 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrain-Informed Speech Separation for Cochlear Implants
Jan 29, 2026We propose a brain-informed speech separation method for cochlear implants (CIs) that uses electroencephalography (EEG)-derived attention cues to guide enhancement toward the attended speaker. An attention-guided network fuses audio mixtures with EEG features through a lightweight fusion layer, producing attended-source electrodograms for CI stimulation while resolving the label-permutation ambiguity of audio-only separators. Robustness to degraded attention cues is improved with a mixed curriculum that varies cue quality during training, yielding stable gains even when EEG-speech correlation is moderate. In multi-talker conditions, the model achieves higher signal-to-interference ratio improvements than an audio-only electrodogram baseline while remaining slightly smaller (167k vs. 171k parameters). With 2 ms algorithmic latency and comparable cost, the approach highlights the promise of coupling auditory and neural cues for cognitively adaptive CI processing.
A computational loudness model for electrical stimulation with cochlear implants
Jan 29, 2025Cochlear implants (CIs) are devices that restore the sense of hearing in people with severe sensorineural hearing loss. An electrode array inserted in the cochlea bypasses the natural transducer mechanism that transforms mechanical sound waves into neural activity by artificially stimulating the auditory nerve fibers with electrical pulses. The perception of sounds is possible because the brain extracts features from this neural activity, and loudness is among the most fundamental perceptual features. A computational model that uses a three-dimensional (3D) representation of the peripheral auditory system of CI users was developed to predict categorical loudness from the simulated peripheral neural activity. In contrast, current state-of-the-art computational loudness models predict loudness from the electrical pulses with minimal parametrization of the electrode-nerve interface. In the proposed model, the spikes produced in a population of auditory nerve fibers were grouped by cochlear places, a physiological representation of the auditory filters in psychoacoustics, to be transformed into loudness contribution. Then, a loudness index was obtained with a spatiotemporal integration over this loudness contribution. This index served to define the simulated threshold of hearing (THL) and most comfortable loudness (MCL) levels resembling the growth function in CI users. The performance of real CI users in loudness summation experiments was also used to validate the computational model. These experiments studied the effect of stimulation rate, electrode separation and amplitude modulation. The proposed model provides a new set of perceptual features that can be used in computational frameworks for CIs and narrows the gap between simulations and the human peripheral neural activity.
Cortical Temporal Mismatch Compensation in Bimodal Cochlear Implant Users: Selective Attention Decoding and Pupillometry Study
Jan 28, 2025



Bimodal stimulation, combining cochlear implant (CI) and acoustic input from the opposite ear, typically enhances speech perception but varies due to factors like temporal mismatch. Previously, we used cortical auditory evoked potentials (CAEPs) to estimate this mismatch based on N1 latency differences. This study expands on that by assessing the impact of temporal mismatch compensation on speech perception. We tested bimodal CI users in three conditions: clinical, compensated temporal mismatch, and a 50 ms mismatch. Measures included speech understanding, pupillometry, CAEPs, selective attention decoding, and parietal alpha power. Despite stable speech understanding across conditions, neural measures showed stronger effects. CAEP N1P2 amplitudes were highest in the compensated condition. Phase-locking value (PLV) and selective attention decoding improved but lacked significance. Parietal alpha power increased under 50 ms mismatch, suggesting cognitive resource allocation. Pupillometry correlated with speech understanding but showed limited sensitivity. Findings highlight that neural metrics are more sensitive than behavioral tests for detecting interaural mismatch. While CAEP N1P2 amplitudes significantly improved with compensation, other neural measures showed limited effects, suggesting the need for combined temporal and spectral compensation strategies.
