 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAFM: Dynamic Adaptive Fusion for Multi-Model Collaboration in Composed Image Retrieval
Nov 07, 2025Composed Image Retrieval (CIR) is a cross-modal task that aims to retrieve target images from large-scale databases using a reference image and a modification text. Most existing methods rely on a single model to perform feature fusion and similarity matching. However, this paradigm faces two major challenges. First, one model alone can't see the whole picture and the tiny details at the same time; it has to handle different tasks with the same weights, so it often misses the small but important links between image and text. Second, the absence of dynamic weight allocation prevents adaptive leveraging of complementary model strengths, so the resulting embedding drifts away from the target and misleads the nearest-neighbor search in CIR. To address these limitations, we propose Dynamic Adaptive Fusion (DAFM) for multi-model collaboration in CIR. Rather than optimizing a single method in isolation, DAFM exploits the complementary strengths of heterogeneous models and adaptively rebalances their contributions. This not only maximizes retrieval accuracy but also ensures that the performance gains are independent of the fusion order, highlighting the robustness of our approach. Experiments on the CIRR and FashionIQ benchmarks demonstrate consistent improvements. Our method achieves a Recall@10 of 93.21 and an Rmean of 84.43 on CIRR, and an average Rmean of 67.48 on FashionIQ, surpassing recent strong baselines by up to 4.5%. These results confirm that dynamic multi-model collaboration provides an effective and general solution for CIR.
Adversarial Jamming for a More Effective Constellation Attack
Jan 20, 2022
The common jamming mode in wireless communication is band barrage jamming, which is controllable and difficult to resist. Although this method is simple to implement, it is obviously not the best jamming waveform. Therefore, based on the idea of adversarial examples, we propose the adversarial jamming waveform, which can independently optimize and find the best jamming waveform. We attack QAM with adversarial jamming and find that the optimal jamming waveform is equivalent to the amplitude and phase between the nearest constellation points. Furthermore, by verifying the jamming performance on a hardware platform, it is shown that our method significantly improves the bit error rate compared to other methods.
Low-Interception Waveform: To Prevent the Recognition of Spectrum Waveform Modulation via Adversarial Examples
Jan 20, 2022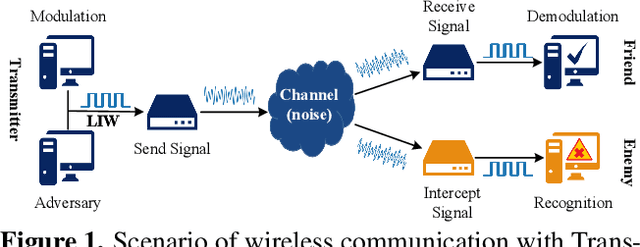
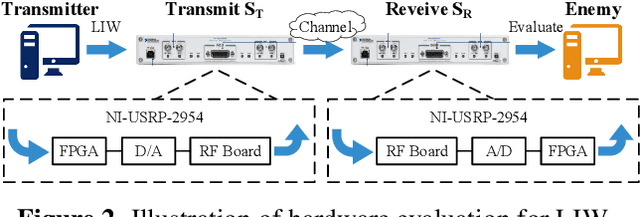
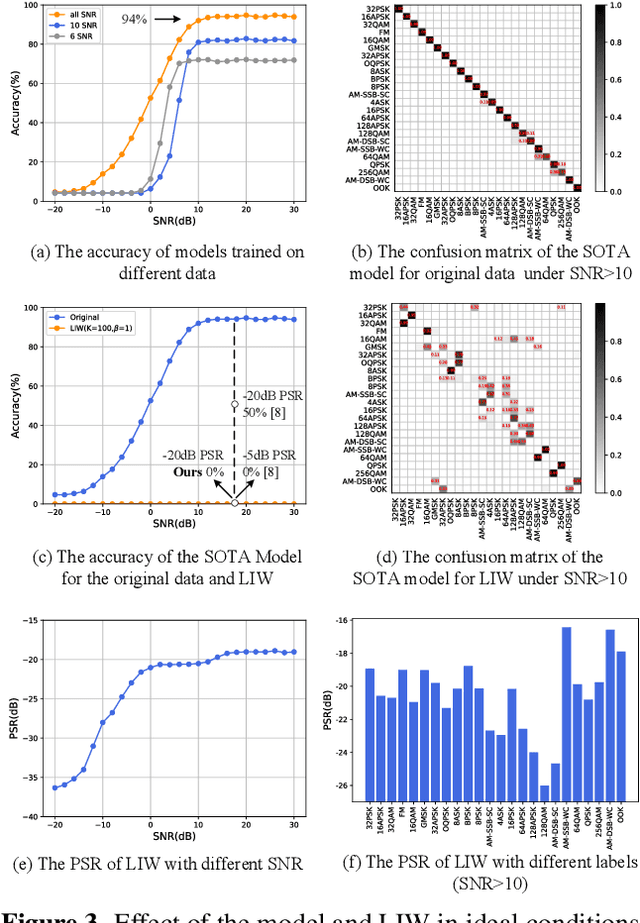

