 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe QXS-SAROPT Dataset for Deep Learning in SAR-Optical Data Fusion
Mar 15, 2021Deep learning techniques have made an increasing impact on the field of remote sensing. However, deep neural networks based fusion of multimodal data from different remote sensors with heterogenous characteristics has not been fully explored, due to the lack of availability of big amounts of perfectly aligned multi-sensor image data with diverse scenes of high resolution, especially for synthetic aperture radar (SAR) data and optical imagery. In this paper, we publish the QXS-SAROPT dataset to foster deep learning research in SAR-optical data fusion. QXS-SAROPT comprises 20,000 pairs of corresponding image patches, collected from three port cities: San Diego, Shanghai and Qingdao acquired by the SAR satellite GaoFen-3 and optical satellites of Google Earth. Besides a detailed description of the dataset, we show exemplary results for two representative applications, namely SAR-optical image matching and SAR ship detection boosted by cross-modal information from optical images. Since QXS-SAROPT is a large open dataset with multiple scenes of the highest resolution of this kind, we believe it will support further developments in the field of deep learning based SAR-optical data fusion for remote sensing.
Boosting ship detection in SAR images with complementary pretraining techniques
Mar 15, 2021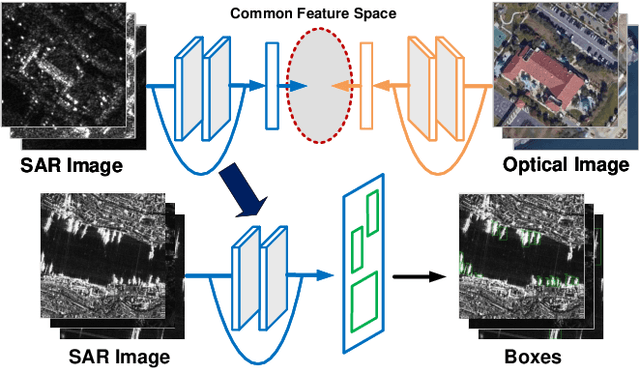
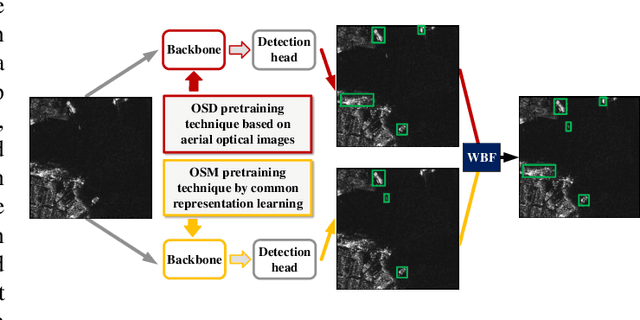
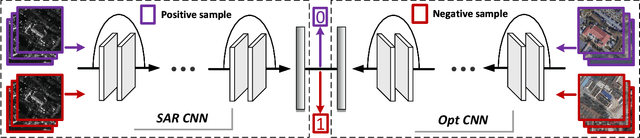
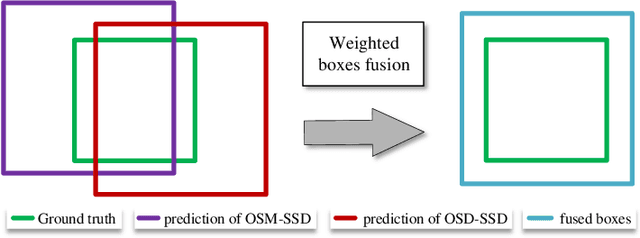
Deep learning methods have made significant progress in ship detection in synthetic aperture radar (SAR) images. The pretraining technique is usually adopted to support deep neural networks-based SAR ship detectors due to the scarce labeled SAR images. However, directly leveraging ImageNet pretraining is hardly to obtain a good ship detector because of different imaging perspective and geometry. In this paper, to resolve the problem of inconsistent imaging perspective between ImageNet and earth observations, we propose an optical ship detector (OSD) pretraining technique, which transfers the characteristics of ships in earth observations to SAR images from a large-scale aerial image dataset. On the other hand, to handle the problem of different imaging geometry between optical and SAR images, we propose an optical-SAR matching (OSM) pretraining technique, which transfers plentiful texture features from optical images to SAR images by common representation learning on the optical-SAR matching task. Finally, observing that the OSD pretraining based SAR ship detector has a better recall on sea area while the OSM pretraining based SAR ship detector can reduce false alarms on land area, we combine the predictions of the two detectors through weighted boxes fusion to further improve detection results. Extensive experiments on four SAR ship detection datasets and two representative CNN-based detection benchmarks are conducted to show the effectiveness and complementarity of the two proposed detectors, and the state-of-the-art performance of the combination of the two detectors. The proposed method won the sixth place of ship detection in SAR images in 2020 Gaofen challenge.
