 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Learning with Projected Entangled Pair States
Sep 12, 2020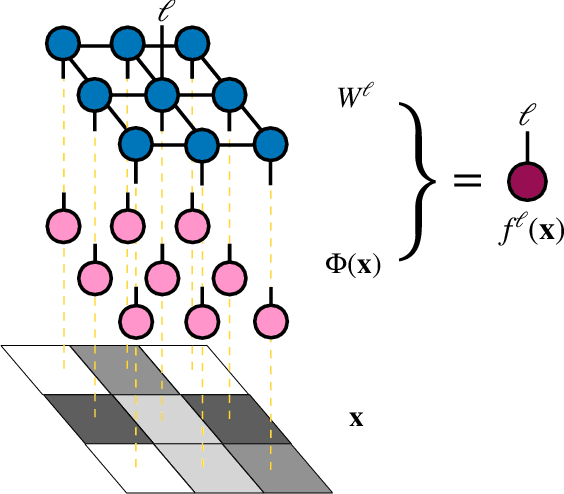

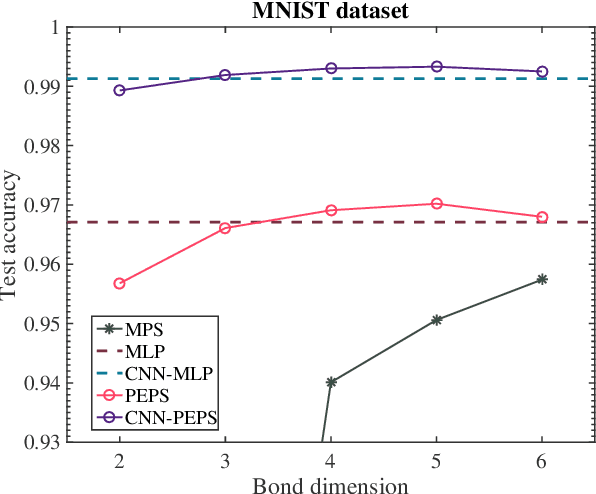
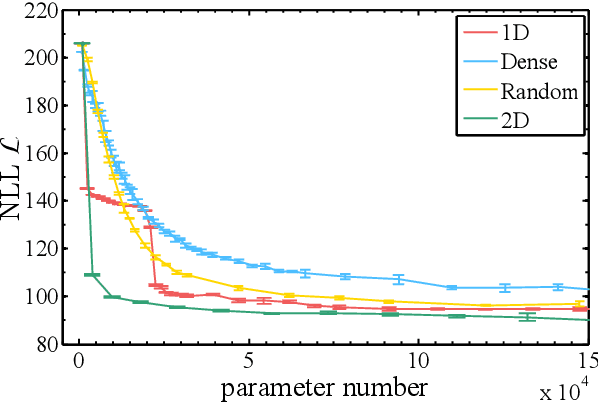
Tensor networks, a model that originated from quantum physics, has been gradually generalized as efficient models in machine learning in recent years. However, in order to achieve exact contraction, only tree-like tensor networks such as the matrix product states and tree tensor networks have been considered, even for modeling two-dimensional data such as images. In this work, we construct supervised learning models for images using the projected entangled pair states (PEPS), a two-dimensional tensor network having a similar structure prior to natural images. Our approach first performs a feature map, which transforms the image data to a product state on a grid, then contracts the product state to a PEPS with trainable parameters to predict image labels. The tensor elements of PEPS are trained by minimizing differences between training labels and predicted labels. The proposed model is evaluated on image classifications using the MNIST and the Fashion-MNIST datasets. We show that our model is significantly superior to existing models using tree-like tensor networks. Moreover, using the same input features, our method performs as well as the multilayer perceptron classifier, but with much fewer parameters and is more stable. Our results shed light on potential applications of two-dimensional tensor network models in machine learning.
Domain Adaption for Knowledge Tracing
Jan 14, 2020
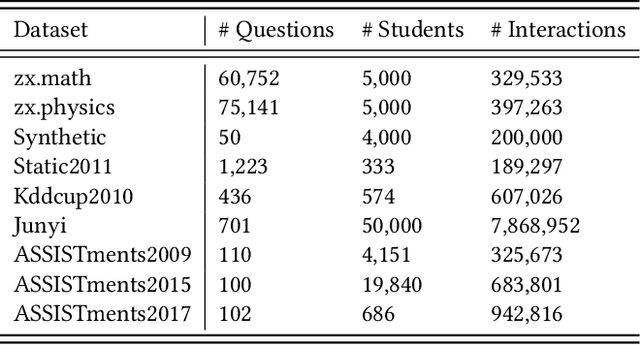

