 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Credit Risk Estimates in the Gen-AI Era
Jun 09, 2025Generative AI technologies have demonstrated significant potential across diverse applications. This study provides a comparative analysis of credit score modeling techniques, contrasting traditional approaches with those leveraging generative AI. Our findings reveal that current generative AI models fall short of matching the performance of traditional methods, regardless of the integration strategy employed. These results highlight the limitations in the current capabilities of generative AI for credit risk scoring, emphasizing the need for further research and development before the possibility of applying generative AI for this specific task, or equivalent ones.
Evaluating AI fairness in credit scoring with the BRIO tool
Jun 05, 2024



We present a method for quantitative, in-depth analyses of fairness issues in AI systems with an application to credit scoring. To this aim we use BRIO, a tool for the evaluation of AI systems with respect to social unfairness and, more in general, ethically undesirable behaviours. It features a model-agnostic bias detection module, presented in \cite{DBLP:conf/beware/CoragliaDGGPPQ23}, to which a full-fledged unfairness risk evaluation module is added. As a case study, we focus on the context of credit scoring, analysing the UCI German Credit Dataset \cite{misc_statlog_(german_credit_data)_144}. We apply the BRIO fairness metrics to several, socially sensitive attributes featured in the German Credit Dataset, quantifying fairness across various demographic segments, with the aim of identifying potential sources of bias and discrimination in a credit scoring model. We conclude by combining our results with a revenue analysis.
Enabling Synthetic Data adoption in regulated domains
Apr 13, 2022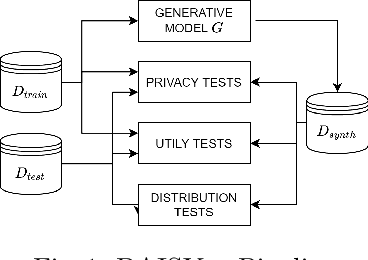
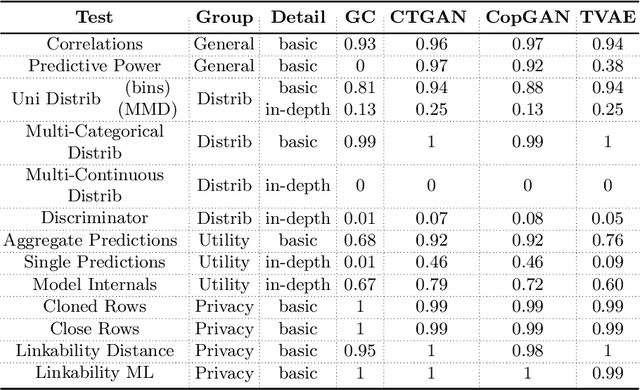
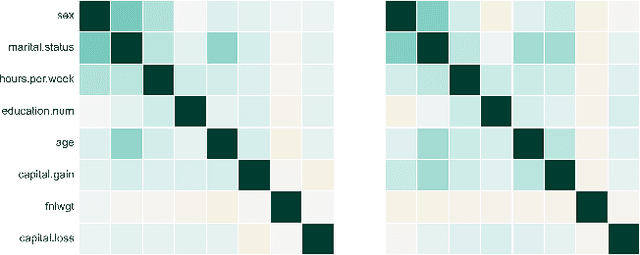

The switch from a Model-Centric to a Data-Centric mindset is putting emphasis on data and its quality rather than algorithms, bringing forward new challenges. In particular, the sensitive nature of the information in highly regulated scenarios needs to be accounted for. Specific approaches to address the privacy issue have been developed, as Privacy Enhancing Technologies. However, they frequently cause loss of information, putting forward a crucial trade-off among data quality and privacy. A clever way to bypass such a conundrum relies on Synthetic Data: data obtained from a generative process, learning the real data properties. Both Academia and Industry realized the importance of evaluating synthetic data quality: without all-round reliable metrics, the innovative data generation task has no proper objective function to maximize. Despite that, the topic remains under-explored. For this reason, we systematically catalog the important traits of synthetic data quality and privacy, and devise a specific methodology to test them. The result is DAISYnt (aDoption of Artificial Intelligence SYnthesis): a comprehensive suite of advanced tests, which sets a de facto standard for synthetic data evaluation. As a practical use-case, a variety of generative algorithms have been trained on real-world Credit Bureau Data. The best model has been assessed, using DAISYnt on the different synthetic replicas. Further potential uses, among others, entail auditing and fine-tuning of generative models or ensuring high quality of a given synthetic dataset. From a prescriptive viewpoint, eventually, DAISYnt may pave the way to synthetic data adoption in highly regulated domains, ranging from Finance to Healthcare, through Insurance and Education.
