 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Algebra and Calculus with SQL Null Values
Feb 22, 2022



The logic of nulls in databases has been subject of investigation since their introduction in Codd's Relational Model, which is the foundation of the SQL standard. We show a logical characterisation of a first-order fragment of SQL with null values, by first focussing on a simple extension with null values of standard relational algebra, which captures exactly the SQL fragment, and then proposing two different domain relational calculi, in which the null value is a term of the language but it does not appear as an element of the semantic interpretation domain of the logics. In one calculus, a relation can be seen as a set of partial tuples, while in the other (equivalent) calculus, a relation is horizontally decomposed as a set of relations each one holding regular total tuples. We extend Codd's theorem by proving the equivalence of the relational algebra with both domain relational calculi in presence of SQL null values.
Process discovery on deviant traces and other stranger things
Sep 30, 2021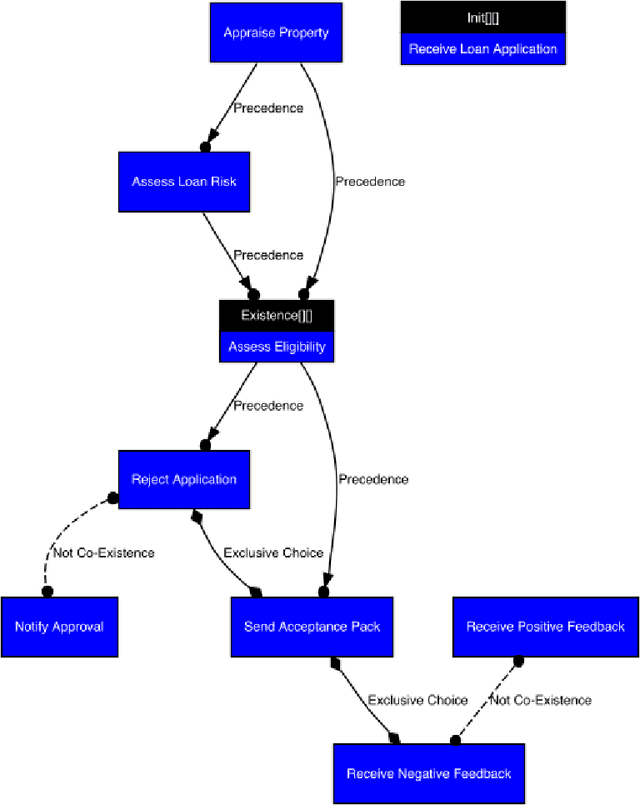
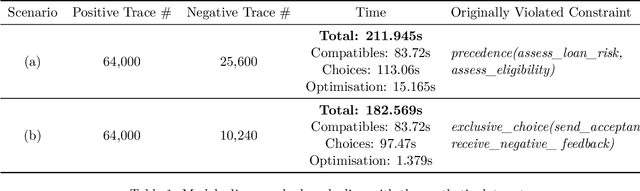
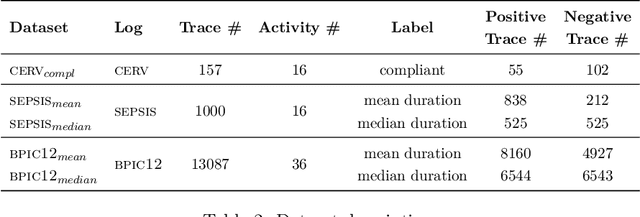

As the need to understand and formalise business processes into a model has grown over the last years, the process discovery research field has gained more and more importance, developing two different classes of approaches to model representation: procedural and declarative. Orthogonally to this classification, the vast majority of works envisage the discovery task as a one-class supervised learning process guided by the traces that are recorded into an input log. In this work instead, we focus on declarative processes and embrace the less-popular view of process discovery as a binary supervised learning task, where the input log reports both examples of the normal system execution, and traces representing "stranger" behaviours according to the domain semantics. We therefore deepen how the valuable information brought by both these two sets can be extracted and formalised into a model that is "optimal" according to user-defined goals. Our approach, namely NegDis, is evaluated w.r.t. other relevant works in this field, and shows promising results as regards both the performance and the quality of the obtained solution.
