 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBSUV-Net 2.0: Spatio-Temporal Data Augmentations for Video-Agnostic Supervised Background Subtraction
Feb 24, 2021
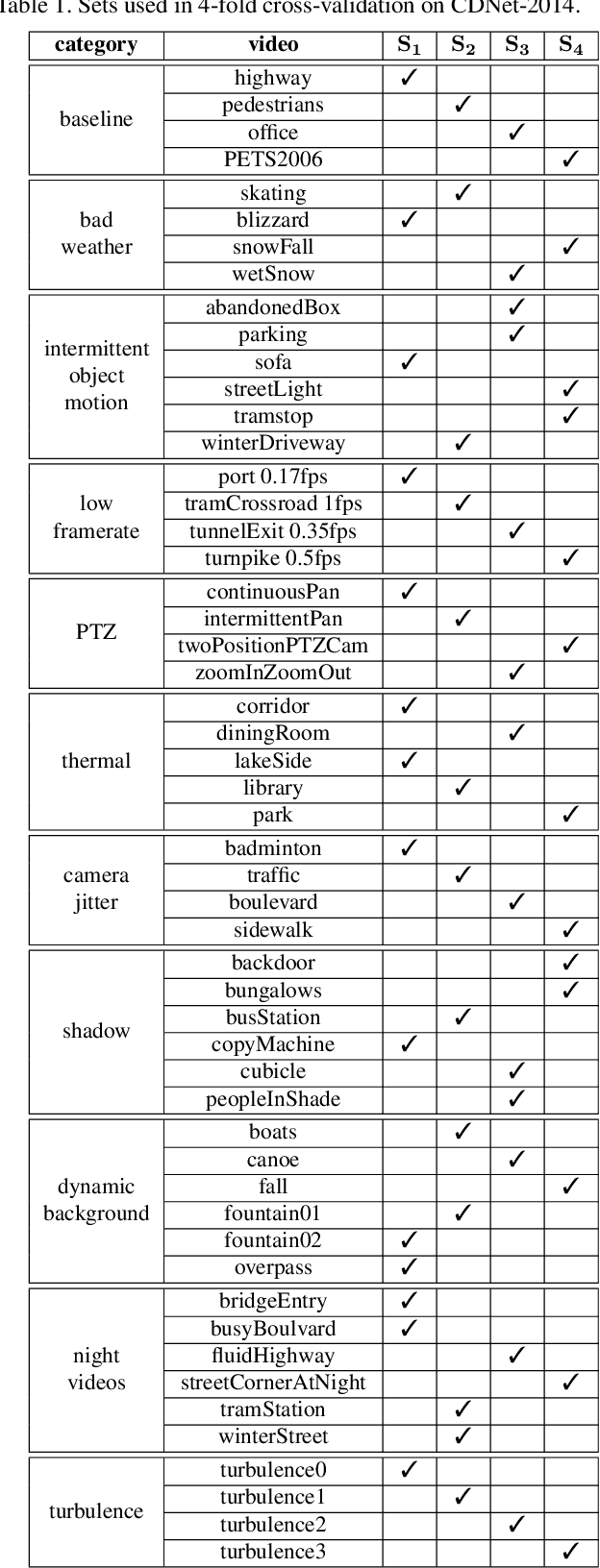
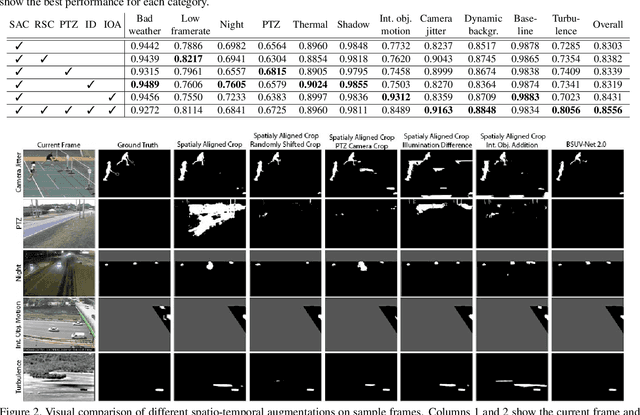
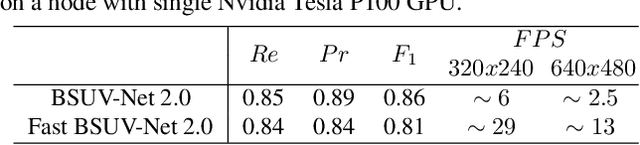
Background subtraction (BGS) is a fundamental video processing task which is a key component of many applications. Deep learning-based supervised algorithms achieve very good perforamnce in BGS, however, most of these algorithms are optimized for either a specific video or a group of videos, and their performance decreases dramatically when applied to unseen videos. Recently, several papers addressed this problem and proposed video-agnostic supervised BGS algorithms. However, nearly all of the data augmentations used in these algorithms are limited to the spatial domain and do not account for temporal variations that naturally occur in video data. In this work, we introduce spatio-temporal data augmentations and apply them to one of the leading video-agnostic BGS algorithms, BSUV-Net. We also introduce a new cross-validation training and evaluation strategy for the CDNet-2014 dataset that makes it possible to fairly and easily compare the performance of various video-agnostic supervised BGS algorithms. Our new model trained using the proposed data augmentations, named BSUV-Net 2.0, significantly outperforms state-of-the-art algorithms evaluated on unseen videos of CDNet-2014. We also evaluate the cross-dataset generalization capacity of BSUV-Net 2.0 by training it solely on CDNet-2014 videos and evaluating its performance on LASIESTA dataset. Overall, BSUV-Net 2.0 provides a ~5% improvement in the F-score over state-of-the-art methods on unseen videos of CDNet-2014 and LASIESTA datasets. Furthermore, we develop a real-time variant of our model, that we call Fast BSUV-Net 2.0, whose performance is close to the state of the art.
RAPiD: Rotation-Aware People Detection in Overhead Fisheye Images
May 23, 2020

