 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Text-Image Joint Embedding for Efficient Cross-Modal Retrieval with Deep Feature Engineering
Paper and Code
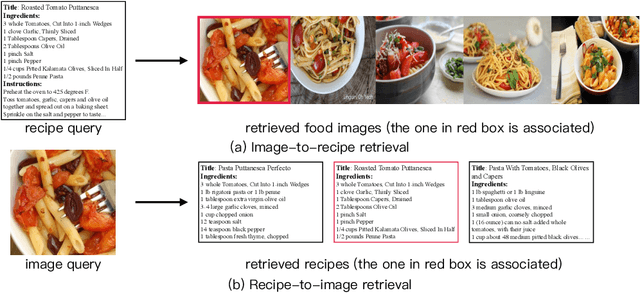
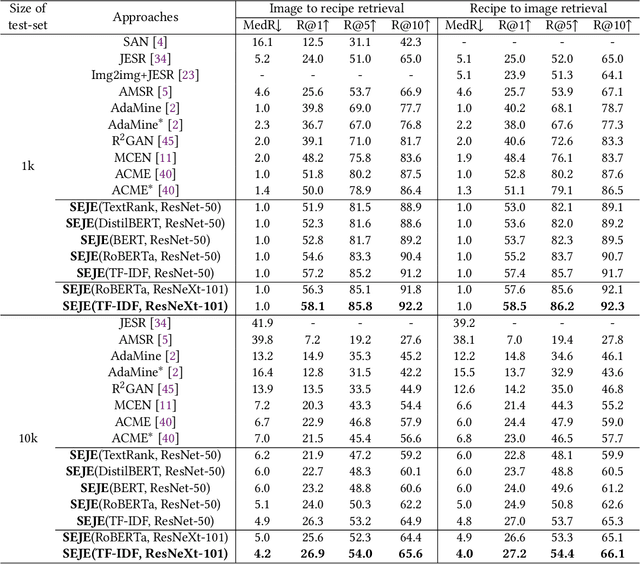
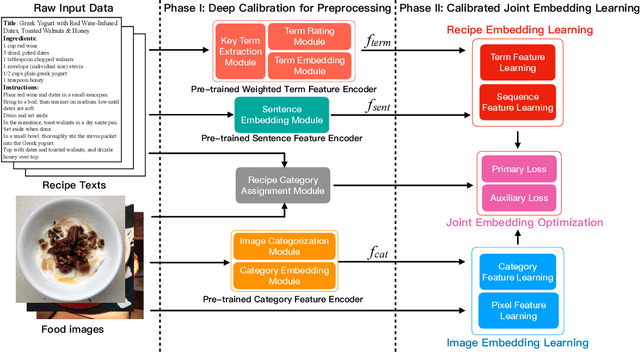
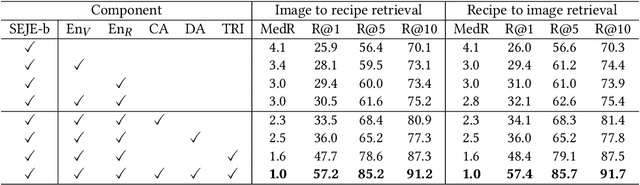
This paper introduces a two-phase deep feature engineering framework for efficient learning of semantics enhanced joint embedding, which clearly separates the deep feature engineering in data preprocessing from training the text-image joint embedding model. We use the Recipe1M dataset for the technical description and empirical validation. In preprocessing, we perform deep feature engineering by combining deep feature engineering with semantic context features derived from raw text-image input data. We leverage LSTM to identify key terms, deep NLP models from the BERT family, TextRank, or TF-IDF to produce ranking scores for key terms before generating the vector representation for each key term by using word2vec. We leverage wideResNet50 and word2vec to extract and encode the image category semantics of food images to help semantic alignment of the learned recipe and image embeddings in the joint latent space. In joint embedding learning, we perform deep feature engineering by optimizing the batch-hard triplet loss function with soft-margin and double negative sampling, taking into account also the category-based alignment loss and discriminator-based alignment loss. Extensive experiments demonstrate that our SEJE approach with deep feature engineering significantly outperforms the state-of-the-art approaches.