 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSD2 Explainable AI Model for Credit Scoring
Paper and Code
Nov 26, 2020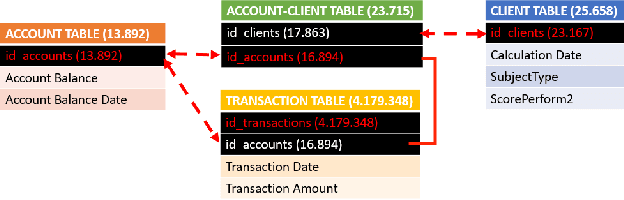
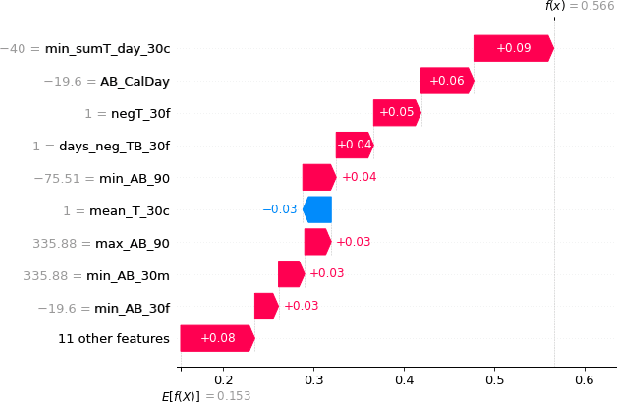
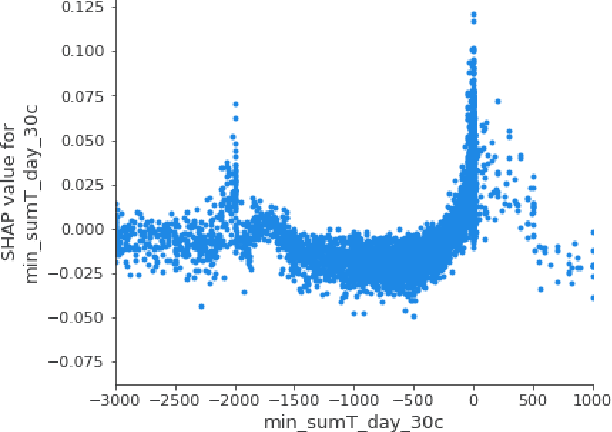

The aim of this paper is to develop and test advanced analytical methods to improve the prediction accuracy of Credit Risk Models, preserving at the same time the model interpretability. In particular, the project focuses on applying an explainable machine learning model to PSD2-related databases. The input data were obtained solely from synthetic account transactions generated from a pool of commercial banks from a pool of Italian commercial banks. Over the total proven models, CatBoost has shown the highest performance. The algorithm implementation produces a GINI of 0.45 after tuning the hyper-parameters combined with their inherent class-weight resampling method. SHAP package is used to provide a global and local interpretation of the model predictions to formulate a human-comprehensive approach to understanding the decision-maker algorithm. The 20 most important features are selected using the Shapley values to present a full human-understandable model that reveals how the attributes of an individual are related to its model prediction.