Recent methods for people detection in overhead, fisheye images either use radially-aligned bounding boxes to represent people, assuming people always appear along image radius or require significant pre-/post-processing which radically increases computational complexity. In this work, we develop an end-to-end rotation-aware people detection method, named RAPiD, that detects people using arbitrarily-oriented bounding boxes. Our fully-convolutional neural network directly regresses the angle of each bounding box using a periodic loss function, which accounts for angle periodicities. We have also created a new dataset with spatio-temporal annotations of rotated bounding boxes, for people detection as well as other vision tasks in overhead fisheye videos. We show that our simple, yet effective method outperforms state-of-the-art results on three fisheye-image datasets. Code and dataset are available at http://vip.bu.edu/rapid .
A Fully-Convolutional Neural Network for Background Subtraction of Unseen Videos
Jul 26, 2019
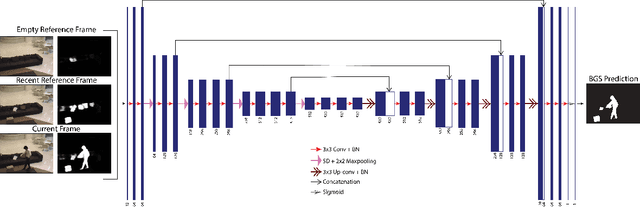
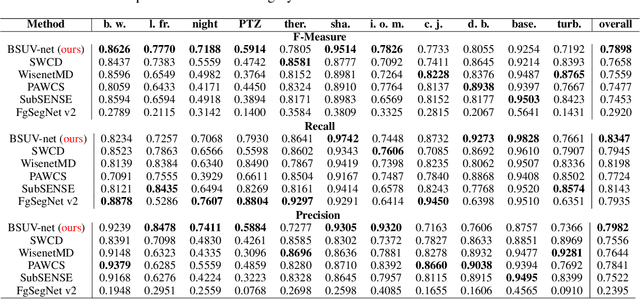

Background subtraction is a basic task in computer vision and video processing often applied as a pre-processing step for object tracking, people recognition, etc. Recently, a number of successful background subtraction algorithms have been proposed, however nearly all of the top-performing ones are supervised. Crucially, their success relies upon the availability of some annotated frames of the test video during training. Consequently, their performance on completely unseen videos is undocumented in the literature. In this work, we propose a new, supervised, background-subtraction algorithm for unseen videos (BSUV-Net) based on a fully-convolutional neural network. The input to our network consists of the current frame and two background frames captured at different time scales along with their semantic segmentation maps. In order to reduce the chance of overfitting, we also introduce a new data-augmentation technique which mitigates the impact of illumination difference between the background frames and the current frame. On the CDNet-2014 dataset, BSUV-Net outperforms state-of-the-art algorithms evaluated on unseen videos in terms of F-measure, recall and precision metrics.