Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelizing Machine Learning as a Service for the End-User
Paper and Code
May 29, 2020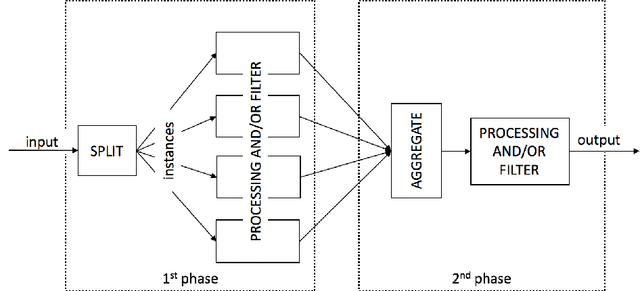
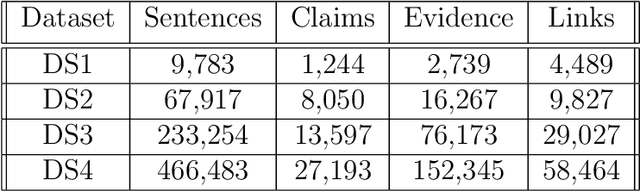

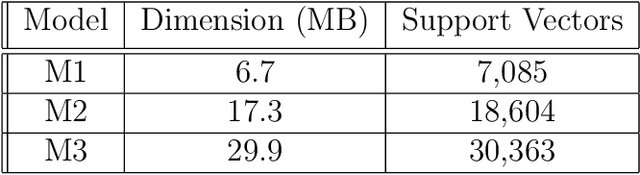
As ML applications are becoming ever more pervasive, fully-trained systems are made increasingly available to a wide public, allowing end-users to submit queries with their own data, and to efficiently retrieve results. With increasingly sophisticated such services, a new challenge is how to scale up to evergrowing user bases. In this paper, we present a distributed architecture that could be exploited to parallelize a typical ML system pipeline. We propose a case study consisting of a text mining service and discuss how the method can be generalized to many similar applications. We demonstrate the significance of the computational gain boosted by the distributed architecture by way of an extensive experimental evaluation.
* Future Generation Computer Systems 105 (2020) 275-286
View paper on