Training few-shot classification via the perspective of minibatch and pretraining
Apr 10, 2020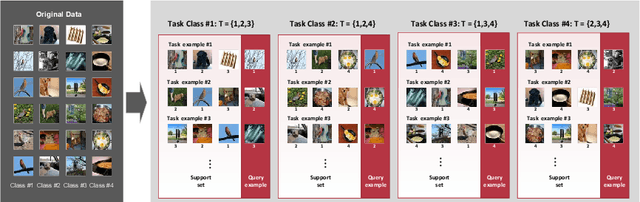

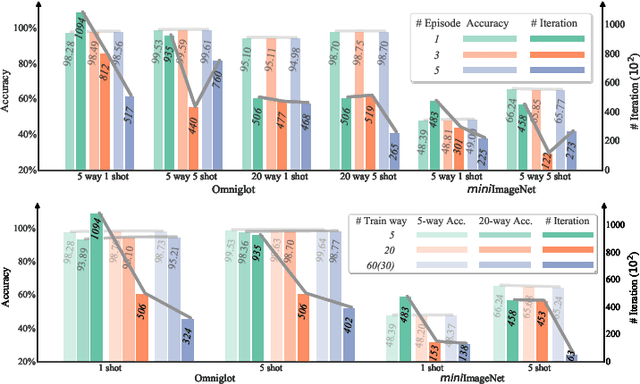
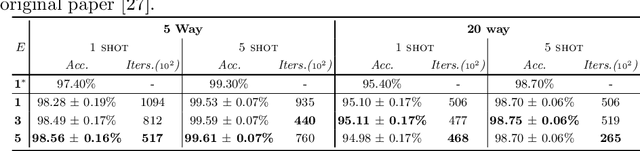
Few-shot classification is a challenging task which aims to formulate the ability of humans to learn concepts from limited prior data and has drawn considerable attention in machine learning. Recent progress in few-shot classification has featured meta-learning, in which a parameterized model for a learning algorithm is defined and trained to learn the ability of handling classification tasks on extremely large or infinite episodes representing different classification task, each with a small labeled support set and its corresponding query set. In this work, we advance this few-shot classification paradigm by formulating it as a supervised classification learning problem. We further propose multi-episode and cross-way training techniques, which respectively correspond to the minibatch and pretraining in classification problems. Experimental results on a state-of-the-art few-shot classification method (prototypical networks) demonstrate that both the proposed training strategies can highly accelerate the training process without accuracy loss for varying few-shot classification problems on Omniglot and miniImageNet.
