 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cyclically-Trained Adversarial Network for Invariant Representation Learning
Paper and Code
Jun 21, 2019
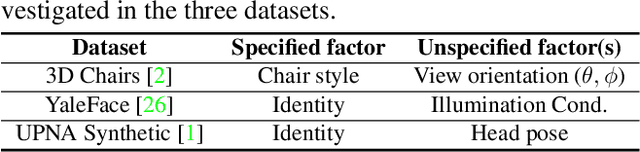
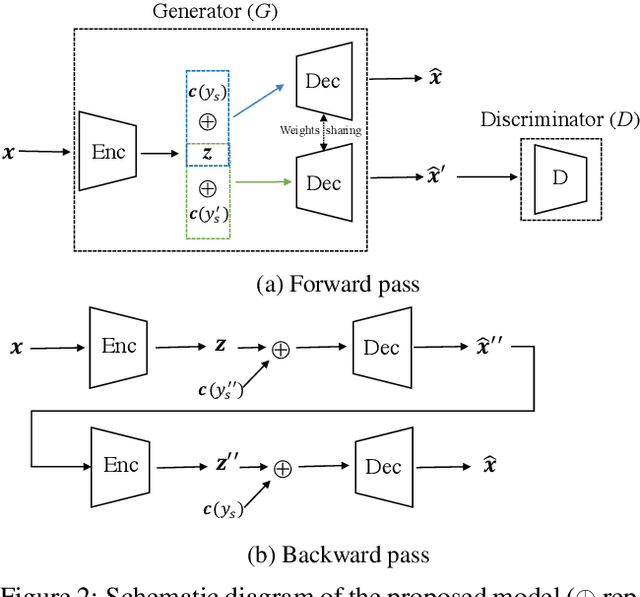
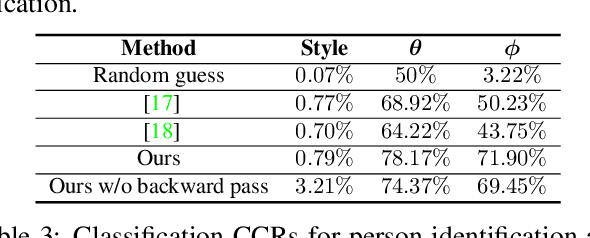
We propose a cyclically-trained adversarial network to learn mappings from image space to a latent representation space and back such that the latent representation is invariant to a specified factor of variation (e.g., identity). The learned mappings also assure that the synthesized image is not only realistic, but has the same values for unspecified factors (e.g., pose and illumination) as the original image and a desired value of the specified factor. We encourage invariance to a specified factor, by applying adversarial training using a variational autoencoder in the image space as opposed to the latent space. We strengthen this invariance by introducing a cyclic training process (forward and backward pass). We also propose a new method to evaluate conditional generative networks. It compares how well different factors of variation can be predicted from the synthesized, as opposed to real, images. We demonstrate the effectiveness of our approach on factors such as identity, pose, illumination or style on three datasets and compare it with state-of-the-art methods. Our network produces good quality synthetic images and, interestingly, can be used to perform face morphing in latent space.