A Computational Model of the Electrically or Acoustically Evoked Compound Action Potential in Cochlear Implant Users with Residual Hearing
Feb 12, 2024
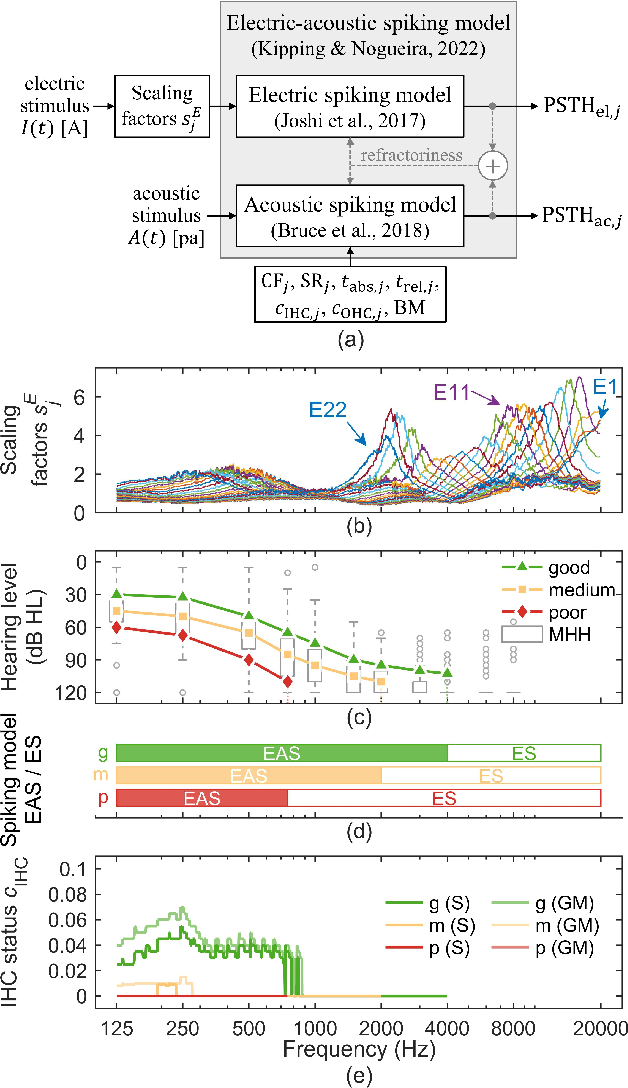


Objective: In cochlear implant (CI) users with residual acoustic hearing, compound action potentials (CAPs) can be evoked by acoustic or electric stimulation and recorded through the electrodes of the CI. We propose a novel computational model to simulate electrically and acoustically evoked CAPs in humans, taking into account the interaction between combined electric-acoustic stimulation that occurs at the level of the auditory nerve. Methods: The model consists of three components: a 3D finite element method model of an implanted cochlea, a phenomenological single-neuron spiking model for electric-acoustic stimulation, and a physiological multi-compartment neuron model to simulate the individual nerve fiber contributions to the CAP. Results: The CAP morphologies predicted for electric pulses and for acoustic clicks, chirps, and tone bursts closely resembled those known from humans. The spread of excitation derived from electrically evoked CAPs by varying the recording electrode along the CI electrode array was consistent with published human data. The predicted CAP amplitude growth functions for both electric and acoustic stimulation largely resembled human data, with deviations in absolute CAP amplitudes for acoustic stimulation. The model reproduced the suppression of electrically evoked CAPs by simultaneously presented acoustic tone bursts for different masker frequencies and probe stimulation electrodes. Conclusion: The proposed model can simulate CAP responses to electric, acoustic, or combined electric-acoustic stimulation. It takes into account the dependence on stimulation and recording sites in the cochlea, as well as the interaction between electric and acoustic stimulation. Significance: The model can be used in the future to investigate objective methods, such as hearing threshold assessment or estimation of neural health through electrically or acoustically evoked CAPs.
A Fused Deep Denoising Sound Coding Strategy for Bilateral Cochlear Implants
Oct 02, 2023



Cochlear implants (CIs) provide a solution for individuals with severe sensorineural hearing loss to regain their hearing abilities. When someone experiences this form of hearing impairment in both ears, they may be equipped with two separate CI devices, which will typically further improve the CI benefits. This spatial hearing is particularly crucial when tackling the challenge of understanding speech in noisy environments, a common issue CI users face. Currently, extensive research is dedicated to developing algorithms that can autonomously filter out undesired background noises from desired speech signals. At present, some research focuses on achieving end-to-end denoising, either as an integral component of the initial CI signal processing or by fully integrating the denoising process into the CI sound coding strategy. This work is presented in the context of bilateral CI (BiCI) systems, where we propose a deep-learning-based bilateral speech enhancement model that shares information between both hearing sides. Specifically, we connect two monaural end-to-end deep denoising sound coding techniques through intermediary latent fusion layers. These layers amalgamate the latent representations generated by these techniques by multiplying them together, resulting in an enhanced ability to reduce noise and improve learning generalization. The objective instrumental results demonstrate that the proposed fused BiCI sound coding strategy achieves higher interaural coherence, superior noise reduction, and enhanced predicted speech intelligibility scores compared to the baseline methods. Furthermore, our speech-in-noise intelligibility results in BiCI users reveal that the deep denoising sound coding strategy can attain scores similar to those achieved in quiet conditions.
