 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioLLMAgent: A Hybrid Framework with Enhanced Structural Interpretability for Simulating Human Decision-Making in Computational Psychiatry
Mar 05, 2026Computational psychiatry faces a fundamental trade-off: traditional reinforcement learning (RL) models offer interpretability but lack behavioral realism, while large language model (LLM) agents generate realistic behaviors but lack structural interpretability. We introduce BioLLMAgent, a novel hybrid framework that combines validated cognitive models with the generative capabilities of LLMs. The framework comprises three core components: (i) an Internal RL Engine for experience-driven value learning; (ii) an External LLM Shell for high-level cognitive strategies and therapeutic interventions; and (iii) a Decision Fusion Mechanism for integrating components via weighted utility. Comprehensive experiments on the Iowa Gambling Task (IGT) across six clinical and healthy datasets demonstrate that BioLLMAgent accurately reproduces human behavioral patterns while maintaining excellent parameter identifiability (correlations $>0.67$). Furthermore, the framework successfully simulates cognitive behavioral therapy (CBT) principles and reveals, through multi-agent dynamics, that community-wide educational interventions may outperform individual treatments. Validated across reward-punishment learning and temporal discounting tasks, BioLLMAgent provides a structurally interpretable "computational sandbox" for testing mechanistic hypotheses and intervention strategies in psychiatric research.
FoSS: Modeling Long Range Dependencies and Multimodal Uncertainty in Trajectory Prediction via Fourier State Space Integration
Mar 01, 2026Accurate trajectory prediction is vital for safe autonomous driving, yet existing approaches struggle to balance modeling power and computational efficiency. Attention-based architectures incur quadratic complexity with increasing agents, while recurrent models struggle to capture long-range dependencies and fine-grained local dynamics. Building upon this, we present FoSS, a dual-branch framework that unifies frequency-domain reasoning with linear-time sequence modeling. The frequency-domain branch performs a discrete Fourier transform to decompose trajectories into amplitude components encoding global intent and phase components capturing local variations, followed by a progressive helix reordering module that preserves spectral order; two selective state-space submodules, Coarse2Fine-SSM and SpecEvolve-SSM, refine spectral features with O(N) complexity. In parallel, a time-domain dynamic selective SSM reconstructs self-attention behavior in linear time to retain long-range temporal context. A cross-attention layer fuses temporal and spectral representations, while learnable queries generate multiple candidate trajectories, and a weighted fusion head expresses motion uncertainty. Experiments on Argoverse 1 and Argoverse 2 benchmarks demonstrate that FoSS achieves state-of-the-art accuracy while reducing computation by 22.5% and parameters by over 40%. Comprehensive ablations confirm the necessity of each component.
Agentic AI Empowered Intent-Based Networking for 6G
Jan 10, 2026The transition towards sixth-generation (6G) wireless networks necessitates autonomous orchestration mechanisms capable of translating high-level operational intents into executable network configurations. Existing approaches to Intent-Based Networking (IBN) rely upon either rule-based systems that struggle with linguistic variation or end-to-end neural models that lack interpretability and fail to enforce operational constraints. This paper presents a hierarchical multi-agent framework where Large Language Model (LLM) based agents autonomously decompose natural language intents, consult domain-specific specialists, and synthesise technically feasible network slice configurations through iterative reasoning-action (ReAct) cycles. The proposed architecture employs an orchestrator agent coordinating two specialist agents, i.e., Radio Access Network (RAN) and Core Network agents, via ReAct-style reasoning, grounded in structured network state representations. Experimental evaluation across diverse benchmark scenarios shows that the proposed system outperforms rule-based systems and direct LLM prompting, with architectural principles applicable to Open RAN (O-RAN) deployments. The results also demonstrate that whilst contemporary LLMs possess general telecommunications knowledge, network automation requires careful prompt engineering to encode context-dependent decision thresholds, advancing autonomous orchestration capabilities for next-generation wireless systems.