Explanations of Machine Learning predictions: a mandatory step for its application to Operational Processes
Dec 30, 2020
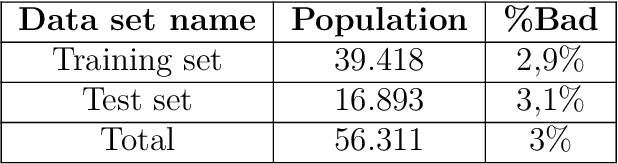
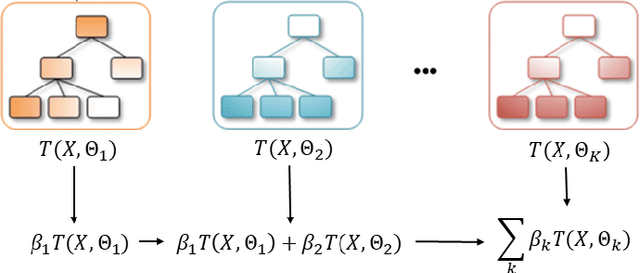
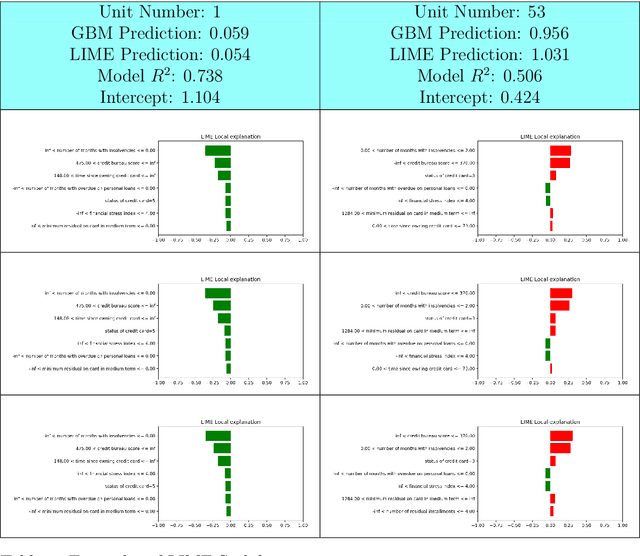
In the global economy, credit companies play a central role in economic development, through their activity as money lenders. This important task comes with some drawbacks, mainly the risk of the debtors not being able to repay the provided credit. Therefore, Credit Risk Modelling (CRM), namely the evaluation of the probability that a debtor will not repay the due amount, plays a paramount role. Statistical approaches have been successfully exploited since long, becoming the most used methods for CRM. Recently, also machine and deep learning techniques have been applied to the CRM task, showing an important increase in prediction quality and performances. However, such techniques usually do not provide reliable explanations for the scores they come up with. As a consequence, many machine and deep learning techniques fail to comply with western countries' regulations such as, for example, GDPR. In this paper we suggest to use LIME (Local Interpretable Model-agnostic Explanations) technique to tackle the explainability problem in this field, we show its employment on a real credit-risk dataset and eventually discuss its soundness and the necessary improvements to guarantee its adoption and compliance with the task.
