 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitively Layered Data Synthesis for Domain Adaptation of LLMs to Space Situational Awareness
Mar 10, 2026Large language models (LLMs) demonstrate exceptional performance on general-purpose tasks. however, transferring them to complex engineering domains such as space situational awareness (SSA) remains challenging owing to insufficient structural alignment with mission chains, the absence of higher-order cognitive supervision, and poor correspondence between data quality criteria and engineering specifications. The core bottleneck is the construction of high-quality supervised fine-tuning (SFT) datasets. To this end, we propose BD-FDG (Bloom's Taxonomy-based Domain-specific Fine-tuning Data Generation), a framework that addresses incomplete knowledge coverage, shallow cognitive depth, and limited quality controllability through three mechanisms: structured knowledge organization, cognitively layered question modeling, and automated quality control. The framework uses a knowledge tree to ensure structured corpus coverage, designs a question generation scheme spanning nine categories and six cognitive levels from Remember to Create to produce samples with a continuous difficulty gradient, and applies a multidimensional scoring pipeline to enforce domain rigor and consistency. Using BD-FDG, we construct SSA-SFT, a domain dataset of approximately 230K samples, and fine-tune Qwen3-8B to obtain SSA-LLM-8B. Experiments show that SSA-LLM-8B achieves relative BLEU-1 improvements of 144\% (no-think) and 176\% (think) on the domain test set and a win rate of 82.21\% over the baseline in arena comparisons, while largely preserving general benchmark performance (MMLU-Pro, MATH-500). These results validate SFT data construction driven by cognitive layering as an effective paradigm for complex engineering domains and provide a transferable framework for domain-specific LLM adaptation.
Physically Explainable Deep Learning for Convective Initiation Nowcasting Using GOES-16 Satellite Observations
Oct 24, 2023



Convection initiation (CI) nowcasting remains a challenging problem for both numerical weather prediction models and existing nowcasting algorithms. In this study, object-based probabilistic deep learning models are developed to predict CI based on multichannel infrared GOES-R satellite observations. The data come from patches surrounding potential CI events identified in Multi-Radar Multi-Sensor Doppler weather radar products over the Great Plains region from June and July 2020 and June 2021. An objective radar-based approach is used to identify these events. The deep learning models significantly outperform the classical logistic model at lead times up to 1 hour, especially on the false alarm ratio. Through case studies, the deep learning model exhibits the dependence on the characteristics of clouds and moisture at multiple levels. Model explanation further reveals the model's decision-making process with different baselines. The explanation results highlight the importance of moisture and cloud features at different levels depending on the choice of baseline. Our study demonstrates the advantage of using different baselines in further understanding model behavior and gaining scientific insights.
DropPruning for Model Compression
Dec 05, 2018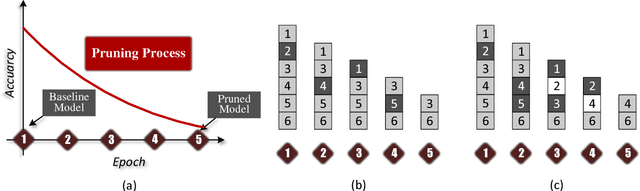

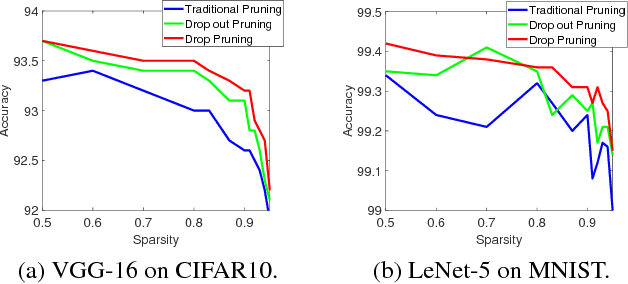
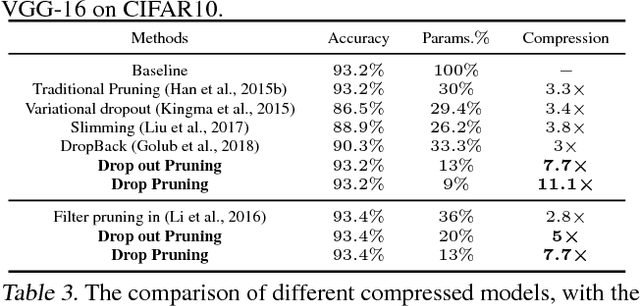
Deep neural networks (DNNs) have dramatically achieved great success on a variety of challenging tasks. However, most of the successful DNNs are structurally so complex, leading to much storage requirement and floating-point operation. This paper proposes a novel technique, named Drop Pruning, to compress the DNNs by pruning the weights from a dense high-accuracy baseline model without accuracy loss. Drop Pruning also falls into the standard iterative prune-retrain procedure, where a \emph{drop} strategy exists at each pruning step: \emph{drop out}, stochastic deleting some unimportant weights and \emph{drop in}, stochastic recovering some pruned weights. \emph{Drop out} and \emph{drop in} are supposed to handle the two drawbacks of the traditional pruning methods: local importance judgment and irretrievable pruning process, respectively. The suitable choosing of \emph{drop} probabilities can decrease the model size during pruning process and lead it to flow to the target sparsity. Drop Pruning also has some similar spirits with dropout, a stochastic algorithm in Integer Optimization and the Dense-Sparse-Dense training technique. Drop Pruning can significantly reducing overfitting while compressing the model. Experimental results demonstrates that Drop Pruning can achieve the state-of-the-art performance on many benchmark pruning tasks, about ${11.1\times}$ compression of VGG-16 on CIFAR10 and ${14.3\times}$ compression of LeNet-5 on MNIST without accuracy loss, which may provide some new insights into the aspect of model compression.