 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Enhanced Reasoning Training: Activating Latent Reasoning in Small Models for Enhanced Reasoning Distillation
Paper and Code
Feb 18, 2025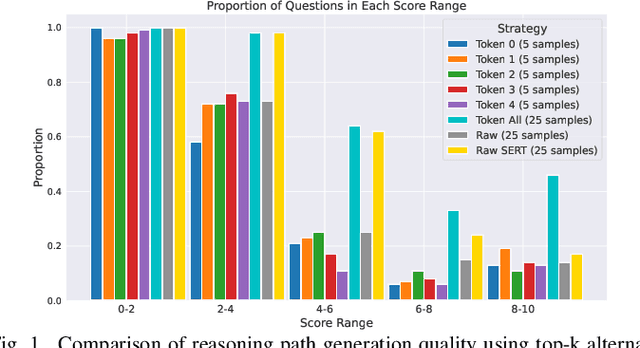

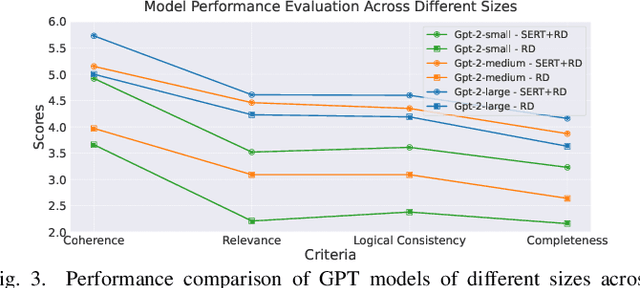
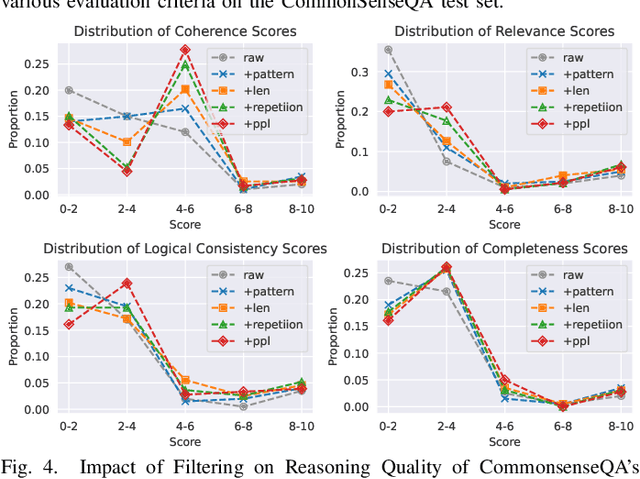
The rapid advancement of large language models (LLMs) has significantly enhanced their reasoning abilities, enabling increasingly complex tasks. However, these capabilities often diminish in smaller, more computationally efficient models like GPT-2. Recent research shows that reasoning distillation can help small models acquire reasoning capabilities, but most existing methods focus primarily on improving teacher-generated reasoning paths. Our observations reveal that small models can generate high-quality reasoning paths during sampling, even without chain-of-thought prompting, though these paths are often latent due to their low probability under standard decoding strategies. To address this, we propose Self-Enhanced Reasoning Training (SERT), which activates and leverages latent reasoning capabilities in small models through self-training on filtered, self-generated reasoning paths under zero-shot conditions. Experiments using OpenAI's GPT-3.5 as the teacher model and GPT-2 models as the student models demonstrate that SERT enhances the reasoning abilities of small models, improving their performance in reasoning distillation.