PSD2 Explainable AI Model for Credit Scoring
Nov 26, 2020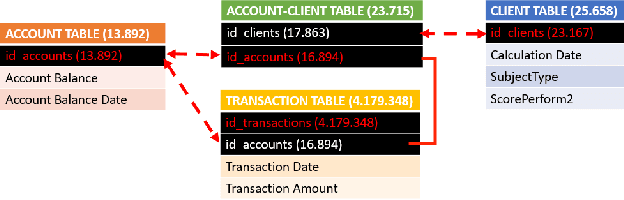
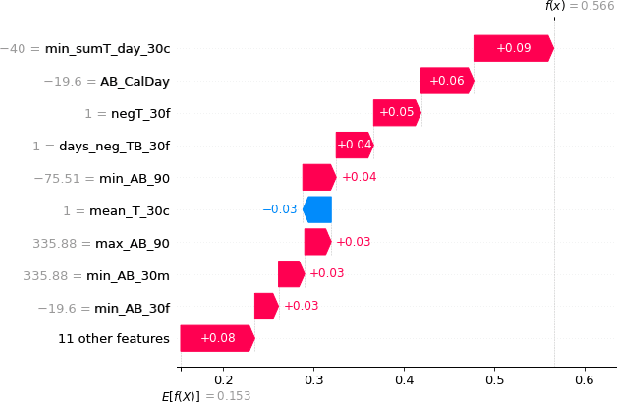
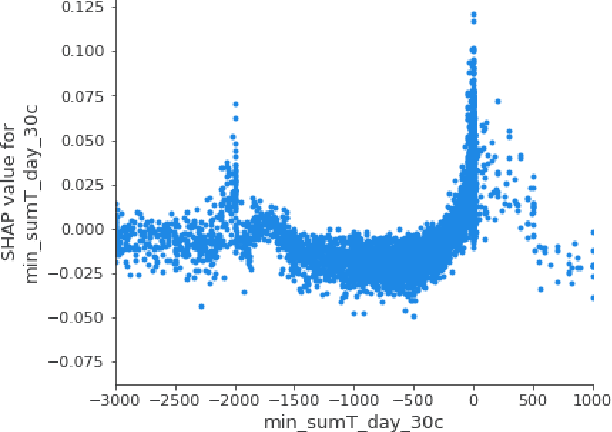

The aim of this paper is to develop and test advanced analytical methods to improve the prediction accuracy of Credit Risk Models, preserving at the same time the model interpretability. In particular, the project focuses on applying an explainable machine learning model to PSD2-related databases. The input data were obtained solely from synthetic account transactions generated from a pool of commercial banks from a pool of Italian commercial banks. Over the total proven models, CatBoost has shown the highest performance. The algorithm implementation produces a GINI of 0.45 after tuning the hyper-parameters combined with their inherent class-weight resampling method. SHAP package is used to provide a global and local interpretation of the model predictions to formulate a human-comprehensive approach to understanding the decision-maker algorithm. The 20 most important features are selected using the Shapley values to present a full human-understandable model that reveals how the attributes of an individual are related to its model prediction.
