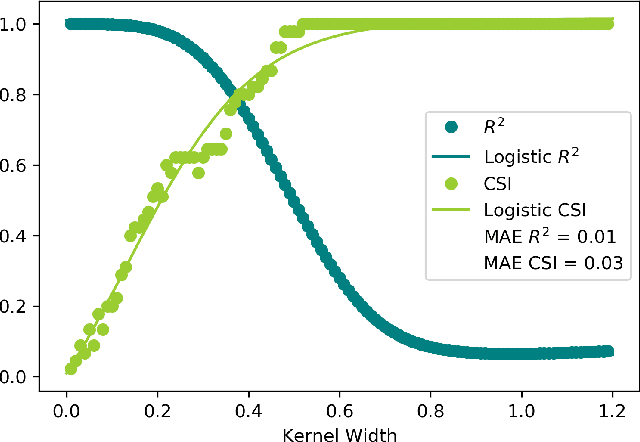
Local Interpretable Model-Agnostic Explanations (LIME) is a popular method to perform interpretability of any kind of Machine Learning (ML) model. It explains one ML prediction at a time, by learning a simple linear model around the prediction. The model is trained on randomly generated data points, sampled from the training dataset distribution and weighted according to the distance from the reference point - the one being explained by LIME. Feature selection is applied to keep only the most important variables. LIME is widespread across different domains, although its instability - a single prediction may obtain different explanations - is one of the major shortcomings. This is due to the randomness in the sampling step, as well as to the flexibility in tuning the weights and determines a lack of reliability in the retrieved explanations, making LIME adoption problematic. In Medicine especially, clinical professionals trust is mandatory to determine the acceptance of an explainable algorithm, considering the importance of the decisions at stake and the related legal issues. In this paper, we highlight a trade-off between explanation's stability and adherence, namely how much it resembles the ML model. Exploiting our innovative discovery, we propose a framework to maximise stability, while retaining a predefined level of adherence. OptiLIME provides freedom to choose the best adherence-stability trade-off level and more importantly, it clearly highlights the mathematical properties of the retrieved explanation. As a result, the practitioner is provided with tools to decide whether the explanation is reliable, according to the problem at hand. We extensively test OptiLIME on a toy dataset - to present visually the geometrical findings - and a medical dataset. In the latter, we show how the method comes up with meaningful explanations both from a medical and mathematical standpoint.
Statistical stability indices for LIME: obtaining reliable explanations for Machine Learning models
Jan 31, 2020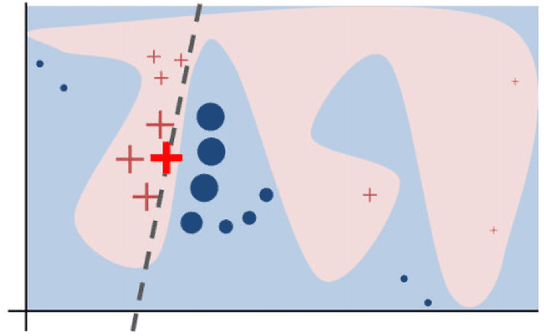

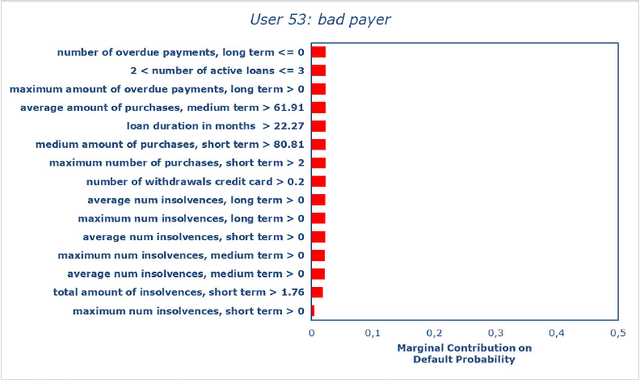
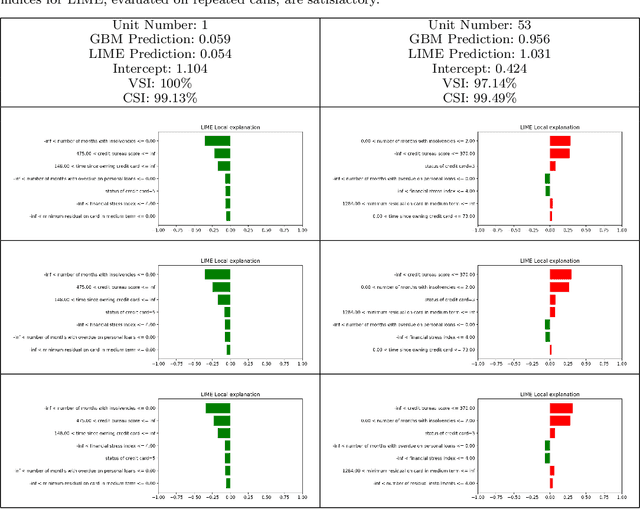
Nowadays we are witnessing a transformation of the business processes towards a more computation driven approach. The ever increasing usage of Machine Learning techniques is the clearest example of such trend. This sort of revolution is often providing advantages, such as an increase in prediction accuracy and a reduced time to obtain the results. However, these methods present a major drawback: it is very difficult to understand on what grounds the algorithm took the decision. To address this issue we consider the LIME method. We give a general background on LIME then, we focus on the stability issue: employing the method repeated times, under the same conditions, may yield to different explanations. Two complementary indices are proposed, to measure LIME stability. It is important for the practitioner to be aware of the issue, as well as to have a tool for spotting it. Stability guarantees LIME explanations to be reliable, therefore a stability assessment, made through the proposed indices, is crucial. As a case study, we apply both Machine Learning and classical statistical techniques to Credit Risk data. We test LIME on the Machine Learning algorithm and check its stability. Eventually, we examine the goodness of the explanations returned.
