 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Jamming for a More Effective Constellation Attack
Jan 20, 2022
The common jamming mode in wireless communication is band barrage jamming, which is controllable and difficult to resist. Although this method is simple to implement, it is obviously not the best jamming waveform. Therefore, based on the idea of adversarial examples, we propose the adversarial jamming waveform, which can independently optimize and find the best jamming waveform. We attack QAM with adversarial jamming and find that the optimal jamming waveform is equivalent to the amplitude and phase between the nearest constellation points. Furthermore, by verifying the jamming performance on a hardware platform, it is shown that our method significantly improves the bit error rate compared to other methods.
Low-Interception Waveform: To Prevent the Recognition of Spectrum Waveform Modulation via Adversarial Examples
Jan 20, 2022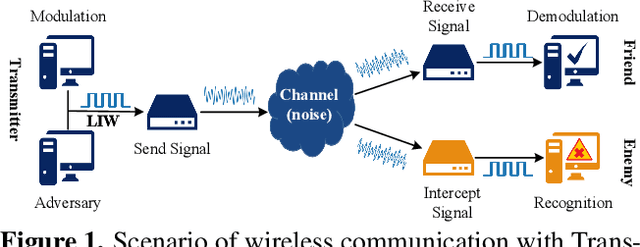
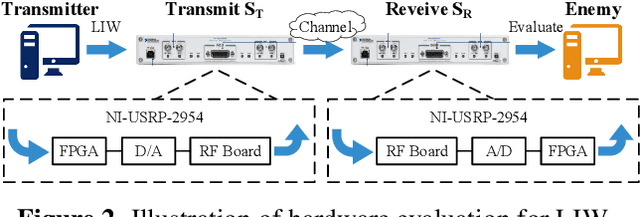
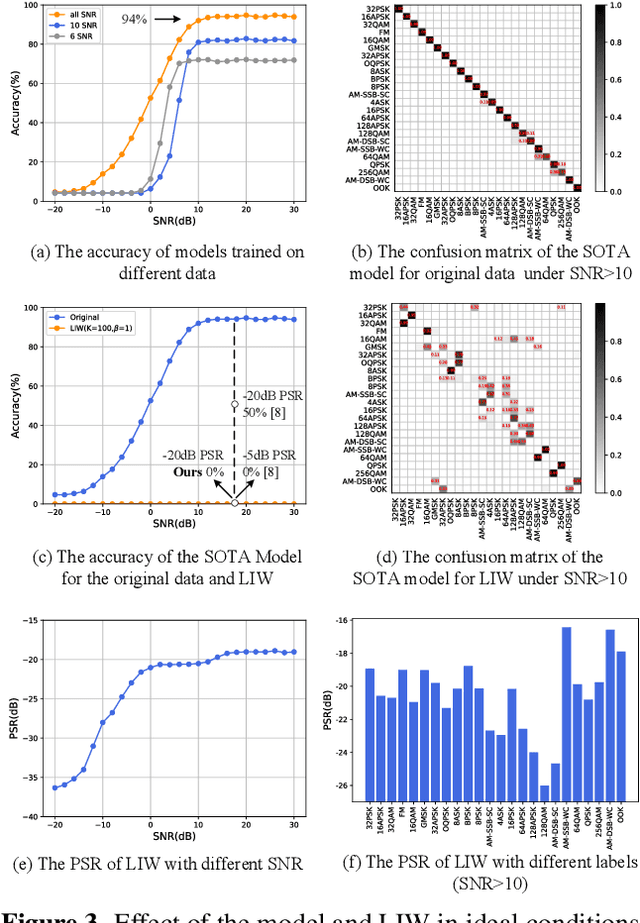

Deep learning is applied to many complex tasks in the field of wireless communication, such as modulation recognition of spectrum waveforms, because of its convenience and efficiency. This leads to the problem of a malicious third party using a deep learning model to easily recognize the modulation format of the transmitted waveform. Some existing works address this problem directly using the concept of adversarial examples in the image domain without fully considering the characteristics of the waveform transmission in the physical world. Therefore, we propose a low-intercept waveform~(LIW) generation method that can reduce the probability of the modulation being recognized by a third party without affecting the reliable communication of the friendly party. Our LIW exhibits significant low-interception performance even in the physical hardware experiment, decreasing the accuracy of the state of the art model to approximately $15\%$ with small perturbations.
* 4 pages, 4 figures, published in 2021 34th General Assembly and Scientific Symposium of the International Union of Radio Science, URSI GASS 2021
Adversarial YOLO: Defense Human Detection Patch Attacks via Detecting Adversarial Patches
Mar 16, 2021

