 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Jamming for a More Effective Constellation Attack
Jan 20, 2022
The common jamming mode in wireless communication is band barrage jamming, which is controllable and difficult to resist. Although this method is simple to implement, it is obviously not the best jamming waveform. Therefore, based on the idea of adversarial examples, we propose the adversarial jamming waveform, which can independently optimize and find the best jamming waveform. We attack QAM with adversarial jamming and find that the optimal jamming waveform is equivalent to the amplitude and phase between the nearest constellation points. Furthermore, by verifying the jamming performance on a hardware platform, it is shown that our method significantly improves the bit error rate compared to other methods.
Low-Interception Waveform: To Prevent the Recognition of Spectrum Waveform Modulation via Adversarial Examples
Jan 20, 2022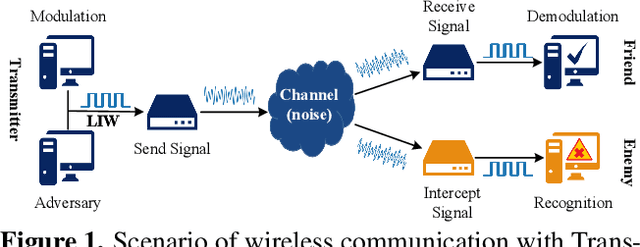
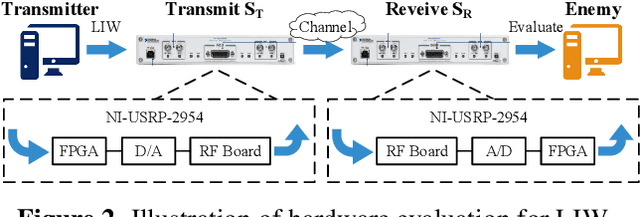
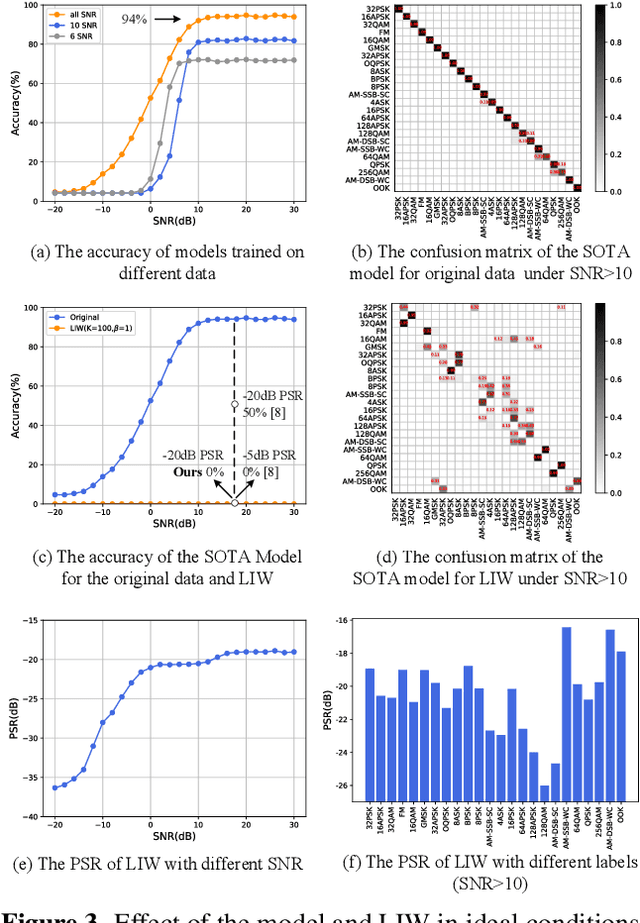

Deep learning is applied to many complex tasks in the field of wireless communication, such as modulation recognition of spectrum waveforms, because of its convenience and efficiency. This leads to the problem of a malicious third party using a deep learning model to easily recognize the modulation format of the transmitted waveform. Some existing works address this problem directly using the concept of adversarial examples in the image domain without fully considering the characteristics of the waveform transmission in the physical world. Therefore, we propose a low-intercept waveform~(LIW) generation method that can reduce the probability of the modulation being recognized by a third party without affecting the reliable communication of the friendly party. Our LIW exhibits significant low-interception performance even in the physical hardware experiment, decreasing the accuracy of the state of the art model to approximately $15\%$ with small perturbations.
