 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIMIT: Less Is More for Instruction Tuning Across Evaluation Paradigms
Nov 22, 2023

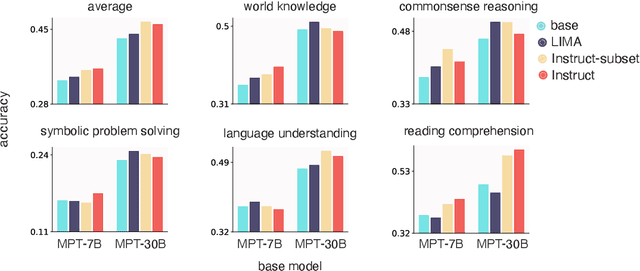
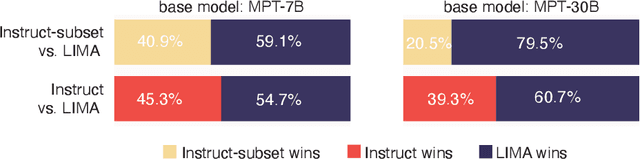
Large Language Models are traditionally finetuned on large instruction datasets. However recent studies suggest that small, high-quality datasets can suffice for general purpose instruction following. This lack of consensus surrounding finetuning best practices is in part due to rapidly diverging approaches to LLM evaluation. In this study, we ask whether a small amount of diverse finetuning samples can improve performance on both traditional perplexity-based NLP benchmarks, and on open-ended, model-based evaluation. We finetune open-source MPT-7B and MPT-30B models on instruction finetuning datasets of various sizes ranging from 1k to 60k samples. We find that subsets of 1k-6k instruction finetuning samples are sufficient to achieve good performance on both (1) traditional NLP benchmarks and (2) model-based evaluation. Finally, we show that mixing textbook-style and open-ended QA finetuning datasets optimizes performance on both evaluation paradigms.
Bayesian Active Learning for Discrete Latent Variable Models
Feb 27, 2022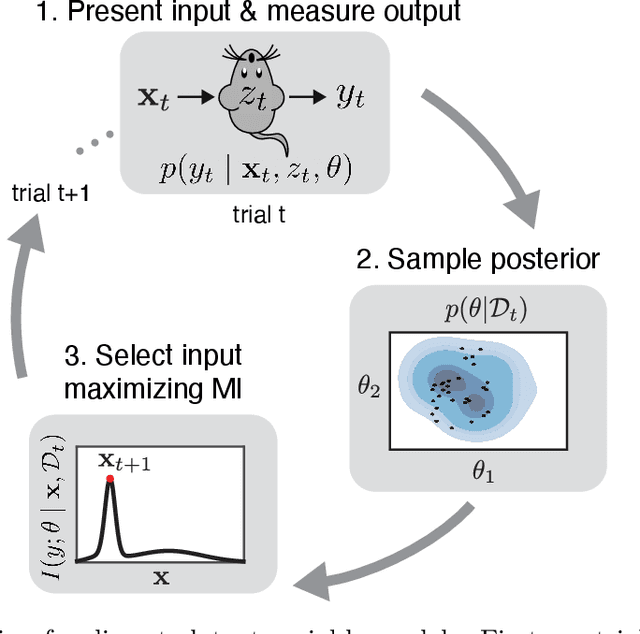
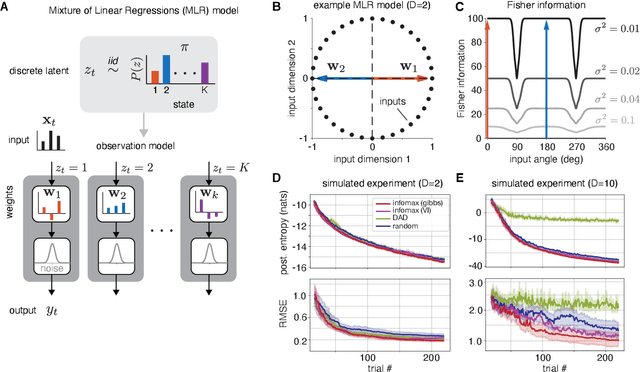
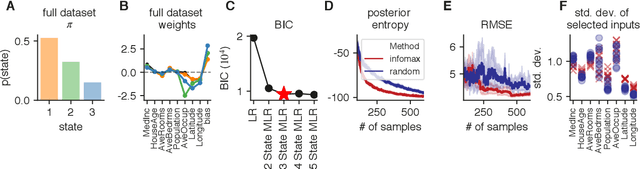
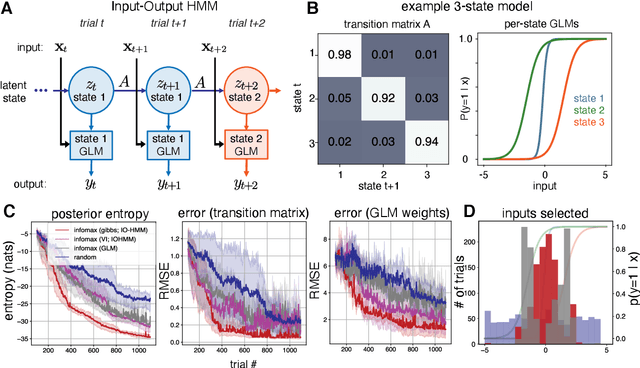
Active learning seeks to reduce the number of samples required to estimate the parameters of a model, thus forming an important class of techniques in modern machine learning. However, past work on active learning has largely overlooked latent variable models, which play a vital role in neuroscience, psychology, and a variety of other engineering and scientific disciplines. Here we address this gap in the literature and propose a novel framework for maximum-mutual-information input selection for learning discrete latent variable regression models. We first examine a class of models known as "mixtures of linear regressions" (MLR). This example is striking because it is well known that active learning confers no advantage for standard least-squares regression. However, we show -- both in simulations and analytically using Fisher information -- that optimal input selection can nevertheless provide dramatic gains for mixtures of regression models; we also validate this on a real-world application of MLRs. We then consider a powerful class of temporally structured latent variable models known as Input-Output Hidden Markov Models (IO-HMMs), which have recently gained prominence in neuroscience. We show that our method substantially speeds up learning, and outperforms a variety of approximate methods based on variational and amortized inference.