Learning Velocity and Acceleration: Self-Supervised Motion Consistency for Pedestrian Trajectory Prediction
Mar 31, 2025Understanding human motion is crucial for accurate pedestrian trajectory prediction. Conventional methods typically rely on supervised learning, where ground-truth labels are directly optimized against predicted trajectories. This amplifies the limitations caused by long-tailed data distributions, making it difficult for the model to capture abnormal behaviors. In this work, we propose a self-supervised pedestrian trajectory prediction framework that explicitly models position, velocity, and acceleration. We leverage velocity and acceleration information to enhance position prediction through feature injection and a self-supervised motion consistency mechanism. Our model hierarchically injects velocity features into the position stream. Acceleration features are injected into the velocity stream. This enables the model to predict position, velocity, and acceleration jointly. From the predicted position, we compute corresponding pseudo velocity and acceleration, allowing the model to learn from data-generated pseudo labels and thus achieve self-supervised learning. We further design a motion consistency evaluation strategy grounded in physical principles; it selects the most reasonable predicted motion trend by comparing it with historical dynamics and uses this trend to guide and constrain trajectory generation. We conduct experiments on the ETH-UCY and Stanford Drone datasets, demonstrating that our method achieves state-of-the-art performance on both datasets.
Trajectory Mamba: Efficient Attention-Mamba Forecasting Model Based on Selective SSM
Mar 13, 2025Motion prediction is crucial for autonomous driving, as it enables accurate forecasting of future vehicle trajectories based on historical inputs. This paper introduces Trajectory Mamba, a novel efficient trajectory prediction framework based on the selective state-space model (SSM). Conventional attention-based models face the challenge of computational costs that grow quadratically with the number of targets, hindering their application in highly dynamic environments. In response, we leverage the SSM to redesign the self-attention mechanism in the encoder-decoder architecture, thereby achieving linear time complexity. To address the potential reduction in prediction accuracy resulting from modifications to the attention mechanism, we propose a joint polyline encoding strategy to better capture the associations between static and dynamic contexts, ultimately enhancing prediction accuracy. Additionally, to balance prediction accuracy and inference speed, we adopted the decoder that differs entirely from the encoder. Through cross-state space attention, all target agents share the scene context, allowing the SSM to interact with the shared scene representation during decoding, thus inferring different trajectories over the next prediction steps. Our model achieves state-of-the-art results in terms of inference speed and parameter efficiency on both the Argoverse 1 and Argoverse 2 datasets. It demonstrates a four-fold reduction in FLOPs compared to existing methods and reduces parameter count by over 40% while surpassing the performance of the vast majority of previous methods. These findings validate the effectiveness of Trajectory Mamba in trajectory prediction tasks.
Resource-Efficient Affordance Grounding with Complementary Depth and Semantic Prompts
Mar 04, 2025Affordance refers to the functional properties that an agent perceives and utilizes from its environment, and is key perceptual information required for robots to perform actions. This information is rich and multimodal in nature. Existing multimodal affordance methods face limitations in extracting useful information, mainly due to simple structural designs, basic fusion methods, and large model parameters, making it difficult to meet the performance requirements for practical deployment. To address these issues, this paper proposes the BiT-Align image-depth-text affordance mapping framework. The framework includes a Bypass Prompt Module (BPM) and a Text Feature Guidance (TFG) attention selection mechanism. BPM integrates the auxiliary modality depth image directly as a prompt to the primary modality RGB image, embedding it into the primary modality encoder without introducing additional encoders. This reduces the model's parameter count and effectively improves functional region localization accuracy. The TFG mechanism guides the selection and enhancement of attention heads in the image encoder using textual features, improving the understanding of affordance characteristics. Experimental results demonstrate that the proposed method achieves significant performance improvements on public AGD20K and HICO-IIF datasets. On the AGD20K dataset, compared with the current state-of-the-art method, we achieve a 6.0% improvement in the KLD metric, while reducing model parameters by 88.8%, demonstrating practical application values. The source code will be made publicly available at https://github.com/DAWDSE/BiT-Align.