* 4 pages, 4 figures, published in 2021 34th General Assembly and Scientific Symposium of the International Union of Radio Science, URSI GASS 2021
Adversarial YOLO: Defense Human Detection Patch Attacks via Detecting Adversarial Patches
Mar 16, 2021

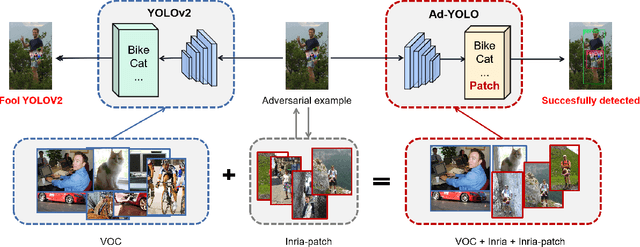
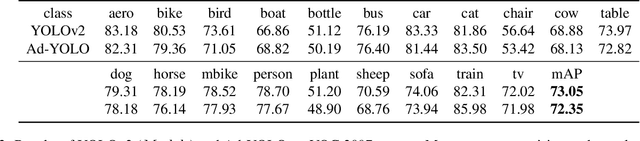
The security of object detection systems has attracted increasing attention, especially when facing adversarial patch attacks. Since patch attacks change the pixels in a restricted area on objects, they are easy to implement in the physical world, especially for attacking human detection systems. The existing defenses against patch attacks are mostly applied for image classification problems and have difficulty resisting human detection attacks. Towards this critical issue, we propose an efficient and effective plug-in defense component on the YOLO detection system, which we name Ad-YOLO. The main idea is to add a patch class on the YOLO architecture, which has a negligible inference increment. Thus, Ad-YOLO is expected to directly detect both the objects of interest and adversarial patches. To the best of our knowledge, our approach is the first defense strategy against human detection attacks. We investigate Ad-YOLO's performance on the YOLOv2 baseline. To improve the ability of Ad-YOLO to detect variety patches, we first use an adversarial training process to develop a patch dataset based on the Inria dataset, which we name Inria-Patch. Then, we train Ad-YOLO by a combination of Pascal VOC, Inria, and Inria-Patch datasets. With a slight drop of $0.70\%$ mAP on VOC 2007 test set, Ad-YOLO achieves $80.31\%$ AP of persons, which highly outperforms $33.93\%$ AP for YOLOv2 when facing white-box patch attacks. Furthermore, compared with YOLOv2, the results facing a physical-world attack are also included to demonstrate Ad-YOLO's excellent generalization ability.
The QXS-SAROPT Dataset for Deep Learning in SAR-Optical Data Fusion
Mar 15, 2021Deep learning techniques have made an increasing impact on the field of remote sensing. However, deep neural networks based fusion of multimodal data from different remote sensors with heterogenous characteristics has not been fully explored, due to the lack of availability of big amounts of perfectly aligned multi-sensor image data with diverse scenes of high resolution, especially for synthetic aperture radar (SAR) data and optical imagery. In this paper, we publish the QXS-SAROPT dataset to foster deep learning research in SAR-optical data fusion. QXS-SAROPT comprises 20,000 pairs of corresponding image patches, collected from three port cities: San Diego, Shanghai and Qingdao acquired by the SAR satellite GaoFen-3 and optical satellites of Google Earth. Besides a detailed description of the dataset, we show exemplary results for two representative applications, namely SAR-optical image matching and SAR ship detection boosted by cross-modal information from optical images. Since QXS-SAROPT is a large open dataset with multiple scenes of the highest resolution of this kind, we believe it will support further developments in the field of deep learning based SAR-optical data fusion for remote sensing.