Abducing Compliance of Incomplete Event Logs
Jun 17, 2016
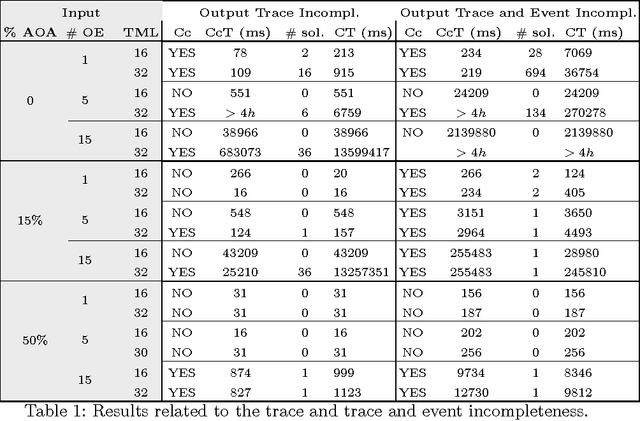
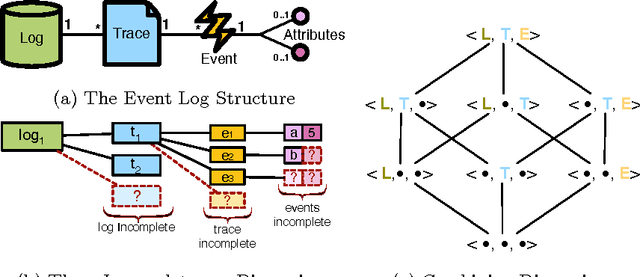
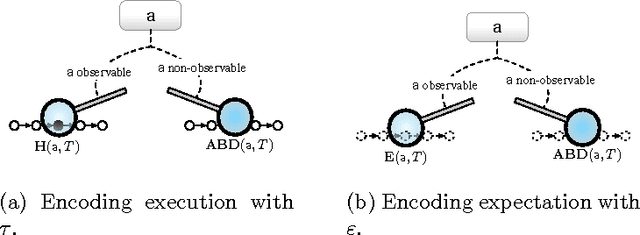
The capability to store data about business processes execution in so-called Event Logs has brought to the diffusion of tools for the analysis of process executions and for the assessment of the goodness of a process model. Nonetheless, these tools are often very rigid in dealing with with Event Logs that include incomplete information about the process execution. Thus, while the ability of handling incomplete event data is one of the challenges mentioned in the process mining manifesto, the evaluation of compliance of an execution trace still requires an end-to-end complete trace to be performed. This paper exploits the power of abduction to provide a flexible, yet computationally effective, framework to deal with different forms of incompleteness in an Event Log. Moreover it proposes a refinement of the classical notion of compliance into strong and conditional compliance to take into account incomplete logs. Finally, performances evaluation in an experimental setting shows the feasibility of the presented approach.
Multi-Criteria Optimal Planning for Energy Policies in CLP
May 15, 2014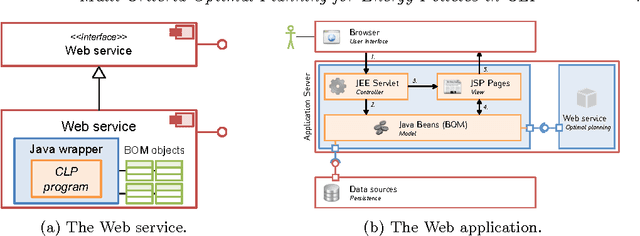
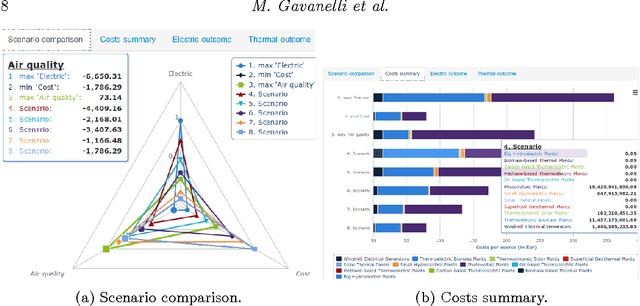
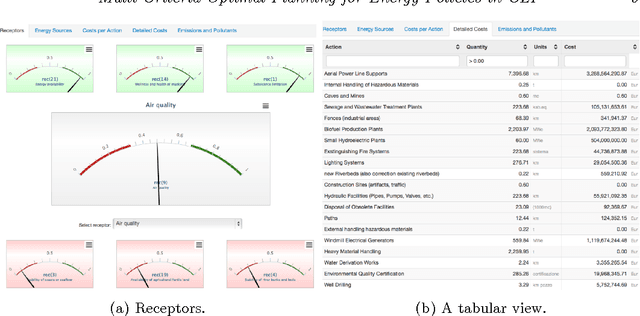
In the policy making process a number of disparate and diverse issues such as economic development, environmental aspects, as well as the social acceptance of the policy, need to be considered. A single person might not have all the required expertises, and decision support systems featuring optimization components can help to assess policies. Leveraging on previous work on Strategic Environmental Assessment, we developed a fully-fledged system that is able to provide optimal plans with respect to a given objective, to perform multi-objective optimization and provide sets of Pareto optimal plans, and to visually compare them. Each plan is environmentally assessed and its footprint is evaluated. The heart of the system is an application developed in a popular Constraint Logic Programming system on the Reals sort. It has been equipped with a web service module that can be queried through standard interfaces, and an intuitive graphic user interface.