Verification of data-aware workflows via reachability: formalisation and experiments
Sep 27, 2019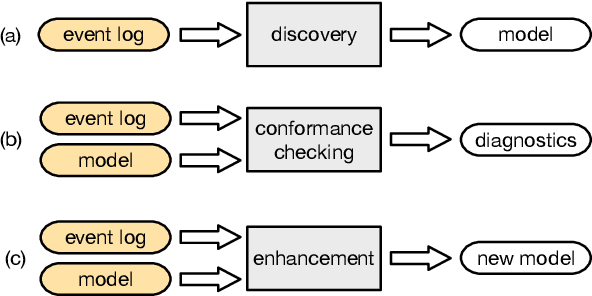
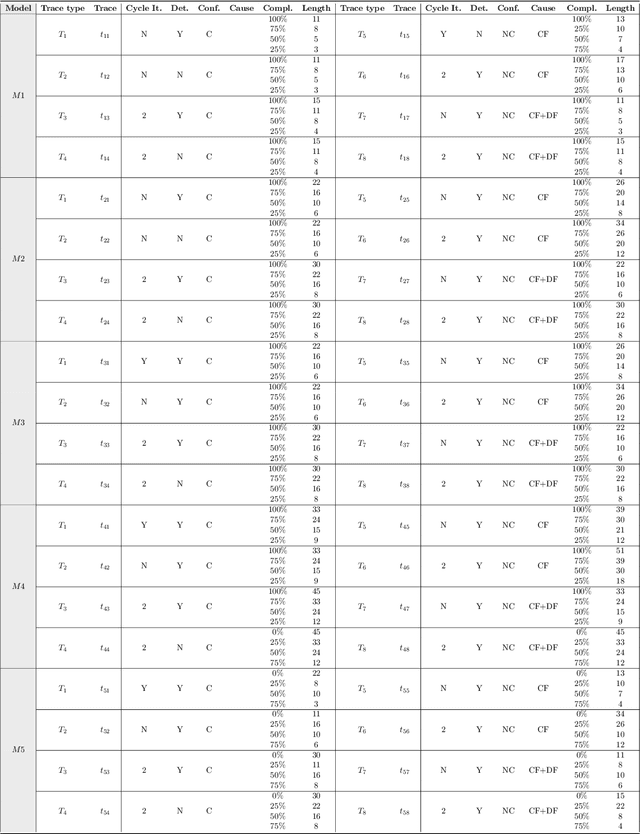
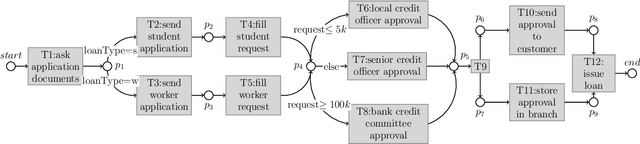

The growing adoption of IT-systems for the modelling and execution of (business) processes or services has thrust the scientific investigation towards techniques and tools which support complex forms of process analysis. These techniques rely on observation of past (tracked and logged) process executions but typically: (i) only consider activities, lacking the ability to take into account the data objects manipulated by these activities and (ii) assume complete observations of terminated process executions. In many real cases, however, only incomplete log information is available. This paper tackles these two shortcomings by proposing an approach to exploit reachability to reason on imperative data-aware process models and possibly incomplete process executions. The contribution of this paper is twofold: first, it formulates the trace completion as a reachability problem over data-aware models and second, it provides a rigorous mapping between our data-aware models and three important paradigms for reasoning about dynamic systems, namely Action Languages, Classical Planning, and Model-Checking. This allows us to exploit and extensively evaluate the available tools for the above paradigms to solve the trace repair problem. The rigorous encoding of our data-aware models, based on a common interpretation of the semantics of Action Languages, Classical Planning, and Model-Checking in terms of transition systems, paired with a first comprehensive assessment of the performances of their tools in computing reachability for data-aware workflow net languages, provide a solid contribution to advancing the state-of-the-art on the concrete exploitation of formal verification techniques on business processes.