Localization of Cochlear Implant Electrodes from Cone Beam Computed Tomography using Particle Belief Propagation
Mar 18, 2021
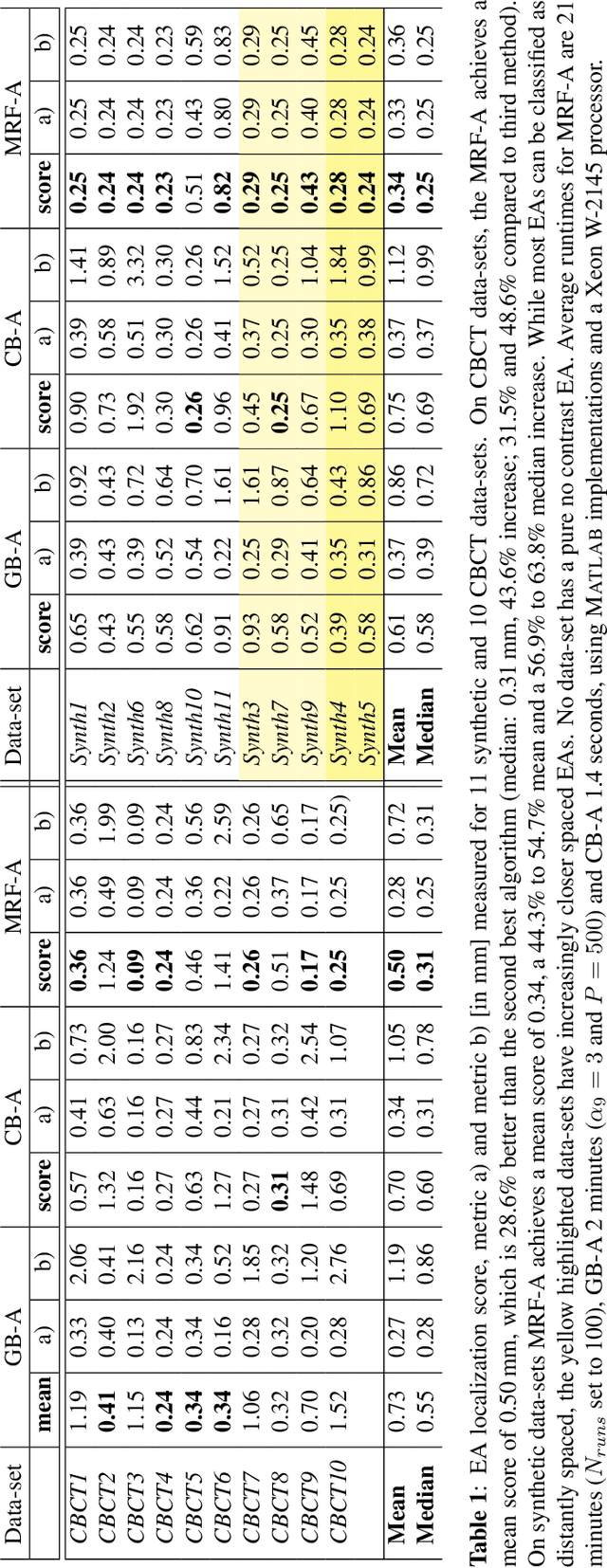
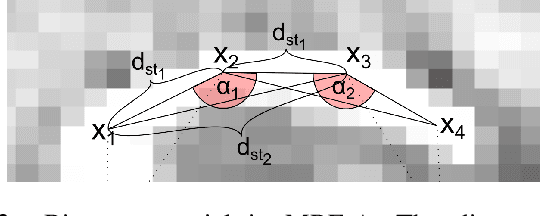
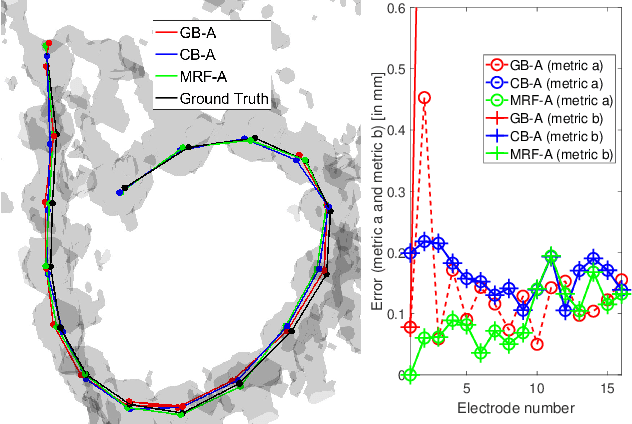
Cochlear implants (CIs) are implantable medical devices that can restore the hearing sense of people suffering from profound hearing loss. The CI uses a set of electrode contacts placed inside the cochlea to stimulate the auditory nerve with current pulses. The exact location of these electrodes may be an important parameter to improve and predict the performance with these devices. Currently the methods used in clinics to characterize the geometry of the cochlea as well as to estimate the electrode positions are manual, error-prone and time consuming. We propose a Markov random field (MRF) model for CI electrode localization for cone beam computed tomography (CBCT) data-sets. Intensity and shape of electrodes are included as prior knowledge as well as distance and angles between contacts. MRF inference is based on slice sampling particle belief propagation and guided by several heuristics. A stochastic search finds the best maximum a posteriori estimation among sampled MRF realizations. We evaluate our algorithm on synthetic and real CBCT data-sets and compare its performance with two state of the art algorithms. An increase of localization precision up to 31.5% (mean), or 48.6% (median) respectively, on real CBCT data-sets is shown.