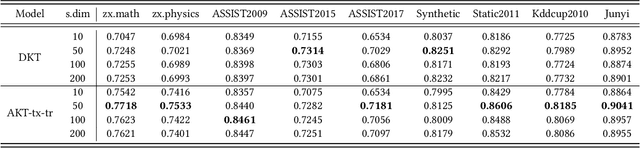
With the rapid development of online education system, knowledge tracing which aims at predicting students' knowledge state is becoming a critical and fundamental task in personalized education. Traditionally, existing methods are domain-specified. However, there are a larger number of domains (e.g., subjects, schools) in the real world and the lacking of data in some domains, how to utilize the knowledge and information in other domains to help train a knowledge tracing model for target domains is increasingly important. We refer to this problem as domain adaptation for knowledge tracing (DAKT) which contains two aspects: (1) how to achieve great knowledge tracing performance in each domain. (2) how to transfer good performed knowledge tracing model between domains. To this end, in this paper, we propose a novel adaptable framework, namely adaptable knowledge tracing (AKT) to address the DAKT problem. Specifically, for the first aspect, we incorporate the educational characteristics (e.g., slip, guess, question texts) based on the deep knowledge tracing (DKT) to obtain a good performed knowledge tracing model. For the second aspect, we propose and adopt three domain adaptation processes. First, we pre-train an auto-encoder to select useful source instances for target model training. Second, we minimize the domain-specific knowledge state distribution discrepancy under maximum mean discrepancy (MMD) measurement to achieve domain adaptation. Third, we adopt fine-tuning to deal with the problem that the output dimension of source and target domain are different to make the model suitable for target domains. Extensive experimental results on two private datasets and seven public datasets clearly prove the effectiveness of AKT for great knowledge tracing performance and its superior transferable ability.
Enhancing Item Response Theory for Cognitive Diagnosis
Jun 01, 2019


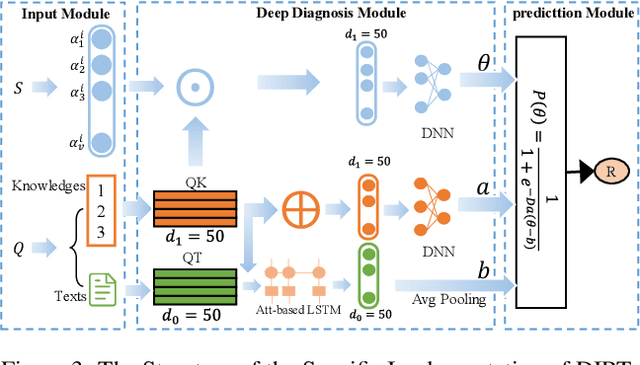
Cognitive diagnosis is a fundamental and crucial task in many educational applications, e.g., computer adaptive test and cognitive assignments. Item Response Theory (IRT) is a classical cognitive diagnosis method which can provide interpretable parameters (i.e., student latent trait, question discrimination, and difficulty) for analyzing student performance. However, traditional IRT ignores the rich information in question texts, cannot diagnose knowledge concept proficiency, and it is inaccurate to diagnose the parameters for the questions which only appear several times. To this end, in this paper, we propose a general Deep Item Response Theory (DIRT) framework to enhance traditional IRT for cognitive diagnosis by exploiting semantic representation from question texts with deep learning. In DIRT, we first use a proficiency vector to represent students' proficiency in knowledge concepts and embed question texts and knowledge concepts to dense vectors by Word2Vec. Then, we design a deep diagnosis module to diagnose parameters in traditional IRT by deep learning techniques. Finally, with the diagnosed parameters, we input them into the logistic-like formula of IRT to predict student performance. Extensive experimental results on real-world data clearly demonstrate the effectiveness and interpretation power of DIRT framework.
Compressing deep neural networks by matrix product operators
Apr 11, 2019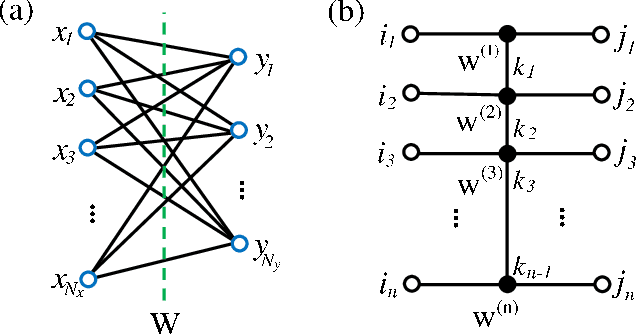
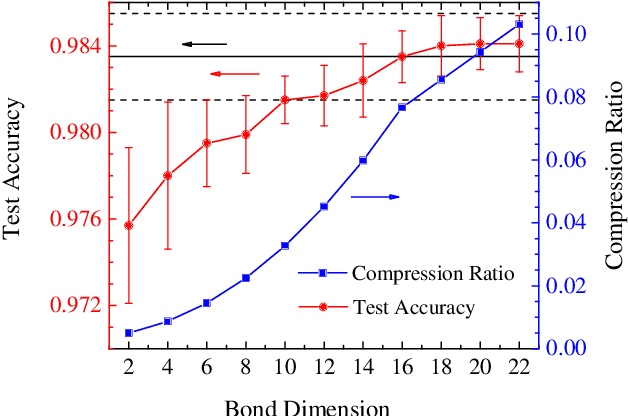
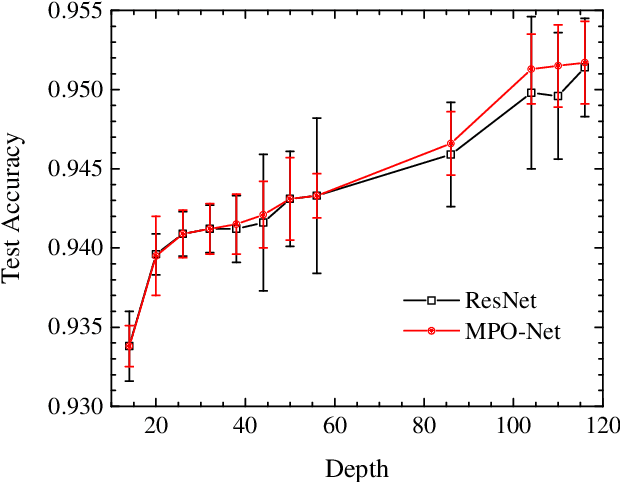

