 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-supervised Deep Subspace Clustering
Apr 08, 2021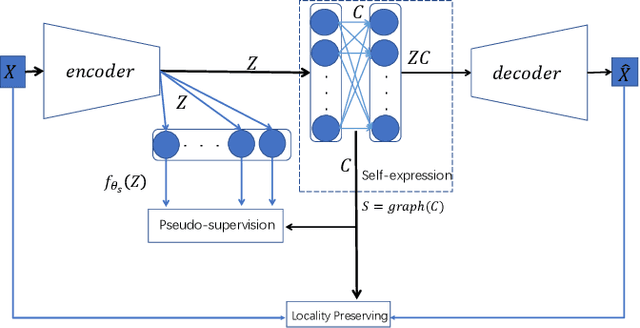
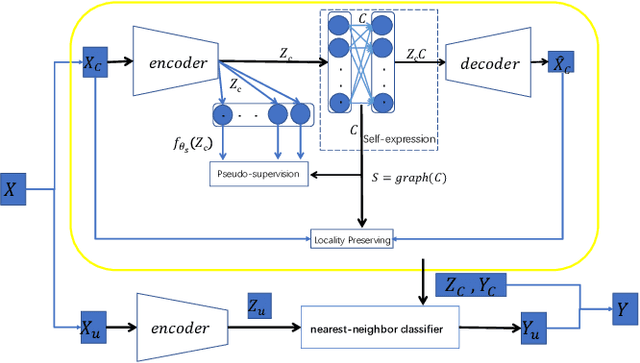
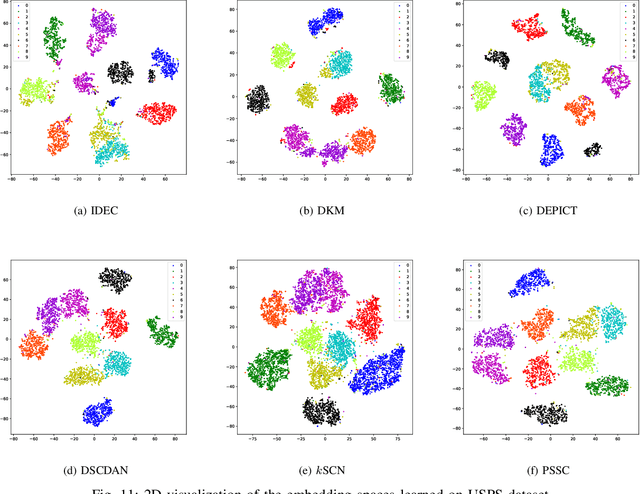
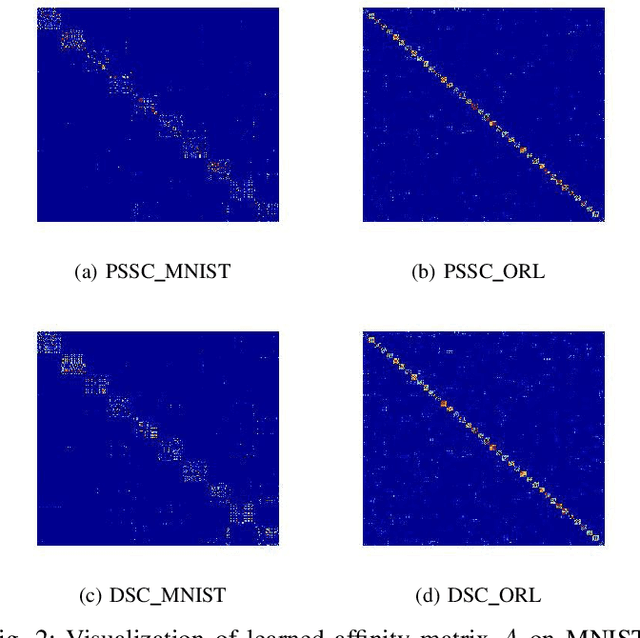
Auto-Encoder (AE)-based deep subspace clustering (DSC) methods have achieved impressive performance due to the powerful representation extracted using deep neural networks while prioritizing categorical separability. However, self-reconstruction loss of an AE ignores rich useful relation information and might lead to indiscriminative representation, which inevitably degrades the clustering performance. It is also challenging to learn high-level similarity without feeding semantic labels. Another unsolved problem facing DSC is the huge memory cost due to $n\times n$ similarity matrix, which is incurred by the self-expression layer between an encoder and decoder. To tackle these problems, we use pairwise similarity to weigh the reconstruction loss to capture local structure information, while a similarity is learned by the self-expression layer. Pseudo-graphs and pseudo-labels, which allow benefiting from uncertain knowledge acquired during network training, are further employed to supervise similarity learning. Joint learning and iterative training facilitate to obtain an overall optimal solution. Extensive experiments on benchmark datasets demonstrate the superiority of our approach. By combining with the $k$-nearest neighbors algorithm, we further show that our method can address the large-scale and out-of-sample problems.
Multi-view Subspace Clustering via Partition Fusion
Dec 03, 2019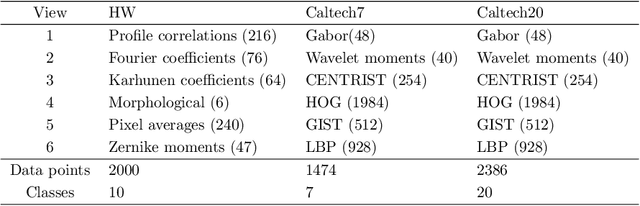
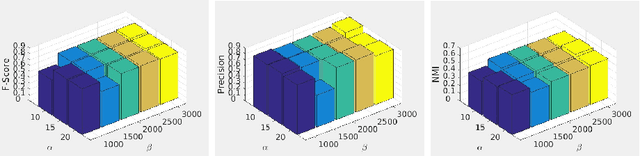
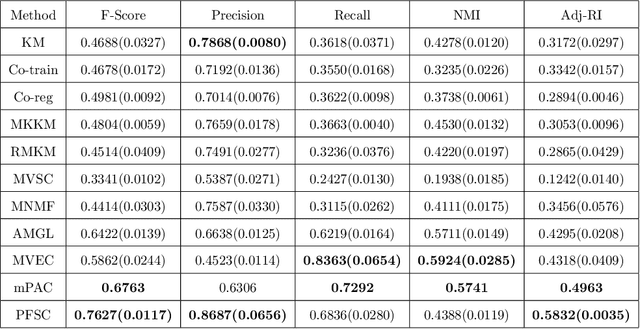
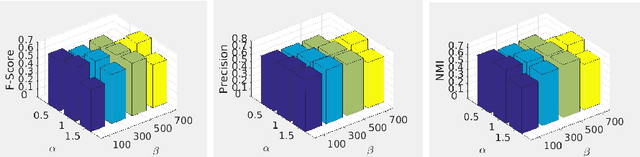
Multi-view clustering is an important approach to analyze multi-view data in an unsupervised way. Among various methods, the multi-view subspace clustering approach has gained increasing attention due to its encouraging performance. Basically, it integrates multi-view information into graphs, which are then fed into spectral clustering algorithm for final result. However, its performance may degrade due to noises existing in each individual view or inconsistency between heterogeneous features. Orthogonal to current work, we propose to fuse multi-view information in a partition space, which enhances the robustness of Multi-view clustering. Specifically, we generate multiple partitions and integrate them to find the shared partition. The proposed model unifies graph learning, generation of basic partitions, and view weight learning. These three components co-evolve towards better quality outputs. We have conducted comprehensive experiments on benchmark datasets and our empirical results verify the effectiveness and robustness of our approach.