Boosting ship detection in SAR images with complementary pretraining techniques
Mar 15, 2021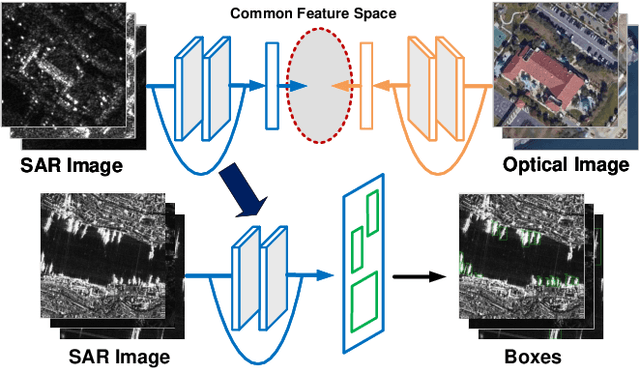
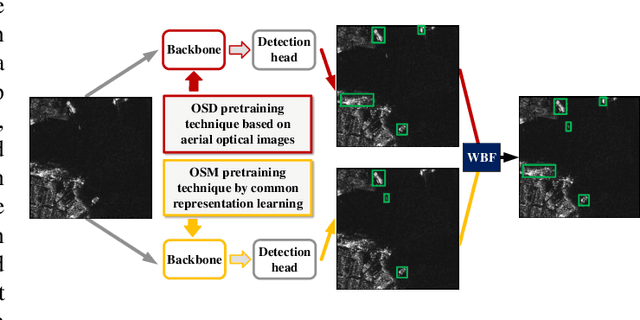
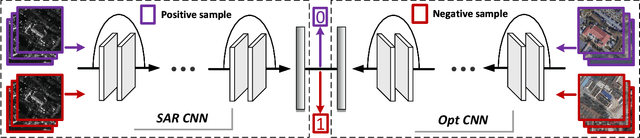
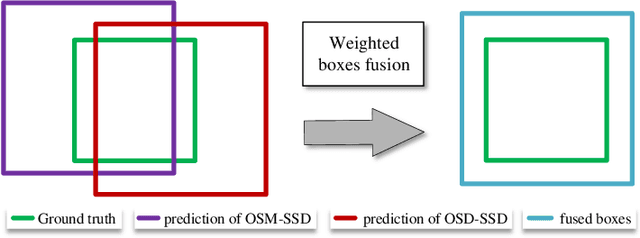
Deep learning methods have made significant progress in ship detection in synthetic aperture radar (SAR) images. The pretraining technique is usually adopted to support deep neural networks-based SAR ship detectors due to the scarce labeled SAR images. However, directly leveraging ImageNet pretraining is hardly to obtain a good ship detector because of different imaging perspective and geometry. In this paper, to resolve the problem of inconsistent imaging perspective between ImageNet and earth observations, we propose an optical ship detector (OSD) pretraining technique, which transfers the characteristics of ships in earth observations to SAR images from a large-scale aerial image dataset. On the other hand, to handle the problem of different imaging geometry between optical and SAR images, we propose an optical-SAR matching (OSM) pretraining technique, which transfers plentiful texture features from optical images to SAR images by common representation learning on the optical-SAR matching task. Finally, observing that the OSD pretraining based SAR ship detector has a better recall on sea area while the OSM pretraining based SAR ship detector can reduce false alarms on land area, we combine the predictions of the two detectors through weighted boxes fusion to further improve detection results. Extensive experiments on four SAR ship detection datasets and two representative CNN-based detection benchmarks are conducted to show the effectiveness and complementarity of the two proposed detectors, and the state-of-the-art performance of the combination of the two detectors. The proposed method won the sixth place of ship detection in SAR images in 2020 Gaofen challenge.
How Does GAN-based Semi-supervised Learning Work?
Jul 11, 2020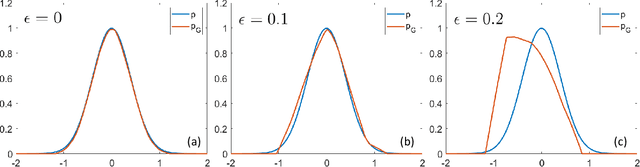
Generative adversarial networks (GANs) have been widely used and have achieved competitive results in semi-supervised learning. This paper theoretically analyzes how GAN-based semi-supervised learning (GAN-SSL) works. We first prove that, given a fixed generator, optimizing the discriminator of GAN-SSL is equivalent to optimizing that of supervised learning. Thus, the optimal discriminator in GAN-SSL is expected to be perfect on labeled data. Then, if the perfect discriminator can further cause the optimization objective to reach its theoretical maximum, the optimal generator will match the true data distribution. Since it is impossible to reach the theoretical maximum in practice, one cannot expect to obtain a perfect generator for generating data, which is apparently different from the objective of GANs. Furthermore, if the labeled data can traverse all connected subdomains of the data manifold, which is reasonable in semi-supervised classification, we additionally expect the optimal discriminator in GAN-SSL to also be perfect on unlabeled data. In conclusion, the minimax optimization in GAN-SSL will theoretically output a perfect discriminator on both labeled and unlabeled data by unexpectedly learning an imperfect generator, i.e., GAN-SSL can effectively improve the generalization ability of the discriminator by leveraging unlabeled information.
