 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-supervised Deep Subspace Clustering
Paper and Code
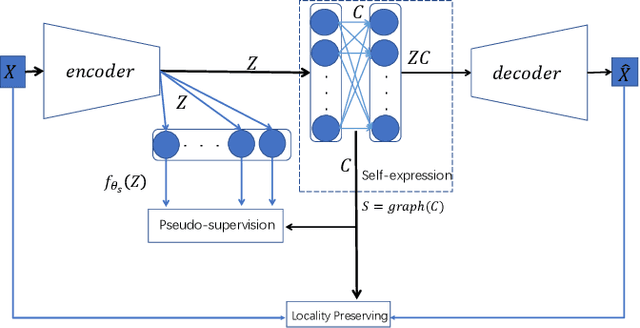
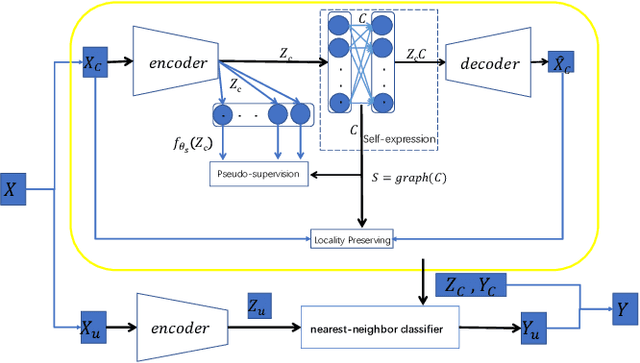
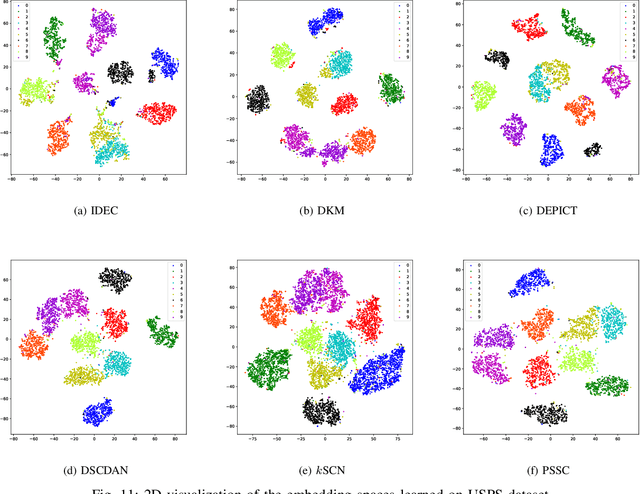
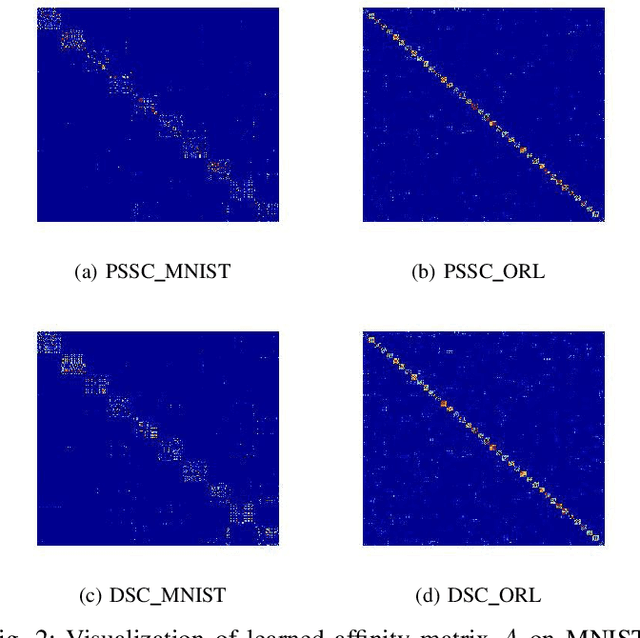
Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing categorical separability. However, self-reconstruction loss of an AE ignores rich useful relation information and might lead to indiscriminative representation, which inevitably degrades the clustering performance. It is also challenging to learn high-level similarity without feeding semantic labels. Another unsolved problem facing DSC is the huge memory cost due to $n\times n$ similarity matrix, which is incurred by the self-expression layer between an encoder and decoder. To tackle these problems, we use pairwise similarity to weigh the reconstruction loss to capture local structure information, while a similarity is learned by the self-expression layer. Pseudo-graphs and pseudo-labels, which allow benefiting from uncertain knowledge acquired during network training, are further employed to supervise similarity learning. Joint learning and iterative training facilitate to obtain an overall optimal solution. Extensive experiments on benchmark datasets demonstrate the superiority of our approach. By combining with the $k$-nearest neighbors algorithm, we further show that our method can address the large-scale and out-of-sample problems.