 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanations of Machine Learning predictions: a mandatory step for its application to Operational Processes
Dec 30, 2020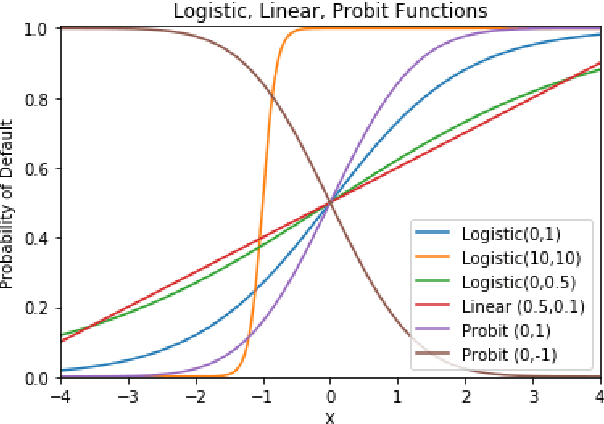
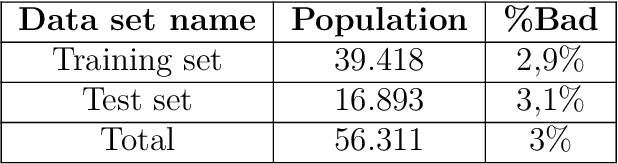
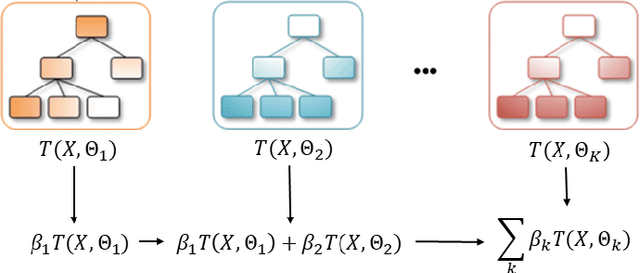
In the global economy, credit companies play a central role in economic development, through their activity as money lenders. This important task comes with some drawbacks, mainly the risk of the debtors not being able to repay the provided credit. Therefore, Credit Risk Modelling (CRM), namely the evaluation of the probability that a debtor will not repay the due amount, plays a paramount role. Statistical approaches have been successfully exploited since long, becoming the most used methods for CRM. Recently, also machine and deep learning techniques have been applied to the CRM task, showing an important increase in prediction quality and performances. However, such techniques usually do not provide reliable explanations for the scores they come up with. As a consequence, many machine and deep learning techniques fail to comply with western countries' regulations such as, for example, GDPR. In this paper we suggest to use LIME (Local Interpretable Model-agnostic Explanations) technique to tackle the explainability problem in this field, we show its employment on a real credit-risk dataset and eventually discuss its soundness and the necessary improvements to guarantee its adoption and compliance with the task.
Statistical stability indices for LIME: obtaining reliable explanations for Machine Learning models
Jan 31, 2020

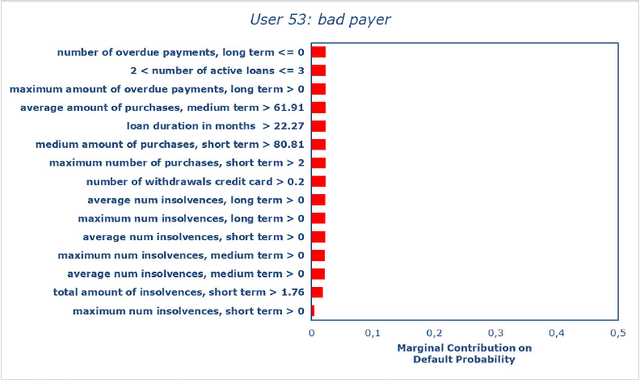
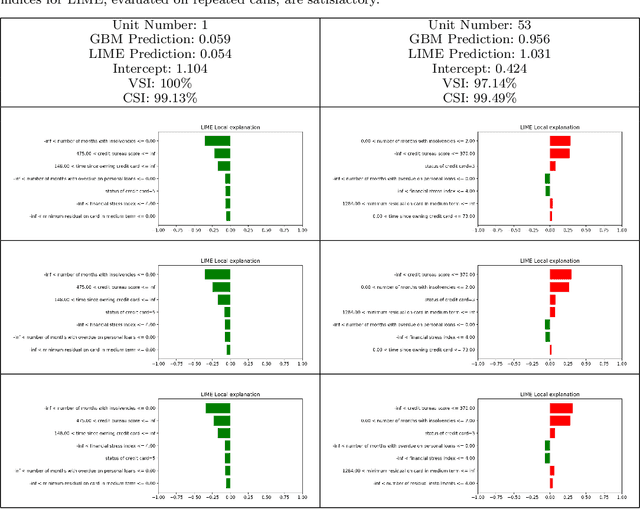
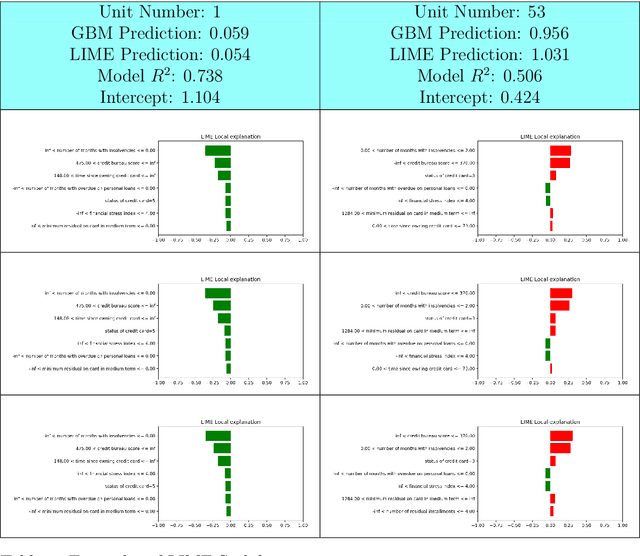
Nowadays we are witnessing a transformation of the business processes towards a more computation driven approach. The ever increasing usage of Machine Learning techniques is the clearest example of such trend. This sort of revolution is often providing advantages, such as an increase in prediction accuracy and a reduced time to obtain the results. However, these methods present a major drawback: it is very difficult to understand on what grounds the algorithm took the decision. To address this issue we consider the LIME method. We give a general background on LIME then, we focus on the stability issue: employing the method repeated times, under the same conditions, may yield to different explanations. Two complementary indices are proposed, to measure LIME stability. It is important for the practitioner to be aware of the issue, as well as to have a tool for spotting it. Stability guarantees LIME explanations to be reliable, therefore a stability assessment, made through the proposed indices, is crucial. As a case study, we apply both Machine Learning and classical statistical techniques to Credit Risk data. We test LIME on the Machine Learning algorithm and check its stability. Eventually, we examine the goodness of the explanations returned.