 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthiness Preservation by Copies of Machine Learning Systems
Jun 05, 2025A common practice of ML systems development concerns the training of the same model under different data sets, and the use of the same (training and test) sets for different learning models. The first case is a desirable practice for identifying high quality and unbiased training conditions. The latter case coincides with the search for optimal models under a common dataset for training. These differently obtained systems have been considered akin to copies. In the quest for responsible AI, a legitimate but hardly investigated question is how to verify that trustworthiness is preserved by copies. In this paper we introduce a calculus to model and verify probabilistic complex queries over data and define four distinct notions: Justifiably, Equally, Weakly and Almost Trustworthy which can be checked analysing the (partial) behaviour of the copy with respect to its original. We provide a study of the relations between these notions of trustworthiness, and how they compose with each other and under logical operations. The aim is to offer a computational tool to check the trustworthiness of possibly complex systems copied from an original whose behavour is known.
Evaluating AI fairness in credit scoring with the BRIO tool
Jun 05, 2024



We present a method for quantitative, in-depth analyses of fairness issues in AI systems with an application to credit scoring. To this aim we use BRIO, a tool for the evaluation of AI systems with respect to social unfairness and, more in general, ethically undesirable behaviours. It features a model-agnostic bias detection module, presented in \cite{DBLP:conf/beware/CoragliaDGGPPQ23}, to which a full-fledged unfairness risk evaluation module is added. As a case study, we focus on the context of credit scoring, analysing the UCI German Credit Dataset \cite{misc_statlog_(german_credit_data)_144}. We apply the BRIO fairness metrics to several, socially sensitive attributes featured in the German Credit Dataset, quantifying fairness across various demographic segments, with the aim of identifying potential sources of bias and discrimination in a credit scoring model. We conclude by combining our results with a revenue analysis.
Data quality dimensions for fair AI
May 11, 2023AI systems are not intrinsically neutral and biases trickle in any type of technological tool. In particular when dealing with people, AI algorithms reflect technical errors originating with mislabeled data. As they feed wrong and discriminatory classifications, perpetuating structural racism and marginalization, these systems are not systematically guarded against bias. In this article we consider the problem of bias in AI systems from the point of view of Information Quality dimensions. We illustrate potential improvements of a bias mitigation tool in gender classification errors, referring to two typically difficult contexts: the classification of non-binary individuals and the classification of transgender individuals. The identification of data quality dimensions to implement in bias mitigation tool may help achieve more fairness. Hence, we propose to consider this issue in terms of completeness, consistency, timeliness and reliability, and offer some theoretical results.
Checking Trustworthiness of Probabilistic Computations in a Typed Natural Deduction System
Jun 26, 2022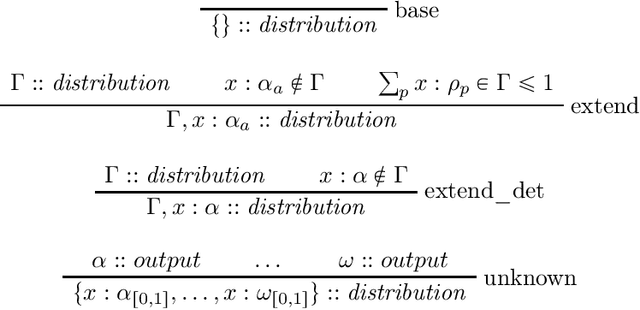


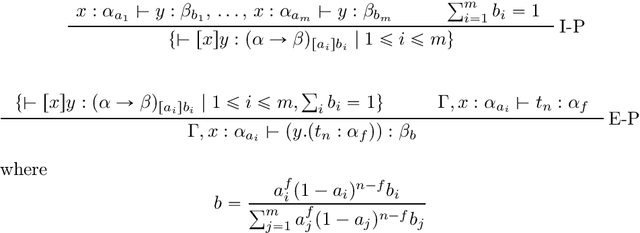
In this paper we present the probabilistic typed natural deduction calculus TPTND, designed to reason about and derive trustworthiness properties of probabilistic computational processes, like those underlying current AI applications. Derivability in TPTND is interpreted as the process of extracting $n$ samples of outputs with a certain frequency from a given categorical distribution. We formalize trust within our framework as a form of hypothesis testing on the distance between such frequency and the intended probability. The main advantage of the calculus is to render such notion of trustworthiness checkable. We present the proof-theoretic semantics of TPTND and illustrate structural and metatheoretical properties, with particular focus on safety. We motivate its use in the verification of algorithms for automatic classification.