 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropPruning for Model Compression
Dec 05, 2018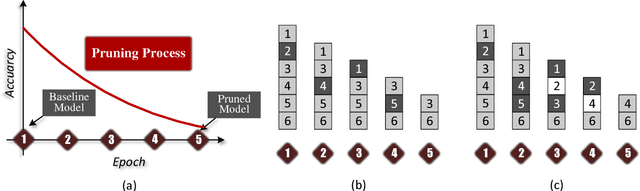

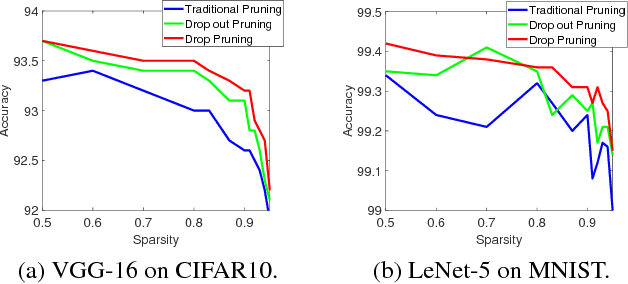
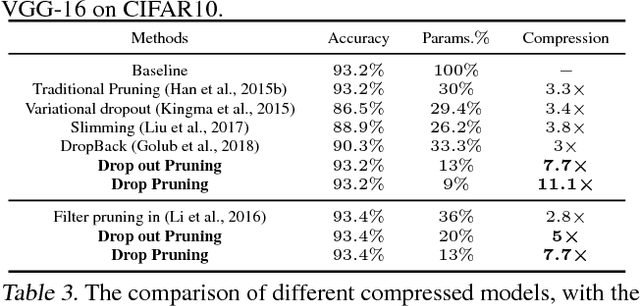
Deep neural networks (DNNs) have dramatically achieved great success on a variety of challenging tasks. However, most of the successful DNNs are structurally so complex, leading to much storage requirement and floating-point operation. This paper proposes a novel technique, named Drop Pruning, to compress the DNNs by pruning the weights from a dense high-accuracy baseline model without accuracy loss. Drop Pruning also falls into the standard iterative prune-retrain procedure, where a \emph{drop} strategy exists at each pruning step: \emph{drop out}, stochastic deleting some unimportant weights and \emph{drop in}, stochastic recovering some pruned weights. \emph{Drop out} and \emph{drop in} are supposed to handle the two drawbacks of the traditional pruning methods: local importance judgment and irretrievable pruning process, respectively. The suitable choosing of \emph{drop} probabilities can decrease the model size during pruning process and lead it to flow to the target sparsity. Drop Pruning also has some similar spirits with dropout, a stochastic algorithm in Integer Optimization and the Dense-Sparse-Dense training technique. Drop Pruning can significantly reducing overfitting while compressing the model. Experimental results demonstrates that Drop Pruning can achieve the state-of-the-art performance on many benchmark pruning tasks, about ${11.1\times}$ compression of VGG-16 on CIFAR10 and ${14.3\times}$ compression of LeNet-5 on MNIST without accuracy loss, which may provide some new insights into the aspect of model compression.