Extracting low-dimensional psychological representations from convolutional neural networks
May 29, 2020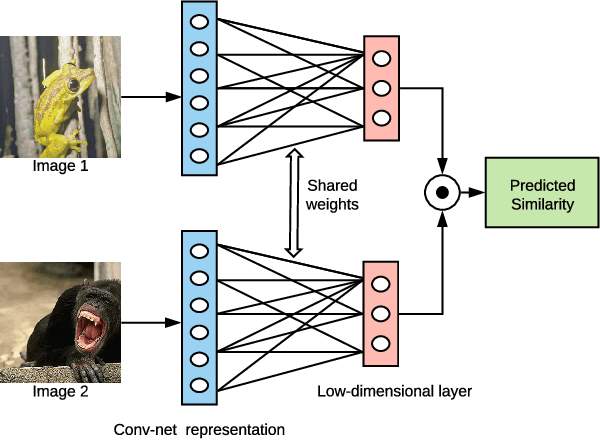
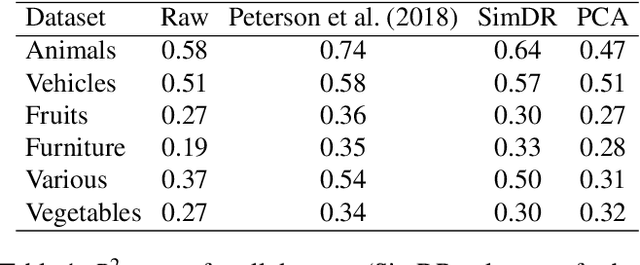
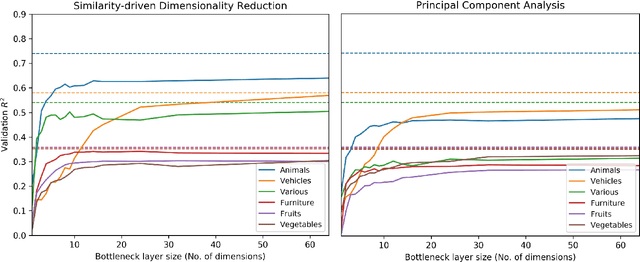
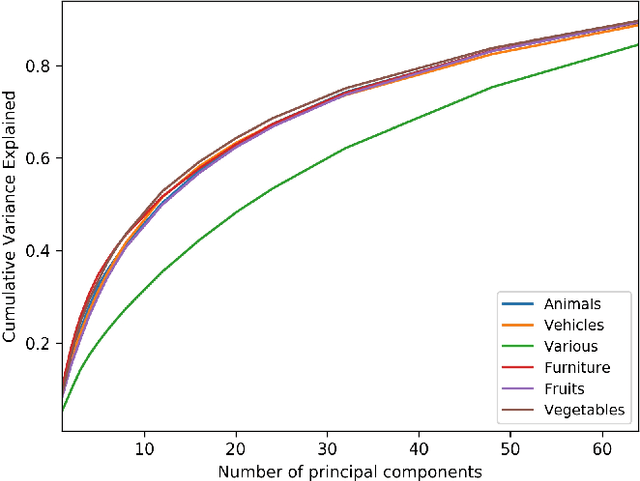
Deep neural networks are increasingly being used in cognitive modeling as a means of deriving representations for complex stimuli such as images. While the predictive power of these networks is high, it is often not clear whether they also offer useful explanations of the task at hand. Convolutional neural network representations have been shown to be predictive of human similarity judgments for images after appropriate adaptation. However, these high-dimensional representations are difficult to interpret. Here we present a method for reducing these representations to a low-dimensional space which is still predictive of similarity judgments. We show that these low-dimensional representations also provide insightful explanations of factors underlying human similarity judgments.