Transfer Learning with Dynamic Adversarial Adaptation Network
Sep 18, 2019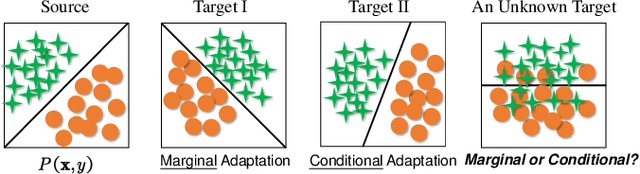
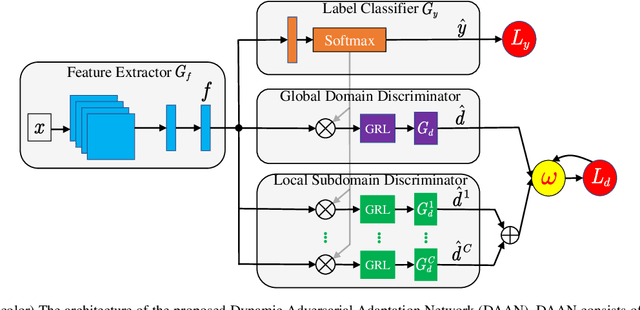

The recent advances in deep transfer learning reveal that adversarial learning can be embedded into deep networks to learn more transferable features to reduce the distribution discrepancy between two domains. Existing adversarial domain adaptation methods either learn a single domain discriminator to align the global source and target distributions or pay attention to align subdomains based on multiple discriminators. However, in real applications, the marginal (global) and conditional (local) distributions between domains are often contributing differently to the adaptation. There is currently no method to dynamically and quantitatively evaluate the relative importance of these two distributions for adversarial learning. In this paper, we propose a novel Dynamic Adversarial Adaptation Network (DAAN) to dynamically learn domain-invariant representations while quantitatively evaluate the relative importance of global and local domain distributions. To the best of our knowledge, DAAN is the first attempt to perform dynamic adversarial distribution adaptation for deep adversarial learning. DAAN is extremely easy to implement and train in real applications. We theoretically analyze the effectiveness of DAAN, and it can also be explained in an attention strategy. Extensive experiments demonstrate that DAAN achieves better classification accuracy compared to state-of-the-art deep and adversarial methods. Results also imply the necessity and effectiveness of the dynamic distribution adaptation in adversarial transfer learning.
Transfer Learning with Dynamic Distribution Adaptation
Sep 17, 2019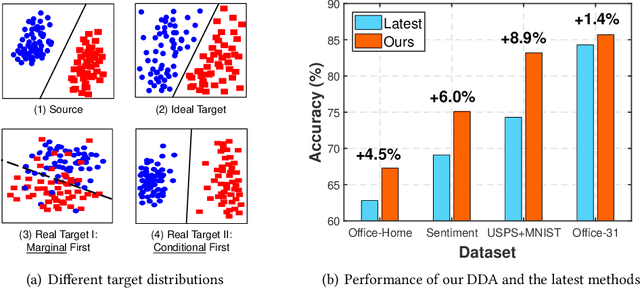
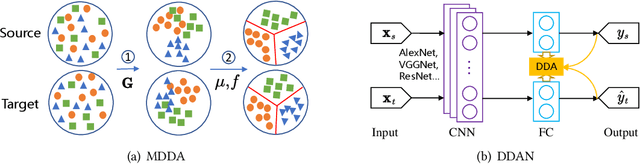

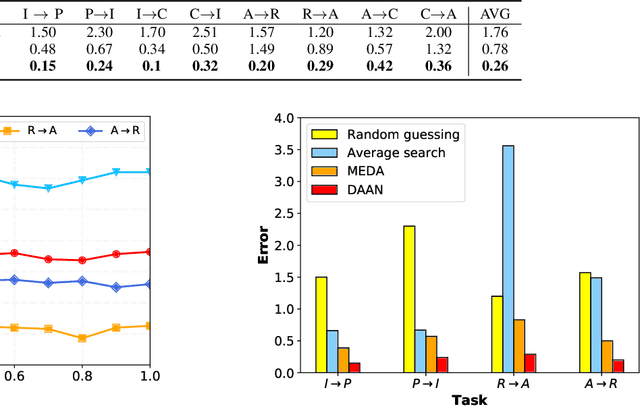
Transfer learning aims to learn robust classifiers for the target domain by leveraging knowledge from a source domain. Since the source and the target domains are usually from different distributions, existing methods mainly focus on adapting the cross-domain marginal or conditional distributions. However, in real applications, the marginal and conditional distributions usually have different contributions to the domain discrepancy. Existing methods fail to quantitatively evaluate the different importance of these two distributions, which will result in unsatisfactory transfer performance. In this paper, we propose a novel concept called Dynamic Distribution Adaptation (DDA), which is capable of quantitatively evaluating the relative importance of each distribution. DDA can be easily incorporated into the framework of structural risk minimization to solve transfer learning problems. On the basis of DDA, we propose two novel learning algorithms: (1) Manifold Dynamic Distribution Adaptation (MDDA) for traditional transfer learning, and (2) Dynamic Distribution Adaptation Network (DDAN) for deep transfer learning. Extensive experiments demonstrate that MDDA and DDAN significantly improve the transfer learning performance and setup a strong baseline over the latest deep and adversarial methods on digits recognition, sentiment analysis, and image classification. More importantly, it is shown that marginal and conditional distributions have different contributions to the domain divergence, and our DDA is able to provide good quantitative evaluation of their relative importance which leads to better performance. We believe this observation can be helpful for future research in transfer learning.
