 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreefix: Enabling Execution with a Tree of Prefixes
Jan 21, 2025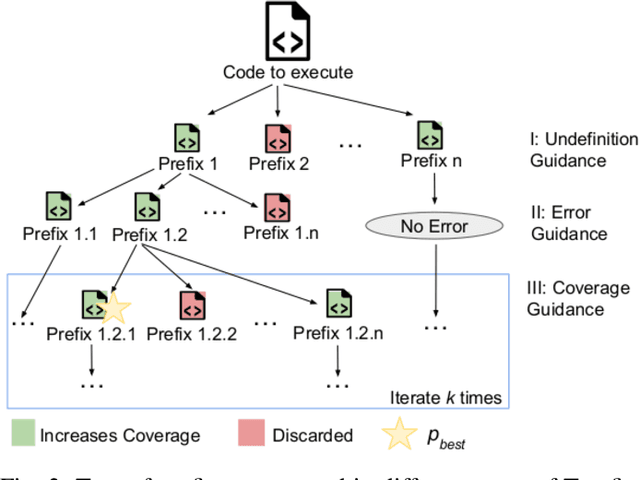



The ability to execute code is a prerequisite for various dynamic program analyses. Learning-guided execution has been proposed as an approach to enable the execution of arbitrary code snippets by letting a neural model predict likely values for any missing variables. Although state-of-the-art learning-guided execution approaches, such as LExecutor, can enable the execution of a relative high amount of code, they are limited to predicting a restricted set of possible values and do not use any feedback from previous executions to execute even more code. This paper presents Treefix, a novel learning-guided execution approach that leverages LLMs to iteratively create code prefixes that enable the execution of a given code snippet. The approach addresses the problem in a multi-step fashion, where each step uses feedback about the code snippet and its execution to instruct an LLM to improve a previously generated prefix. This process iteratively creates a tree of prefixes, a subset of which is returned to the user as prefixes that maximize the number of executed lines in the code snippet. In our experiments with two datasets of Python code snippets, Treefix achieves 25% and 7% more coverage relative to the current state of the art in learning-guided execution, covering a total of 84% and 82% of all lines in the code snippets.
LExecutor: Learning-Guided Execution
Feb 07, 2023Executing code is essential for various program analysis tasks, e.g., to detect bugs that manifest through exceptions or to obtain execution traces for further dynamic analysis. However, executing an arbitrary piece of code is often difficult in practice, e.g., because of missing variable definitions, missing user inputs, and missing third-party dependencies. This paper presents LExecutor, a learning-guided approach for executing arbitrary code snippets in an underconstrained way. The key idea is to let a neural model predict missing values that otherwise would cause the program to get stuck, and to inject these values into the execution. For example, LExecutor injects likely values for otherwise undefined variables and likely return values of calls to otherwise missing functions. We evaluate the approach on Python code from popular open-source projects and on code snippets extracted from Stack Overflow. The neural model predicts realistic values with an accuracy between 80.1% and 94.2%, allowing LExecutor to closely mimic real executions. As a result, the approach successfully executes significantly more code than any available technique, such as simply executing the code as-is. For example, executing the open-source code snippets as-is covers only 4.1% of all lines, because the code crashes early on, whereas LExecutor achieves a coverage of 50.1%.
Code Generation Tools for Free? A Study of Few-Shot, Pre-Trained Language Models on Code
Jun 02, 2022
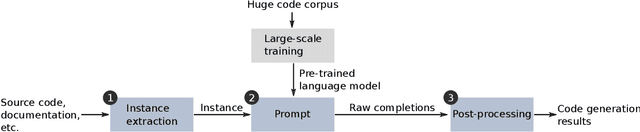

Few-shot learning with large-scale, pre-trained language models is a powerful way to answer questions about code, e.g., how to complete a given code example, or even generate code snippets from scratch. The success of these models raises the question whether they could serve as a basis for building a wide range code generation tools. Traditionally, such tools are built manually and separately for each task. Instead, few-shot learning may allow to obtain different tools from a single pre-trained language model by simply providing a few examples or a natural language description of the expected tool behavior. This paper studies to what extent a state-of-the-art, pre-trained language model of code, Codex, may serve this purpose. We consider three code manipulation and code generation tasks targeted by a range of traditional tools: (i) code mutation; (ii) test oracle generation from natural language documentation; and (iii) test case generation. For each task, we compare few-shot learning to a manually built tool. Our results show that the model-based tools complement (code mutation), are on par (test oracle generation), or even outperform their respective traditionally built tool (test case generation), while imposing far less effort to develop them. By comparing the effectiveness of different variants of the model-based tools, we provide insights on how to design an appropriate input ("prompt") to the model and what influence the size of the model has. For example, we find that providing a small natural language description of the code generation task is an easy way to improve predictions. Overall, we conclude that few-shot language models are surprisingly effective, yet there is still more work to be done, such as exploring more diverse ways of prompting and tackling even more involved tasks.