Metrics for Multi-Class Classification: an Overview
Aug 13, 2020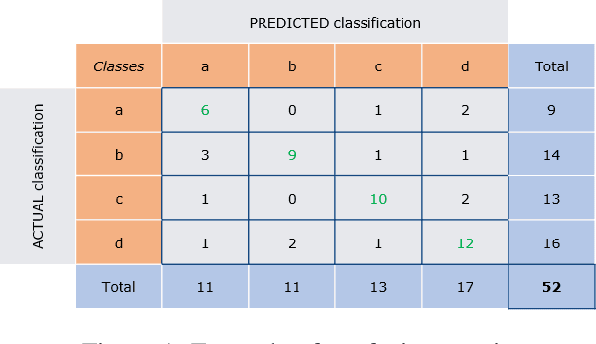
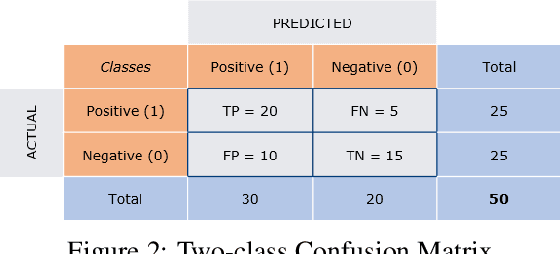
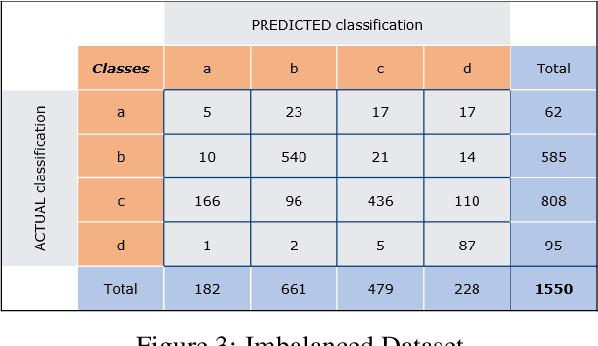

Classification tasks in machine learning involving more than two classes are known by the name of "multi-class classification". Performance indicators are very useful when the aim is to evaluate and compare different classification models or machine learning techniques. Many metrics come in handy to test the ability of a multi-class classifier. Those metrics turn out to be useful at different stage of the development process, e.g. comparing the performance of two different models or analysing the behaviour of the same model by tuning different parameters. In this white paper we review a list of the most promising multi-class metrics, we highlight their advantages and disadvantages and show their possible usages during the development of a classification model.
OptiLIME: Optimized LIME Explanations for Diagnostic Computer Algorithms
Jun 10, 2020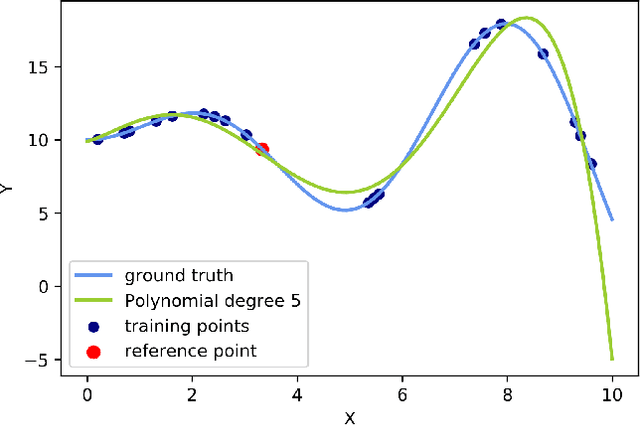
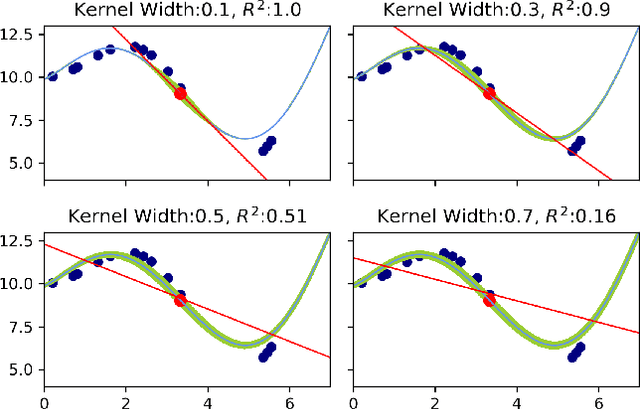
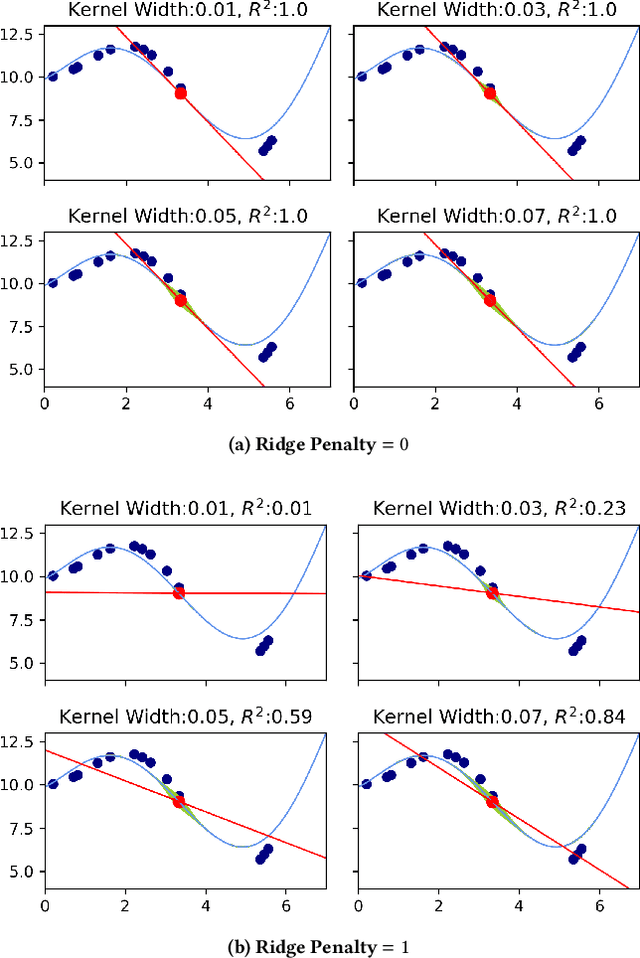
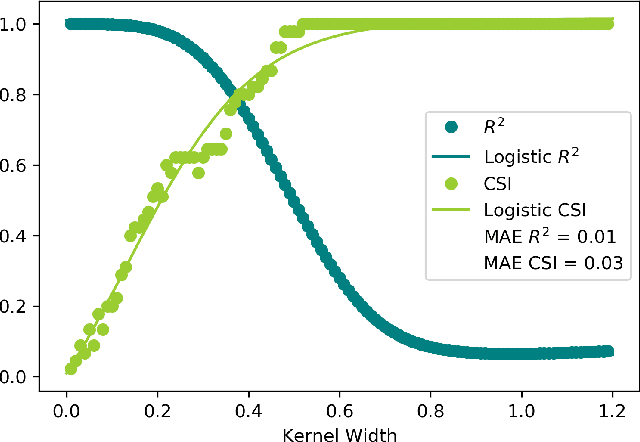
Local Interpretable Model-Agnostic Explanations (LIME) is a popular method to perform interpretability of any kind of Machine Learning (ML) model. It explains one ML prediction at a time, by learning a simple linear model around the prediction. The model is trained on randomly generated data points, sampled from the training dataset distribution and weighted according to the distance from the reference point - the one being explained by LIME. Feature selection is applied to keep only the most important variables. LIME is widespread across different domains, although its instability - a single prediction may obtain different explanations - is one of the major shortcomings. This is due to the randomness in the sampling step, as well as to the flexibility in tuning the weights and determines a lack of reliability in the retrieved explanations, making LIME adoption problematic. In Medicine especially, clinical professionals trust is mandatory to determine the acceptance of an explainable algorithm, considering the importance of the decisions at stake and the related legal issues. In this paper, we highlight a trade-off between explanation's stability and adherence, namely how much it resembles the ML model. Exploiting our innovative discovery, we propose a framework to maximise stability, while retaining a predefined level of adherence. OptiLIME provides freedom to choose the best adherence-stability trade-off level and more importantly, it clearly highlights the mathematical properties of the retrieved explanation. As a result, the practitioner is provided with tools to decide whether the explanation is reliable, according to the problem at hand. We extensively test OptiLIME on a toy dataset - to present visually the geometrical findings - and a medical dataset. In the latter, we show how the method comes up with meaningful explanations both from a medical and mathematical standpoint.