Deep learning is applied to many complex tasks in the field of wireless communication, such as modulation recognition of spectrum waveforms, because of its convenience and efficiency. This leads to the problem of a malicious third party using a deep learning model to easily recognize the modulation format of the transmitted waveform. Some existing works address this problem directly using the concept of adversarial examples in the image domain without fully considering the characteristics of the waveform transmission in the physical world. Therefore, we propose a low-intercept waveform~(LIW) generation method that can reduce the probability of the modulation being recognized by a third party without affecting the reliable communication of the friendly party. Our LIW exhibits significant low-interception performance even in the physical hardware experiment, decreasing the accuracy of the state of the art model to approximately $15\%$ with small perturbations.
* 4 pages, 4 figures, published in 2021 34th General Assembly and Scientific Symposium of the International Union of Radio Science, URSI GASS 2021
Adversarial YOLO: Defense Human Detection Patch Attacks via Detecting Adversarial Patches
Mar 16, 2021

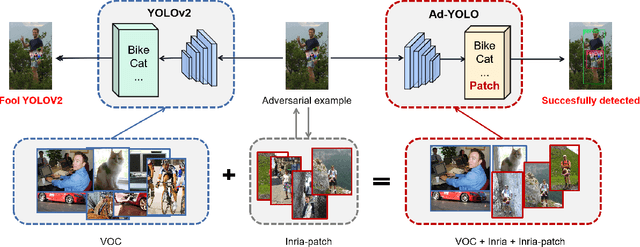
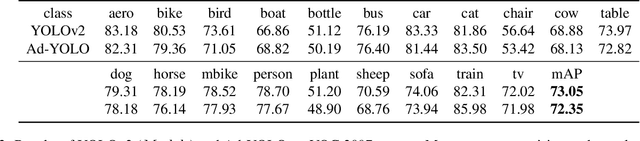
The security of object detection systems has attracted increasing attention, especially when facing adversarial patch attacks. Since patch attacks change the pixels in a restricted area on objects, they are easy to implement in the physical world, especially for attacking human detection systems. The existing defenses against patch attacks are mostly applied for image classification problems and have difficulty resisting human detection attacks. Towards this critical issue, we propose an efficient and effective plug-in defense component on the YOLO detection system, which we name Ad-YOLO. The main idea is to add a patch class on the YOLO architecture, which has a negligible inference increment. Thus, Ad-YOLO is expected to directly detect both the objects of interest and adversarial patches. To the best of our knowledge, our approach is the first defense strategy against human detection attacks. We investigate Ad-YOLO's performance on the YOLOv2 baseline. To improve the ability of Ad-YOLO to detect variety patches, we first use an adversarial training process to develop a patch dataset based on the Inria dataset, which we name Inria-Patch. Then, we train Ad-YOLO by a combination of Pascal VOC, Inria, and Inria-Patch datasets. With a slight drop of $0.70\%$ mAP on VOC 2007 test set, Ad-YOLO achieves $80.31\%$ AP of persons, which highly outperforms $33.93\%$ AP for YOLOv2 when facing white-box patch attacks. Furthermore, compared with YOLOv2, the results facing a physical-world attack are also included to demonstrate Ad-YOLO's excellent generalization ability.