 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Networks with Fast Retraining
Paper and Code
Aug 13, 2020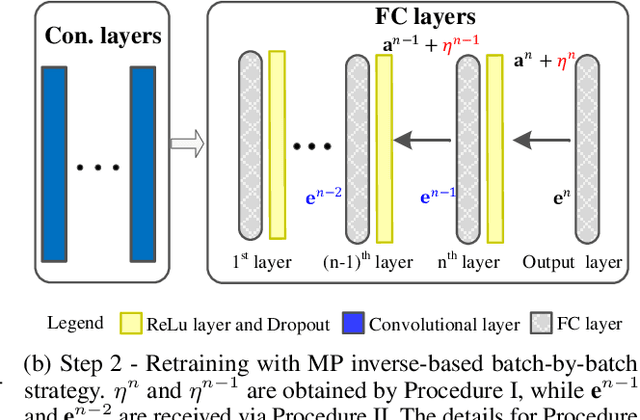
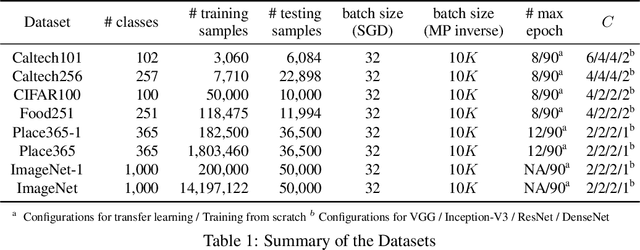
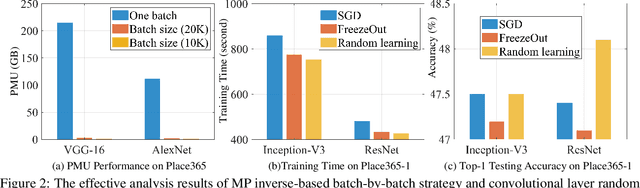
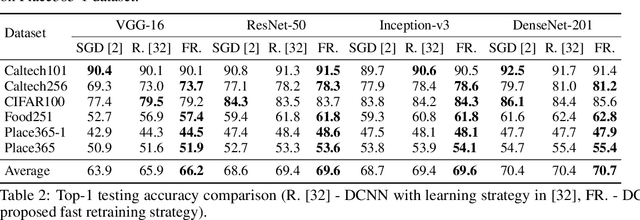
Recent wor [1] has utilized Moore-Penrose (MP) inverse in deep convolutional neural network (DCNN) training, which achieves better generalization performance over the DCNN with a stochastic gradient descent (SGD) pipeline. However, the MP technique cannot be processed in the GPU environment due to its high demands of computational resources. This paper proposes a fast DCNN learning strategy with MP inverse to achieve better testing performance without introducing a large calculation burden. We achieve this goal through an SGD and MP inverse-based two-stage training procedure. In each training epoch, a random learning strategy that controls the number of convolutional layers trained in backward pass is utilized, and an MP inverse-based batch-by-batch learning strategy is developed that enables the network to be implemented with GPU acceleration and to refine the parameters in dense layer. Through experiments on image classification datasets with various training images ranging in amount from 3,060 (Caltech101) to 1,803,460 (Place365), we empirically demonstrate that the fast retraining is a unified strategy that can be utilized in all DCNNs. Our method obtains up to 1% Top-1 testing accuracy boosts over the state-of-the-art DCNN learning pipeline, yielding a savings in training time of 15% to 25% over the work in [1]. [1] Y. Yang, J. Wu, X. Feng, and A. Thangarajah, "Recomputation of dense layers for the perfor-238mance improvement of dcnn," IEEE Trans. Pattern Anal. Mach. Intell., 2019.