Statistical stability indices for LIME: obtaining reliable explanations for Machine Learning models
Jan 31, 2020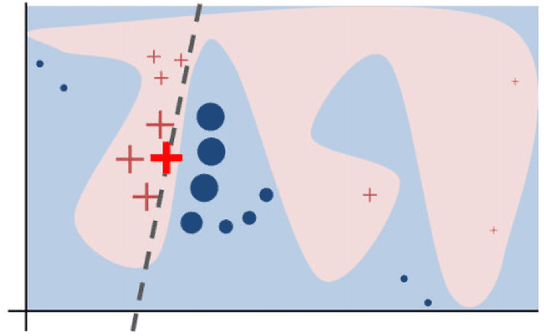

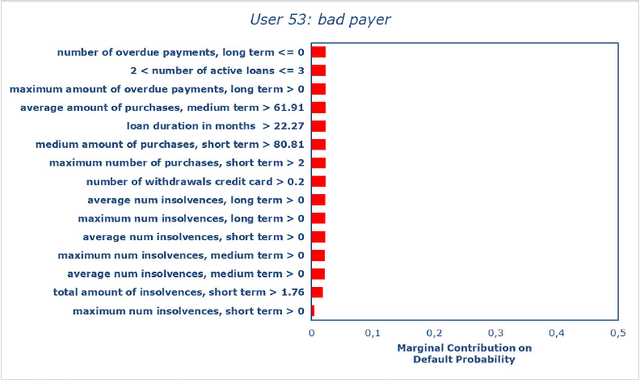
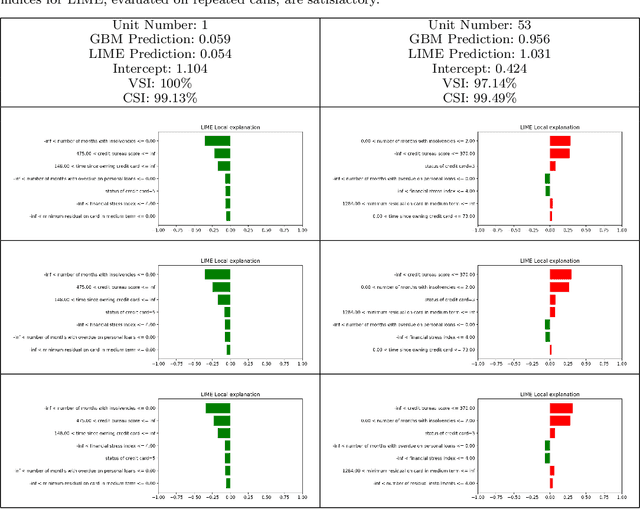
Nowadays we are witnessing a transformation of the business processes towards a more computation driven approach. The ever increasing usage of Machine Learning techniques is the clearest example of such trend. This sort of revolution is often providing advantages, such as an increase in prediction accuracy and a reduced time to obtain the results. However, these methods present a major drawback: it is very difficult to understand on what grounds the algorithm took the decision. To address this issue we consider the LIME method. We give a general background on LIME then, we focus on the stability issue: employing the method repeated times, under the same conditions, may yield to different explanations. Two complementary indices are proposed, to measure LIME stability. It is important for the practitioner to be aware of the issue, as well as to have a tool for spotting it. Stability guarantees LIME explanations to be reliable, therefore a stability assessment, made through the proposed indices, is crucial. As a case study, we apply both Machine Learning and classical statistical techniques to Credit Risk data. We test LIME on the Machine Learning algorithm and check its stability. Eventually, we examine the goodness of the explanations returned.