Training few-shot classification via the perspective of minibatch and pretraining
Apr 10, 2020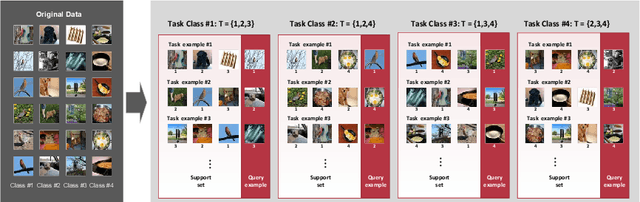

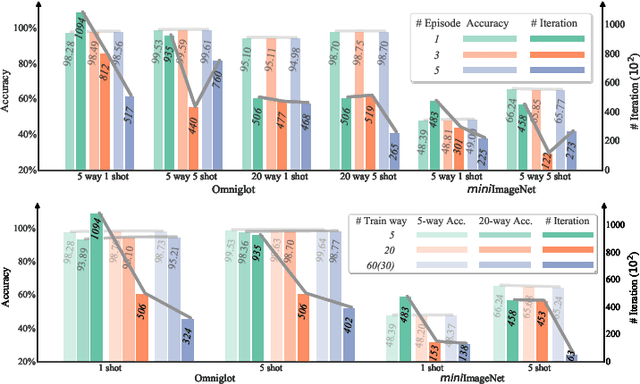
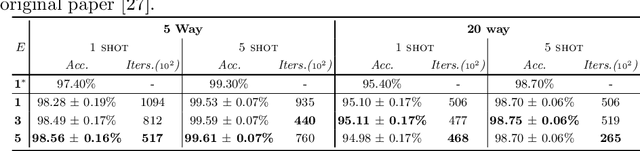
Few-shot classification is a challenging task which aims to formulate the ability of humans to learn concepts from limited prior data and has drawn considerable attention in machine learning. Recent progress in few-shot classification has featured meta-learning, in which a parameterized model for a learning algorithm is defined and trained to learn the ability of handling classification tasks on extremely large or infinite episodes representing different classification task, each with a small labeled support set and its corresponding query set. In this work, we advance this few-shot classification paradigm by formulating it as a supervised classification learning problem. We further propose multi-episode and cross-way training techniques, which respectively correspond to the minibatch and pretraining in classification problems. Experimental results on a state-of-the-art few-shot classification method (prototypical networks) demonstrate that both the proposed training strategies can highly accelerate the training process without accuracy loss for varying few-shot classification problems on Omniglot and miniImageNet.
Towards GANs' Approximation Ability
Apr 10, 2020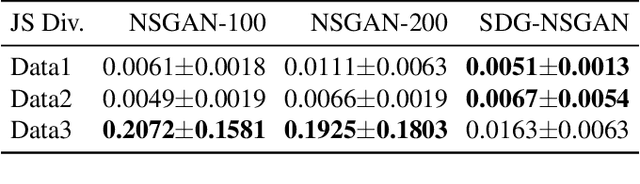

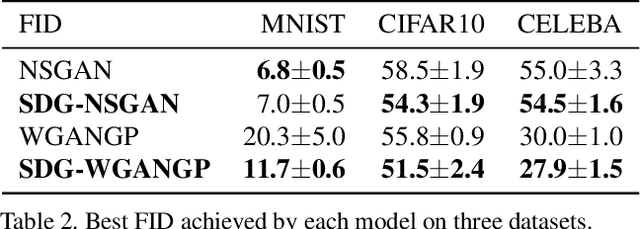

Generative adversarial networks (GANs) have attracted intense interest in the field of generative models. However, few investigations focusing either on the theoretical analysis or on algorithm design for the approximation ability of the generator of GANs have been reported. This paper will first theoretically analyze GANs' approximation property. Similar to the universal approximation property of the full connected neural networks with one hidden layer, we prove that the generator with the input latent variable in GANs can universally approximate the potential data distribution given the increasing hidden neurons. Furthermore, we propose an approach named stochastic data generation (SDG) to enhance GANs' approximation ability. Our approach is based on the simple idea of imposing randomness through data generation in GANs by a prior distribution on the conditional probability between the layers. Our approach can be easily implemented by using the reparameterization trick. The experimental results on synthetic dataset verify the improved approximation ability obtained by this SDG approach. In the practical dataset, the NSGAN/WGANGP with SDG can also outperform traditional GANs with little change in the model architectures.