* Accepted to ACM Transactions on Intelligent Systems and Technology (ACM TIST) 2019, 25 pages. arXiv admin note: text overlap with arXiv:1807.07258
Task-Driven Common Representation Learning via Bridge Neural Network
Jun 26, 2019
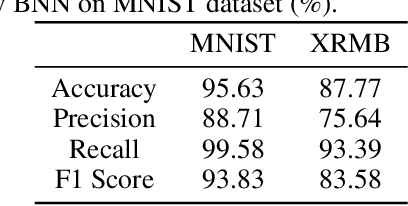
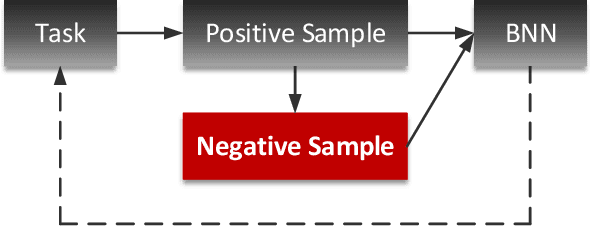
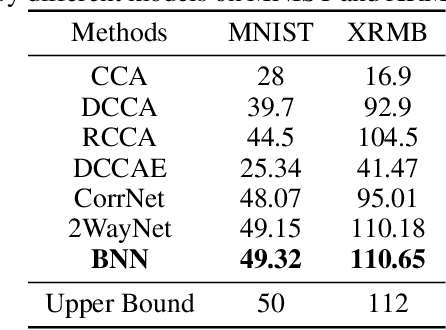
This paper introduces a novel deep learning based method, named bridge neural network (BNN) to dig the potential relationship between two given data sources task by task. The proposed approach employs two convolutional neural networks that project the two data sources into a feature space to learn the desired common representation required by the specific task. The training objective with artificial negative samples is introduced with the ability of mini-batch training and it's asymptotically equivalent to maximizing the total correlation of the two data sources, which is verified by the theoretical analysis. The experiments on the tasks, including pair matching, canonical correlation analysis, transfer learning, and reconstruction demonstrate the state-of-the-art performance of BNN, which may provide new insights into the aspect of common representation learning.