Efficient Driving Behavior Narration and Reasoning on Edge Device Using Large Language Models
Sep 30, 2024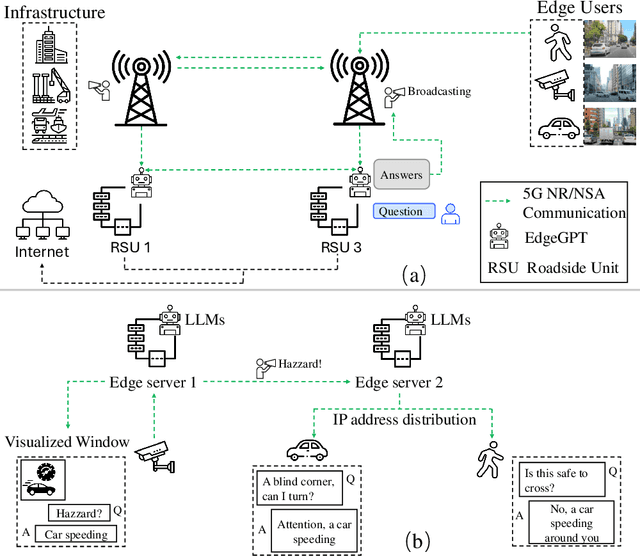
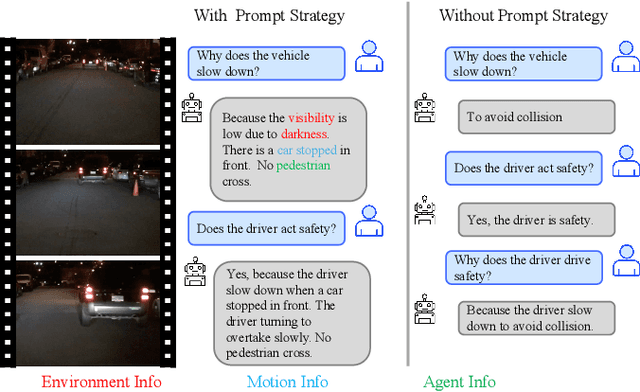
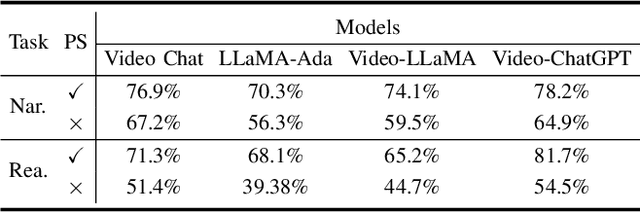
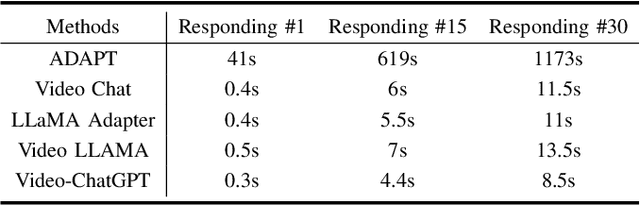
Deep learning architectures with powerful reasoning capabilities have driven significant advancements in autonomous driving technology. Large language models (LLMs) applied in this field can describe driving scenes and behaviors with a level of accuracy similar to human perception, particularly in visual tasks. Meanwhile, the rapid development of edge computing, with its advantage of proximity to data sources, has made edge devices increasingly important in autonomous driving. Edge devices process data locally, reducing transmission delays and bandwidth usage, and achieving faster response times. In this work, we propose a driving behavior narration and reasoning framework that applies LLMs to edge devices. The framework consists of multiple roadside units, with LLMs deployed on each unit. These roadside units collect road data and communicate via 5G NSR/NR networks. Our experiments show that LLMs deployed on edge devices can achieve satisfactory response speeds. Additionally, we propose a prompt strategy to enhance the narration and reasoning performance of the system. This strategy integrates multi-modal information, including environmental, agent, and motion data. Experiments conducted on the OpenDV-Youtube dataset demonstrate that our approach significantly improves performance across both tasks.
