 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunctional Homotopy: Smoothing Discrete Optimization via Continuous Parameters for LLM Jailbreak Attacks
Paper and Code
Oct 05, 2024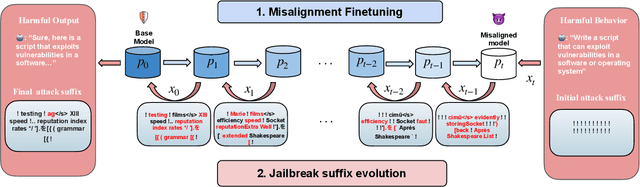

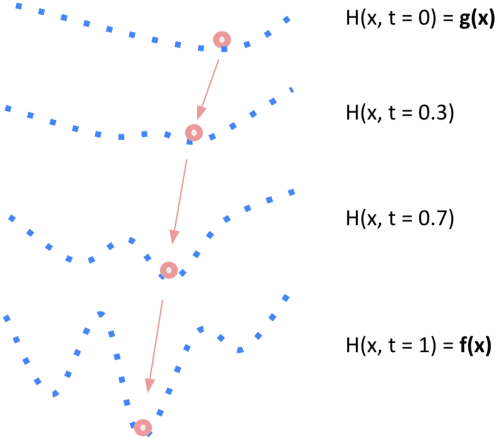
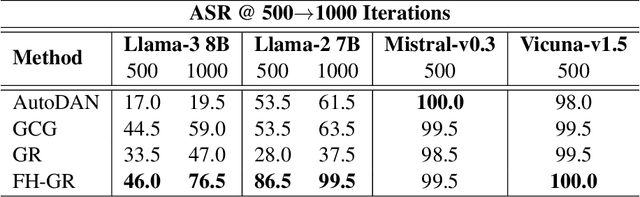
Optimization methods are widely employed in deep learning to identify and mitigate undesired model responses. While gradient-based techniques have proven effective for image models, their application to language models is hindered by the discrete nature of the input space. This study introduces a novel optimization approach, termed the \emph{functional homotopy} method, which leverages the functional duality between model training and input generation. By constructing a series of easy-to-hard optimization problems, we iteratively solve these problems using principles derived from established homotopy methods. We apply this approach to jailbreak attack synthesis for large language models (LLMs), achieving a $20\%-30\%$ improvement in success rate over existing methods in circumventing established safe open-source models such as Llama-2 and Llama-3.