Easy Transfer Learning By Exploiting Intra-domain Structures
Apr 10, 2019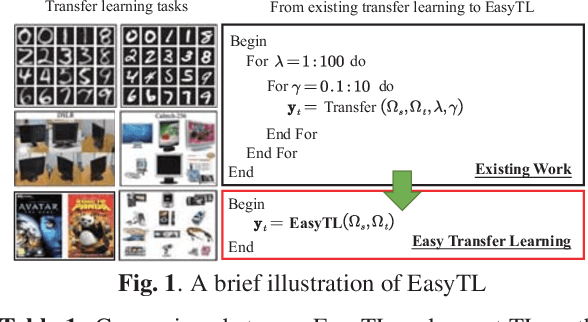
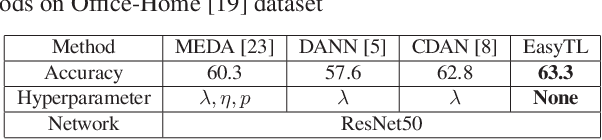
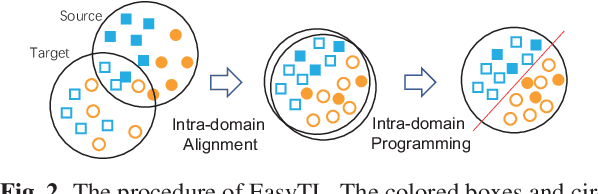
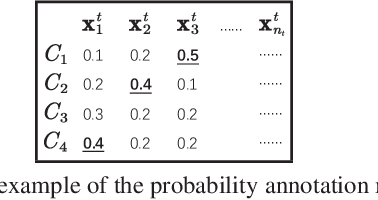
Transfer learning aims at transferring knowledge from a well-labeled domain to a similar but different domain with limited or no labels. Unfortunately, existing learning-based methods often involve intensive model selection and hyperparameter tuning to obtain good results. Moreover, cross-validation is not possible for tuning hyperparameters since there are often no labels in the target domain. This would restrict wide applicability of transfer learning especially in computationally-constraint devices such as wearables. In this paper, we propose a practically Easy Transfer Learning (EasyTL) approach which requires no model selection and hyperparameter tuning, while achieving competitive performance. By exploiting intra-domain structures, EasyTL is able to learn both non-parametric transfer features and classifiers. Extensive experiments demonstrate that, compared to state-of-the-art traditional and deep methods, EasyTL satisfies the Occam's Razor principle: it is extremely easy to implement and use while achieving comparable or better performance in classification accuracy and much better computational efficiency. Additionally, it is shown that EasyTL can increase the performance of existing transfer feature learning methods.
DropPruning for Model Compression
Dec 05, 2018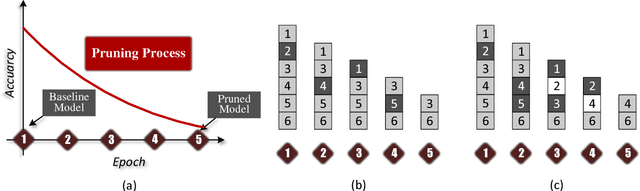

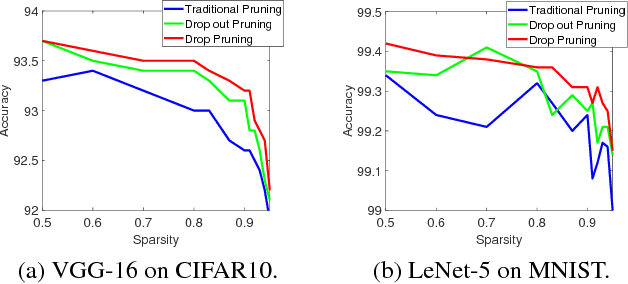
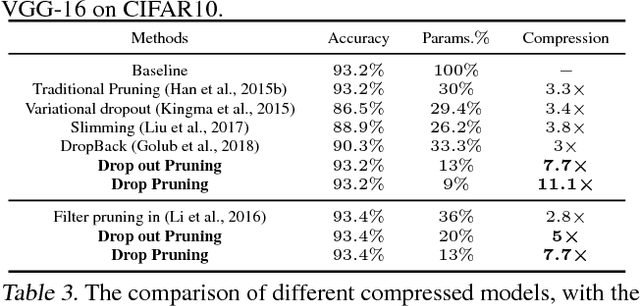
Deep neural networks (DNNs) have dramatically achieved great success on a variety of challenging tasks. However, most of the successful DNNs are structurally so complex, leading to much storage requirement and floating-point operation. This paper proposes a novel technique, named Drop Pruning, to compress the DNNs by pruning the weights from a dense high-accuracy baseline model without accuracy loss. Drop Pruning also falls into the standard iterative prune-retrain procedure, where a \emph{drop} strategy exists at each pruning step: \emph{drop out}, stochastic deleting some unimportant weights and \emph{drop in}, stochastic recovering some pruned weights. \emph{Drop out} and \emph{drop in} are supposed to handle the two drawbacks of the traditional pruning methods: local importance judgment and irretrievable pruning process, respectively. The suitable choosing of \emph{drop} probabilities can decrease the model size during pruning process and lead it to flow to the target sparsity. Drop Pruning also has some similar spirits with dropout, a stochastic algorithm in Integer Optimization and the Dense-Sparse-Dense training technique. Drop Pruning can significantly reducing overfitting while compressing the model. Experimental results demonstrates that Drop Pruning can achieve the state-of-the-art performance on many benchmark pruning tasks, about ${11.1\times}$ compression of VGG-16 on CIFAR10 and ${14.3\times}$ compression of LeNet-5 on MNIST without accuracy loss, which may provide some new insights into the aspect of model compression.