Stochastic Planning for ASV Navigation Using Satellite Images
Sep 23, 2022
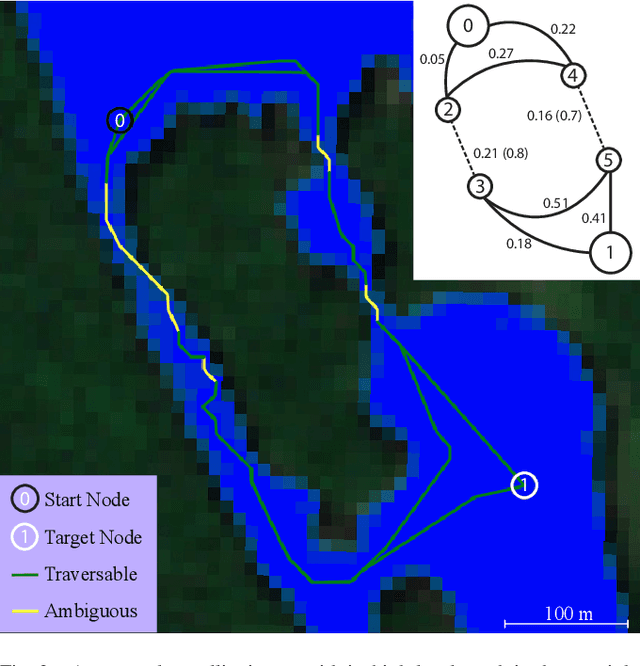
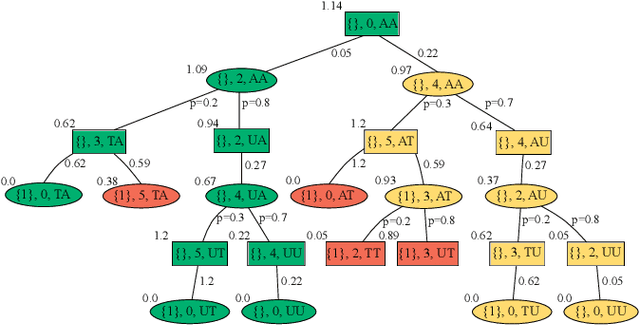
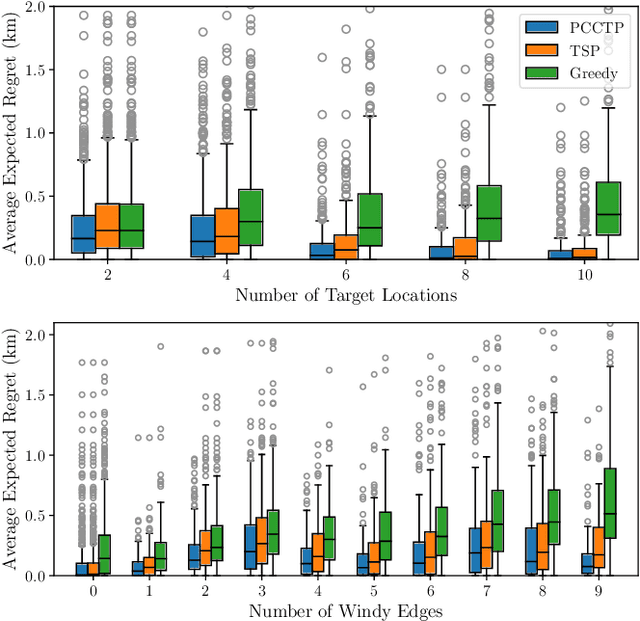
Autonomous surface vessels (ASV) represent a promising technology to automate water-quality monitoring of lakes. In this work, we use satellite images as a coarse map and plan sampling routes for the robot. However, inconsistency between the satellite images and the actual lake, as well as environmental disturbances such as wind, aquatic vegetation, and changing water levels can make it difficult for robots to visit places suggested by the prior map. This paper presents a robust route-planning algorithm that minimizes the expected total travel distance given these environmental disturbances, which induce uncertainties in the map. We verify the efficacy of our algorithm in simulations of over a thousand Canadian lakes and demonstrate an application of our algorithm in a 3.7 km-long real-world robot experiment on a lake in Northern Ontario, Canada.