A deep neural network is a parameterization of a multi-layer mapping of signals in terms of many alternatively arranged linear and nonlinear transformations. The linear transformations, which are generally used in the fully-connected as well as convolutional layers, contain most of the variational parameters that are trained and stored. Compressing a deep neural network to reduce its number of variational parameters but not its prediction power is an important but challenging problem towards the establishment of an optimized scheme in training efficiently these parameters and in lowering the risk of overfitting. Here we show that this problem can be effectively solved by representing linear transformations with matrix product operators (MPO). We have tested this approach in five main neural networks, including FC2, LeNet-5, VGG, ResNet, and DenseNet on two widely used datasets, namely MNIST and CIFAR-10, and found that this MPO representation indeed sets up a faithful and efficient mapping between input and output signals, which can keep or even improve the prediction accuracy with dramatically reduced number of parameters.
Tree Tensor Networks for Generative Modeling
Jan 08, 2019
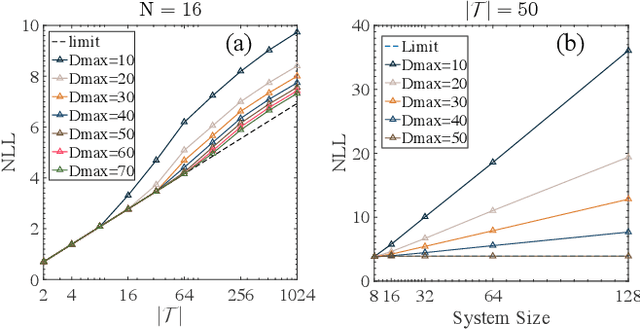

Matrix product states (MPS), a tensor network designed for one-dimensional quantum systems, has been recently proposed for generative modeling of natural data (such as images) in terms of `Born machine'. However, the exponential decay of correlation in MPS restricts its representation power heavily for modeling complex data such as natural images. In this work, we push forward the effort of applying tensor networks to machine learning by employing the Tree Tensor Network (TTN) which exhibits balanced performance in expressibility and efficient training and sampling. We design the tree tensor network to utilize the 2-dimensional prior of the natural images and develop sweeping learning and sampling algorithms which can be efficiently implemented utilizing Graphical Processing Units (GPU). We apply our model to random binary patterns and the binary MNIST datasets of handwritten digits. We show that TTN is superior to MPS for generative modeling in keeping correlation of pixels in natural images, as well as giving better log-likelihood scores in standard datasets of handwritten digits. We also compare its performance with state-of-the-art generative models such as the Variational AutoEncoders, Restricted Boltzmann machines, and PixelCNN. Finally, we discuss the future development of Tensor Network States in machine learning problems.
Equivalence of restricted Boltzmann machines and tensor network states
Feb 05, 2018