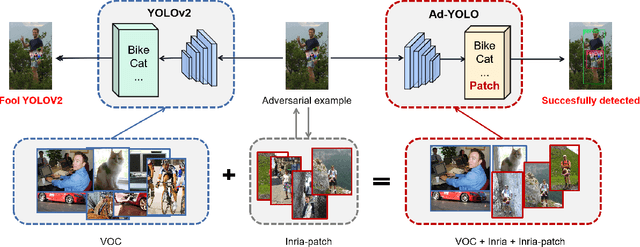
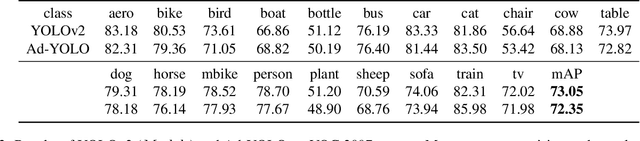
The security of object detection systems has attracted increasing attention, especially when facing adversarial patch attacks. Since patch attacks change the pixels in a restricted area on objects, they are easy to implement in the physical world, especially for attacking human detection systems. The existing defenses against patch attacks are mostly applied for image classification problems and have difficulty resisting human detection attacks. Towards this critical issue, we propose an efficient and effective plug-in defense component on the YOLO detection system, which we name Ad-YOLO. The main idea is to add a patch class on the YOLO architecture, which has a negligible inference increment. Thus, Ad-YOLO is expected to directly detect both the objects of interest and adversarial patches. To the best of our knowledge, our approach is the first defense strategy against human detection attacks. We investigate Ad-YOLO's performance on the YOLOv2 baseline. To improve the ability of Ad-YOLO to detect variety patches, we first use an adversarial training process to develop a patch dataset based on the Inria dataset, which we name Inria-Patch. Then, we train Ad-YOLO by a combination of Pascal VOC, Inria, and Inria-Patch datasets. With a slight drop of $0.70\%$ mAP on VOC 2007 test set, Ad-YOLO achieves $80.31\%$ AP of persons, which highly outperforms $33.93\%$ AP for YOLOv2 when facing white-box patch attacks. Furthermore, compared with YOLOv2, the results facing a physical-world attack are also included to demonstrate Ad-YOLO's excellent generalization ability.
Blind Adversarial Pruning: Balance Accuracy, Efficiency and Robustness
Apr 10, 2020



With the growth of interest in the attack and defense of deep neural networks, researchers are focusing more on the robustness of applying them to devices with limited memory. Thus, unlike adversarial training, which only considers the balance between accuracy and robustness, we come to a more meaningful and critical issue, i.e., the balance among accuracy, efficiency and robustness (AER). Recently, some related works focused on this issue, but with different observations, and the relations among AER remain unclear. This paper first investigates the robustness of pruned models with different compression ratios under the gradual pruning process and concludes that the robustness of the pruned model drastically varies with different pruning processes, especially in response to attacks with large strength. Second, we test the performance of mixing the clean data and adversarial examples (generated with a prescribed uniform budget) into the gradual pruning process, called adversarial pruning, and find the following: the pruned model's robustness exhibits high sensitivity to the budget. Furthermore, to better balance the AER, we propose an approach called blind adversarial pruning (BAP), which introduces the idea of blind adversarial training into the gradual pruning process. The main idea is to use a cutoff-scale strategy to adaptively estimate a nonuniform budget to modify the AEs used during pruning, thus ensuring that the strengths of AEs are dynamically located within a reasonable range at each pruning step and ultimately improving the overall AER of the pruned model. The experimental results obtained using BAP for pruning classification models based on several benchmarks demonstrate the competitive performance of this method: the robustness of the model pruned by BAP is more stable among varying pruning processes, and BAP exhibits better overall AER than adversarial pruning.
Blind Adversarial Training: Balance Accuracy and Robustness
Apr 10, 2020

Adversarial training (AT) aims to improve the robustness of deep learning models by mixing clean data and adversarial examples (AEs). Most existing AT approaches can be grouped into restricted and unrestricted approaches. Restricted AT requires a prescribed uniform budget to constrain the magnitude of the AE perturbations during training, with the obtained results showing high sensitivity to the budget. On the other hand, unrestricted AT uses unconstrained AEs, resulting in the use of AEs located beyond the decision boundary; these overestimated AEs significantly lower the accuracy on clean data. These limitations mean that the existing AT approaches have difficulty in obtaining a comprehensively robust model with high accuracy and robustness when confronting attacks with varying strengths. Considering this problem, this paper proposes a novel AT approach named blind adversarial training (BAT) to better balance the accuracy and robustness. The main idea of this approach is to use a cutoff-scale strategy to adaptively estimate a nonuniform budget to modify the AEs used in the training, ensuring that the strengths of the AEs are dynamically located in a reasonable range and ultimately improving the overall robustness of the AT model. The experimental results obtained using BAT for training classification models on several benchmarks demonstrate the competitive performance of this method.
Equivalence of restricted Boltzmann machines and tensor network states
Feb 05, 2018

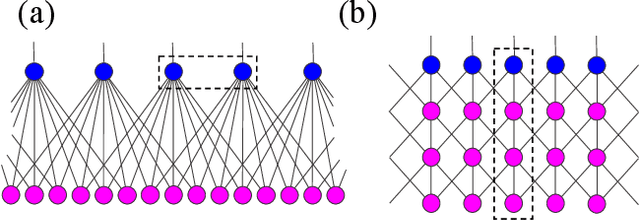

The restricted Boltzmann machine (RBM) is one of the fundamental building blocks of deep learning. RBM finds wide applications in dimensional reduction, feature extraction, and recommender systems via modeling the probability distributions of a variety of input data including natural images, speech signals, and customer ratings, etc. We build a bridge between RBM and tensor network states (TNS) widely used in quantum many-body physics research. We devise efficient algorithms to translate an RBM into the commonly used TNS. Conversely, we give sufficient and necessary conditions to determine whether a TNS can be transformed into an RBM of given architectures. Revealing these general and constructive connections can cross-fertilize both deep learning and quantum many-body physics. Notably, by exploiting the entanglement entropy bound of TNS, we can rigorously quantify the expressive power of RBM on complex data sets. Insights into TNS and its entanglement capacity can guide the design of more powerful deep learning architectures. On the other hand, RBM can represent quantum many-body states with fewer parameters compared to TNS, which may allow more efficient classical simulations.
* 18 pages, 12 figures + 2 appendices; Code implementations at https://github.com/yzcj105/rbm2mps