Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameterized Exploration
Paper and Code
Jul 13, 2019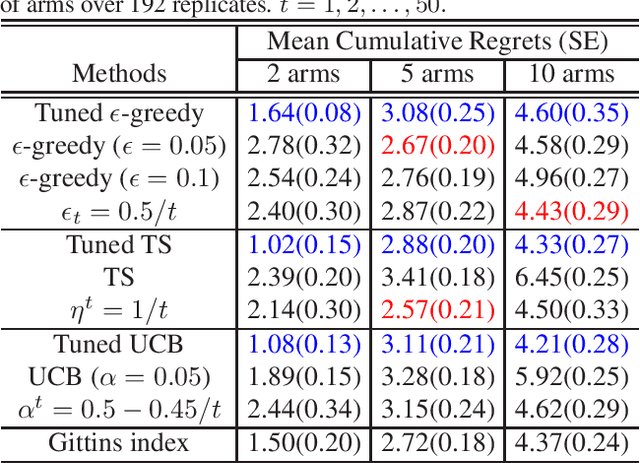
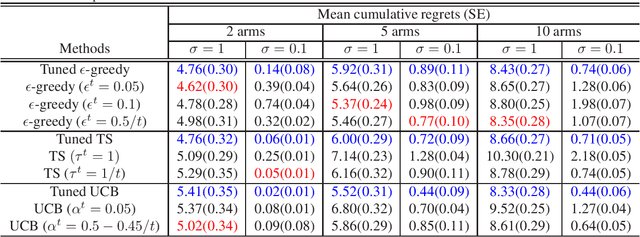

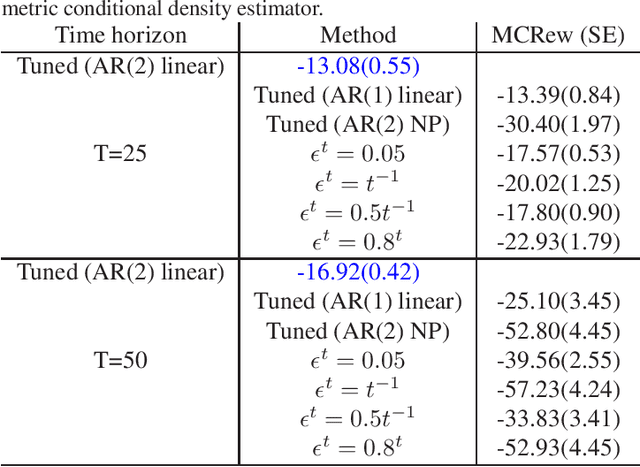
We introduce Parameterized Exploration (PE), a simple family of methods for model-based tuning of the exploration schedule in sequential decision problems. Unlike common heuristics for exploration, our method accounts for the time horizon of the decision problem as well as the agent's current state of knowledge of the dynamics of the decision problem. We show our method as applied to several common exploration techniques has superior performance relative to un-tuned counterparts in Bernoulli and Gaussian multi-armed bandits, contextual bandits, and a Markov decision process based on a mobile health (mHealth) study. We also examine the effects of the accuracy of the estimated dynamics model on the performance of PE.
View paper on