Deep Transfer Learning for Cross-domain Activity Recognition
Aug 19, 2018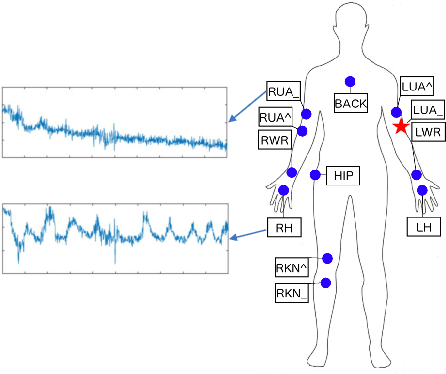
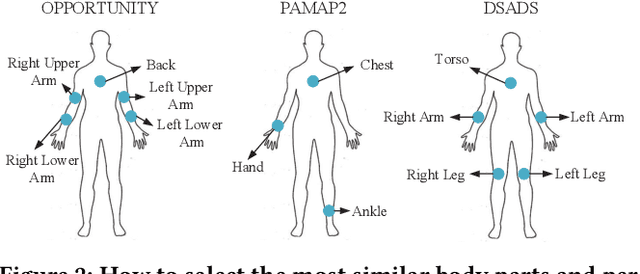
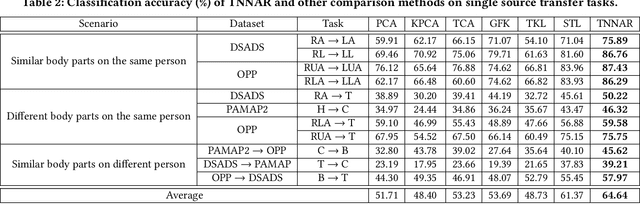
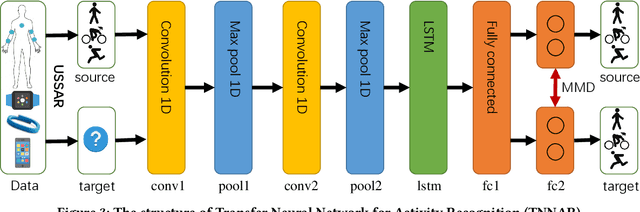
Human activity recognition plays an important role in people's daily life. However, it is often expensive and time-consuming to acquire sufficient labeled activity data. To solve this problem, transfer learning leverages the labeled samples from the source domain to annotate the target domain which has few or none labels. Unfortunately, when there are several source domains available, it is difficult to select the right source domains for transfer. The right source domain means that it has the most similar properties with the target domain, thus their similarity is higher, which can facilitate transfer learning. Choosing the right source domain helps the algorithm perform well and prevents the negative transfer. In this paper, we propose an effective Unsupervised Source Selection algorithm for Activity Recognition (USSAR). USSAR is able to select the most similar $K$ source domains from a list of available domains. After this, we propose an effective Transfer Neural Network to perform knowledge transfer for Activity Recognition (TNNAR). TNNAR could capture both the time and spatial relationship between activities while transferring knowledge. Experiments on three public activity recognition datasets demonstrate that: 1) The USSAR algorithm is effective in selecting the best source domains. 2) The TNNAR method can reach high accuracy when performing activity knowledge transfer.
