 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiMS: Distilling Multiple Steps of Iterative Non-Autoregressive Transformers
Jun 07, 2022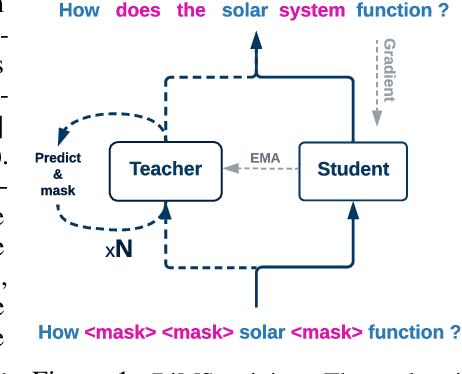
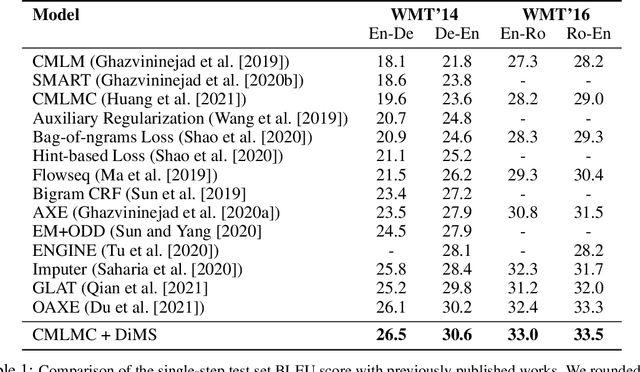
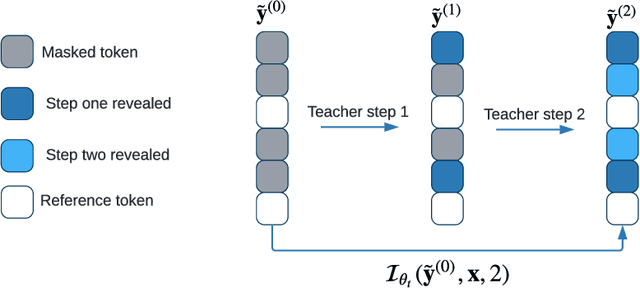

The computational benefits of iterative non-autoregressive transformers decrease as the number of decoding steps increases. As a remedy, we introduce Distill Multiple Steps (DiMS), a simple yet effective distillation technique to decrease the number of required steps to reach a certain translation quality. The distilled model enjoys the computational benefits of early iterations while preserving the enhancements from several iterative steps. DiMS relies on two models namely student and teacher. The student is optimized to predict the output of the teacher after multiple decoding steps while the teacher follows the student via a slow-moving average. The moving average keeps the teacher's knowledge updated and enhances the quality of the labels provided by the teacher. During inference, the student is used for translation and no additional computation is added. We verify the effectiveness of DiMS on various models obtaining improvements of up to 7 BLEU points on distilled and 12 BLEU points on raw WMT datasets for single-step translation. We release our code at https://github.com/layer6ai-labs/DiMS.
Semantic Parsing with Less Prior and More Monolingual Data
Jan 01, 2021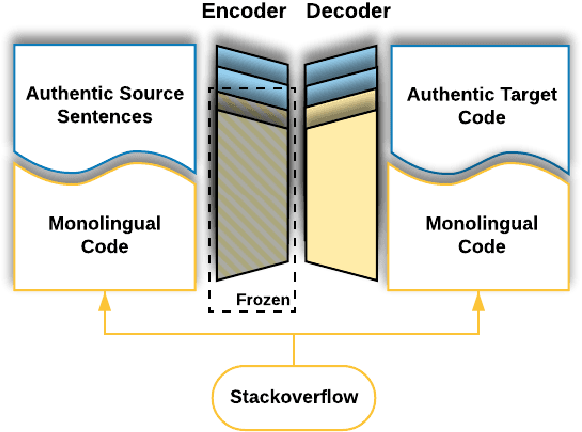

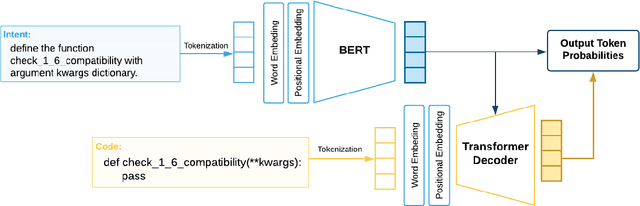

Semantic parsing is the task of converting natural language utterances to machine-understandable meaning representations, such as logic forms or programming languages. Training datasets for semantic parsing are typically small due to the higher expertise required for annotation than most other NLP tasks. As a result, models for this application usually require additional prior knowledge to be built into the architecture or algorithm. The increased dependency on human experts hinders automation and raises the development and maintenance costs in practice. This work investigates whether a generic transformer-based seq2seq model can achieve competitive performance with minimal semantic-parsing specific inductive bias design. By exploiting a relatively large monolingual corpus of the target programming language, which is cheap to mine from the web, unlike a parallel corpus, we achieved 80.75% exact match accuracy on Django and 32.57 BLEU score on CoNaLa, both are SOTA to the best of our knowledge. This positive evidence highlights a potentially easier path toward building accurate semantic parsers in the wild.
Exemplar VAEs for Exemplar based Generation and Data Augmentation
Apr 09, 2020

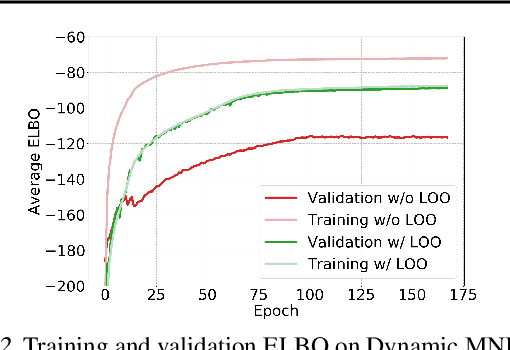
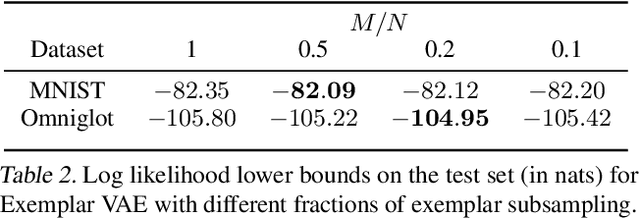
This paper presents a framework for exemplar based generative modeling, featuring Exemplar VAEs. To generate a sample from the Exemplar VAE, one first draws a random exemplar from a training dataset, and then stochastically transforms that exemplar into a latent code, which is then used to generate a new observation. We show that the Exemplar VAE can be interpreted as a VAE with a mixture of Gaussians prior in the latent space, with Gaussian means defined by the latent encoding of the exemplars. To enable optimization and avoid overfitting, Exemplar VAE's parameters are learned using leave-one-out and exemplar subsampling, where, for the generation of each data point, we build a prior based on a random subset of the remaining data points. To accelerate learning, which requires finding the exemplars that exert the greatest influence on the generation of each data point, we use approximate nearest neighbor search in the latent space, yielding a lower bound on the log marginal likelihood. Experiments demonstrate the effectiveness of Exemplar VAEs in density estimation, representation learning, and generative data augmentation for supervised learning.