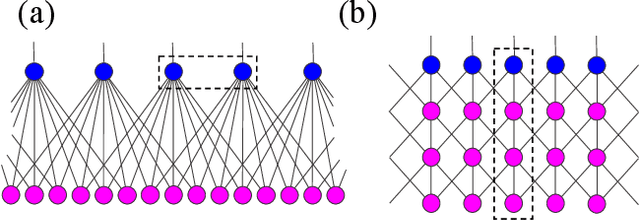

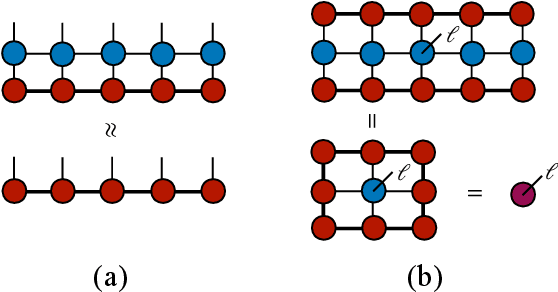
The restricted Boltzmann machine (RBM) is one of the fundamental building blocks of deep learning. RBM finds wide applications in dimensional reduction, feature extraction, and recommender systems via modeling the probability distributions of a variety of input data including natural images, speech signals, and customer ratings, etc. We build a bridge between RBM and tensor network states (TNS) widely used in quantum many-body physics research. We devise efficient algorithms to translate an RBM into the commonly used TNS. Conversely, we give sufficient and necessary conditions to determine whether a TNS can be transformed into an RBM of given architectures. Revealing these general and constructive connections can cross-fertilize both deep learning and quantum many-body physics. Notably, by exploiting the entanglement entropy bound of TNS, we can rigorously quantify the expressive power of RBM on complex data sets. Insights into TNS and its entanglement capacity can guide the design of more powerful deep learning architectures. On the other hand, RBM can represent quantum many-body states with fewer parameters compared to TNS, which may allow more efficient classical simulations.
* 18 pages, 12 figures + 2 appendices; Code implementations at https://github.com/yzcj105/rbm2mps
Information Perspective to Probabilistic Modeling: Boltzmann Machines versus Born Machines
Dec 12, 2017
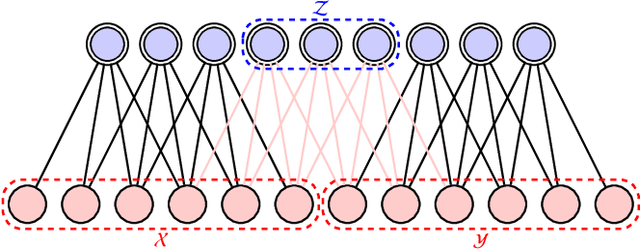
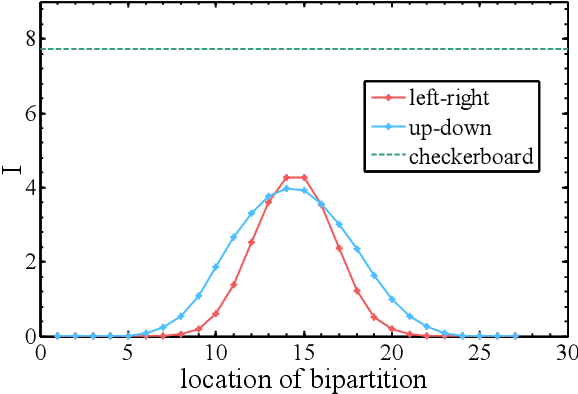
We compare and contrast the statistical physics and quantum physics inspired approaches for unsupervised generative modeling of classical data. The two approaches represent probabilities of observed data using energy-based models and quantum states respectively.Classical and quantum information patterns of the target datasets therefore provide principled guidelines for structural design and learning in these two approaches. Taking the restricted Boltzmann machines (RBM) as an example, we analyze the information theoretical bounds of the two approaches. We verify our reasonings by comparing the performance of RBMs of various architectures on the standard MNIST datasets.
* 7 pages, 4 figures