Visual Domain Adaptation with Manifold Embedded Distribution Alignment
Jul 28, 2018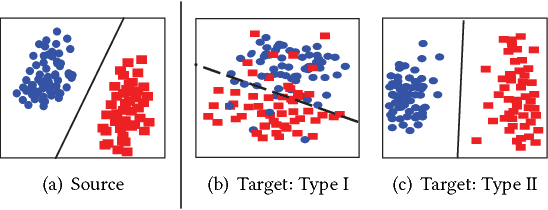
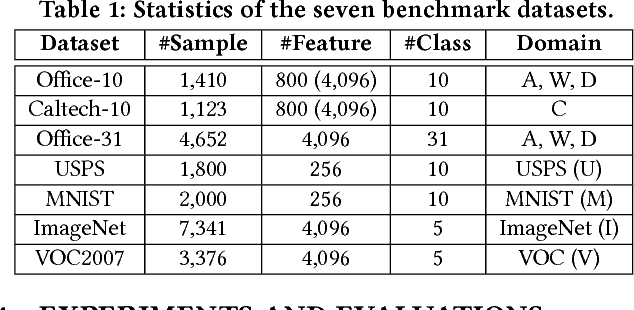
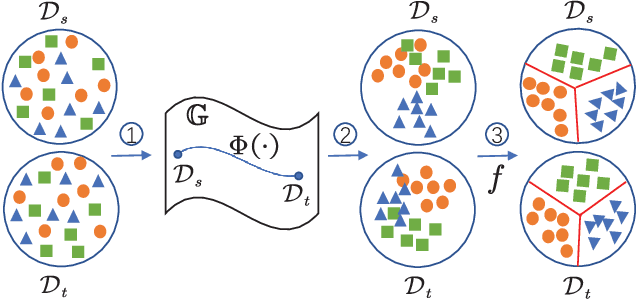
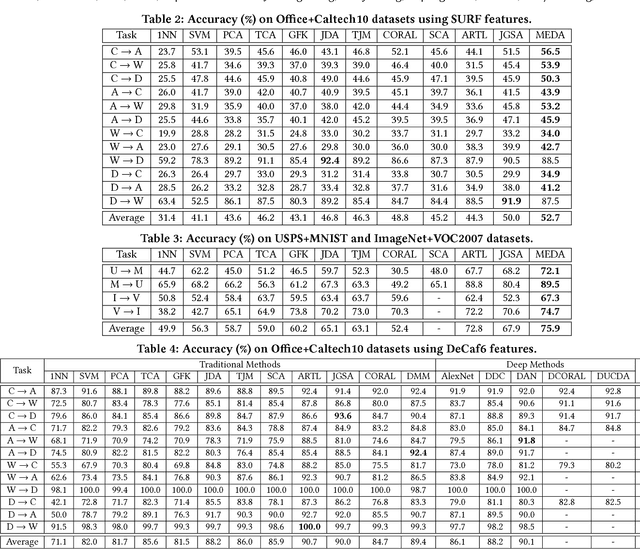
Visual domain adaptation aims to learn robust classifiers for the target domain by leveraging knowledge from a source domain. Existing methods either attempt to align the cross-domain distributions, or perform manifold subspace learning. However, there are two significant challenges: (1) degenerated feature transformation, which means that distribution alignment is often performed in the original feature space, where feature distortions are hard to overcome. On the other hand, subspace learning is not sufficient to reduce the distribution divergence. (2) unevaluated distribution alignment, which means that existing distribution alignment methods only align the marginal and conditional distributions with equal importance, while they fail to evaluate the different importance of these two distributions in real applications. In this paper, we propose a Manifold Embedded Distribution Alignment (MEDA) approach to address these challenges. MEDA learns a domain-invariant classifier in Grassmann manifold with structural risk minimization, while performing dynamic distribution alignment to quantitatively account for the relative importance of marginal and conditional distributions. To the best of our knowledge, MEDA is the first attempt to perform dynamic distribution alignment for manifold domain adaptation. Extensive experiments demonstrate that MEDA shows significant improvements in classification accuracy compared to state-of-the-art traditional and deep methods.