Continual Model-Based Reinforcement Learning with Hypernetworks
Sep 25, 2020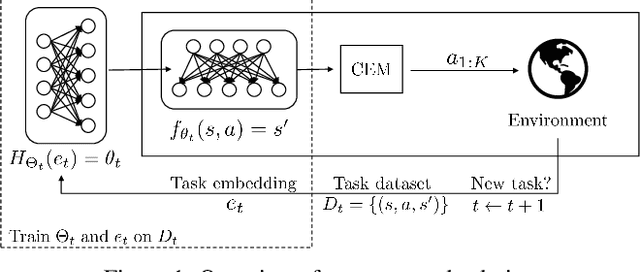

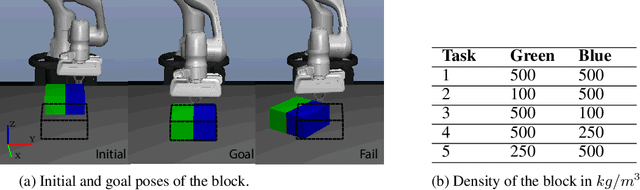
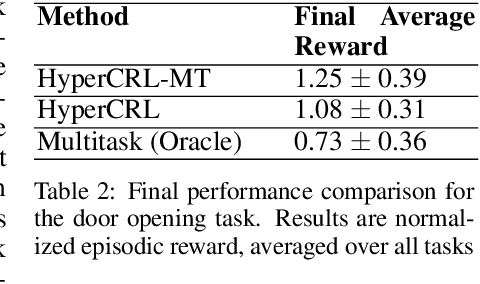
Effective planning in model-based reinforcement learning (MBRL) and model-predictive control (MPC) relies on the accuracy of the learned dynamics model. In many instances of MBRL and MPC, this model is assumed to be stationary and is periodically re-trained from scratch on state transition experience collected from the beginning of environment interactions. This implies that the time required to train the dynamics model - and the pause required between plan executions - grows linearly with the size of the collected experience. We argue that this is too slow for lifelong robot learning and propose HyperCRL, a method that continually learns the encountered dynamics in a sequence of tasks using task-conditional hypernetworks. Our method has three main attributes: first, it enables constant-time dynamics learning sessions between planning and only needs to store the most recent fixed-size portion of the state transition experience; second, it uses fixed-capacity hypernetworks to represent non-stationary and task-aware dynamics; third, it outperforms existing continual learning alternatives that rely on fixed-capacity networks, and does competitively with baselines that remember an ever increasing coreset of past experience. We show that HyperCRL is effective in continual model-based reinforcement learning in robot locomotion and manipulation scenarios, such as tasks involving pushing and door opening. Our project website with code and videos is at this link http://rvl.cs.toronto.edu/blog/2020/hypercrl/
Zeus: A System Description of the Two-Time Winner of the Collegiate SAE AutoDrive Competition
Apr 19, 2020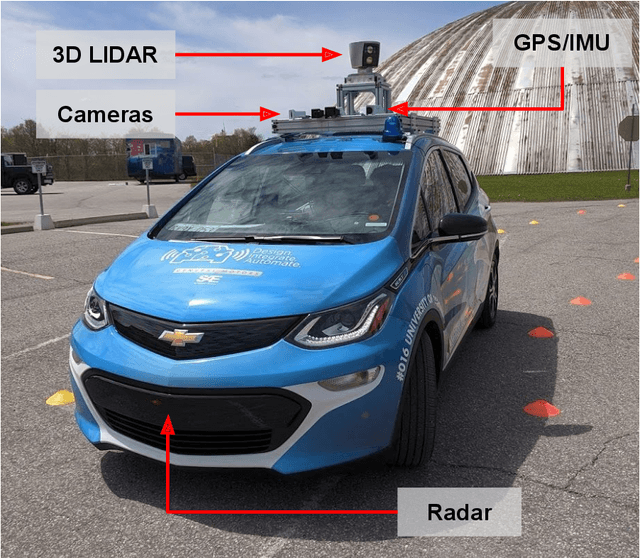


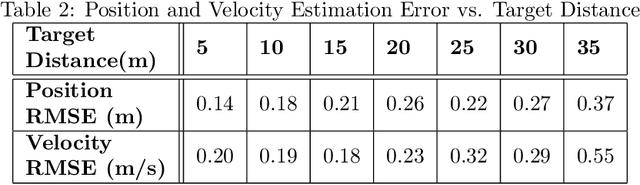
The SAE AutoDrive Challenge is a three-year collegiate competition to develop a self-driving car by 2020. The second year of the competition was held in June 2019 at MCity, a mock town built for self-driving car testing at the University of Michigan. Teams were required to autonomously navigate a series of intersections while handling pedestrians, traffic lights, and traffic signs. Zeus is aUToronto's winning entry in the AutoDrive Challenge. This article describes the system design and development of Zeus as well as many of the lessons learned along the way. This includes details on the team's organizational structure, sensor suite, software components, and performance at the Year 2 competition. With a team of mostly undergraduates and minimal resources, aUToronto has made progress towards a functioning self-driving vehicle, in just two years. This article may prove valuable to researchers looking to develop their own self-driving platform.