 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation-Guided Representation Learning
Paper and Code
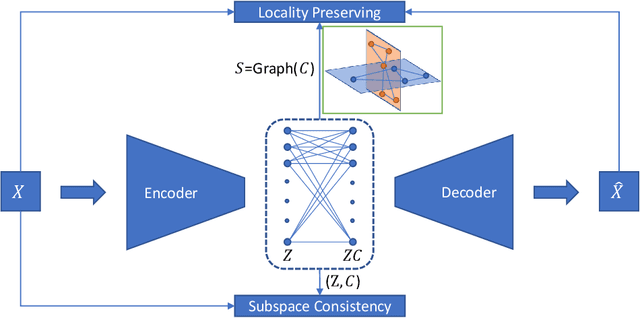



Deep auto-encoders (DAEs) have achieved great success in learning data representations via the powerful representability of neural networks. But most DAEs only focus on the most dominant structures which are able to reconstruct the data from a latent space and neglect rich latent structural information. In this work, we propose a new representation learning method that explicitly models and leverages sample relations, which in turn is used as supervision to guide the representation learning. Different from previous work, our framework well preserves the relations between samples. Since the prediction of pairwise relations themselves is a fundamental problem, our model adaptively learns them from data. This provides much flexibility to encode real data manifold. The important role of relation and representation learning is evaluated on the clustering task. Extensive experiments on benchmark data sets demonstrate the superiority of our approach. By seeking to embed samples into subspace, we further show that our method can address the large-scale and out-of-sample problem.