Blind Adversarial Pruning: Balance Accuracy, Efficiency and Robustness
Apr 10, 2020



With the growth of interest in the attack and defense of deep neural networks, researchers are focusing more on the robustness of applying them to devices with limited memory. Thus, unlike adversarial training, which only considers the balance between accuracy and robustness, we come to a more meaningful and critical issue, i.e., the balance among accuracy, efficiency and robustness (AER). Recently, some related works focused on this issue, but with different observations, and the relations among AER remain unclear. This paper first investigates the robustness of pruned models with different compression ratios under the gradual pruning process and concludes that the robustness of the pruned model drastically varies with different pruning processes, especially in response to attacks with large strength. Second, we test the performance of mixing the clean data and adversarial examples (generated with a prescribed uniform budget) into the gradual pruning process, called adversarial pruning, and find the following: the pruned model's robustness exhibits high sensitivity to the budget. Furthermore, to better balance the AER, we propose an approach called blind adversarial pruning (BAP), which introduces the idea of blind adversarial training into the gradual pruning process. The main idea is to use a cutoff-scale strategy to adaptively estimate a nonuniform budget to modify the AEs used during pruning, thus ensuring that the strengths of AEs are dynamically located within a reasonable range at each pruning step and ultimately improving the overall AER of the pruned model. The experimental results obtained using BAP for pruning classification models based on several benchmarks demonstrate the competitive performance of this method: the robustness of the model pruned by BAP is more stable among varying pruning processes, and BAP exhibits better overall AER than adversarial pruning.
Blind Adversarial Training: Balance Accuracy and Robustness
Apr 10, 2020
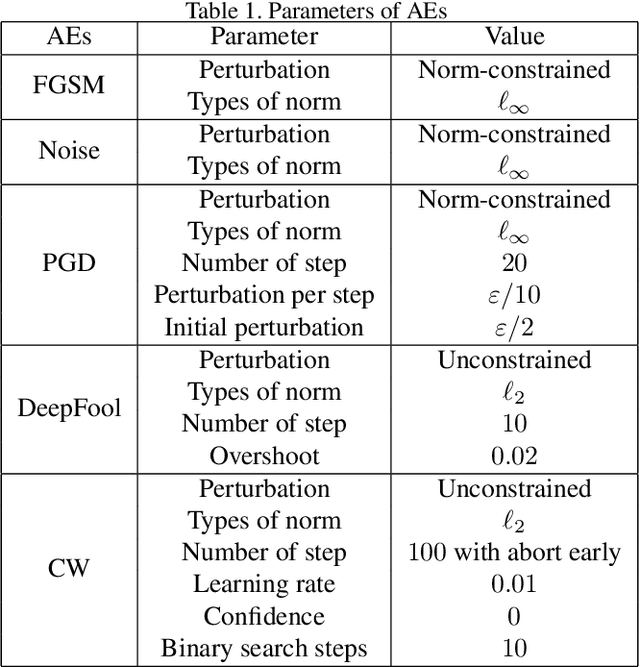

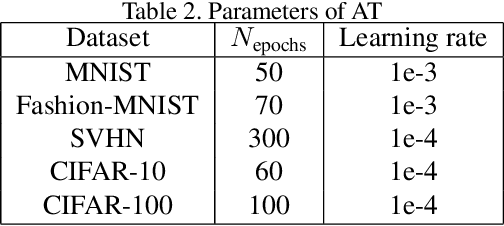
Adversarial training (AT) aims to improve the robustness of deep learning models by mixing clean data and adversarial examples (AEs). Most existing AT approaches can be grouped into restricted and unrestricted approaches. Restricted AT requires a prescribed uniform budget to constrain the magnitude of the AE perturbations during training, with the obtained results showing high sensitivity to the budget. On the other hand, unrestricted AT uses unconstrained AEs, resulting in the use of AEs located beyond the decision boundary; these overestimated AEs significantly lower the accuracy on clean data. These limitations mean that the existing AT approaches have difficulty in obtaining a comprehensively robust model with high accuracy and robustness when confronting attacks with varying strengths. Considering this problem, this paper proposes a novel AT approach named blind adversarial training (BAT) to better balance the accuracy and robustness. The main idea of this approach is to use a cutoff-scale strategy to adaptively estimate a nonuniform budget to modify the AEs used in the training, ensuring that the strengths of the AEs are dynamically located in a reasonable range and ultimately improving the overall robustness of the AT model. The experimental results obtained using BAT for training classification models on several benchmarks demonstrate the competitive performance of this method.