Enhancing workflow-nets with data for trace completion
Jun 01, 2017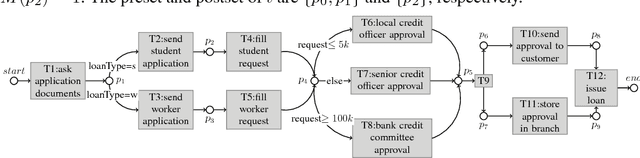
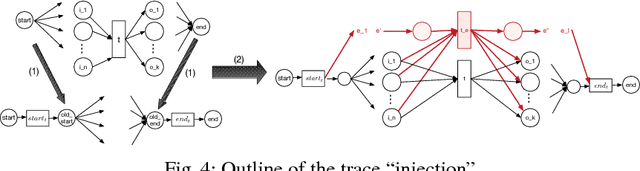
The growing adoption of IT-systems for modeling and executing (business) processes or services has thrust the scientific investigation towards techniques and tools which support more complex forms of process analysis. Many of them, such as conformance checking, process alignment, mining and enhancement, rely on complete observation of past (tracked and logged) executions. In many real cases, however, the lack of human or IT-support on all the steps of process execution, as well as information hiding and abstraction of model and data, result in incomplete log information of both data and activities. This paper tackles the issue of automatically repairing traces with missing information by notably considering not only activities but also data manipulated by them. Our technique recasts such a problem in a reachability problem and provides an encoding in an action language which allows to virtually use any state-of-the-art planning to return solutions.
Abducing Compliance of Incomplete Event Logs
Jun 17, 2016
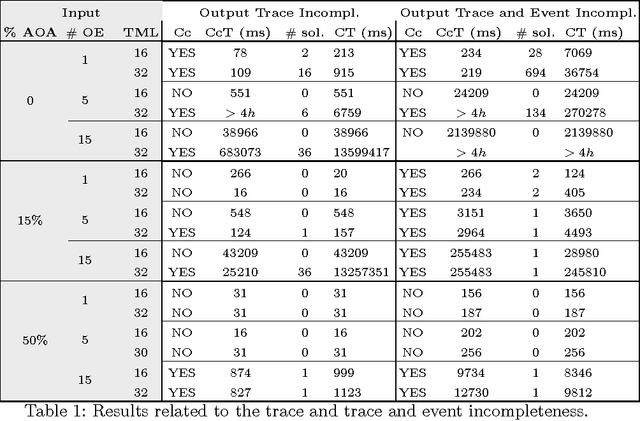
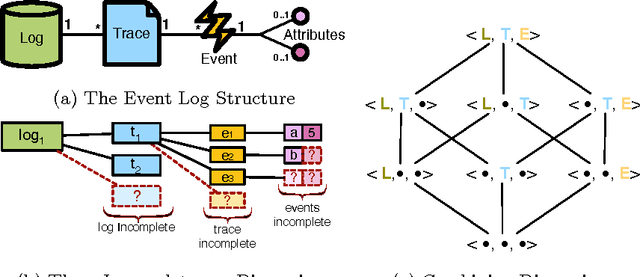
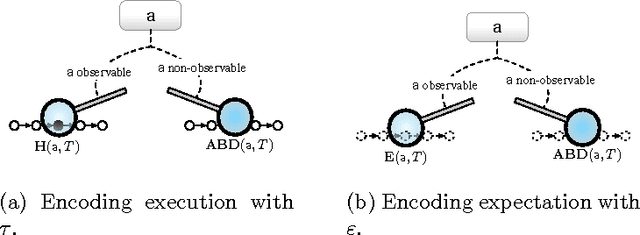
The capability to store data about business processes execution in so-called Event Logs has brought to the diffusion of tools for the analysis of process executions and for the assessment of the goodness of a process model. Nonetheless, these tools are often very rigid in dealing with with Event Logs that include incomplete information about the process execution. Thus, while the ability of handling incomplete event data is one of the challenges mentioned in the process mining manifesto, the evaluation of compliance of an execution trace still requires an end-to-end complete trace to be performed. This paper exploits the power of abduction to provide a flexible, yet computationally effective, framework to deal with different forms of incompleteness in an Event Log. Moreover it proposes a refinement of the classical notion of compliance into strong and conditional compliance to take into account incomplete logs. Finally, performances evaluation in an experimental setting shows the feasibility of the presented approach.