 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundational Multimodal Vision Language AI Assistant for Human Pathology
Paper and Code
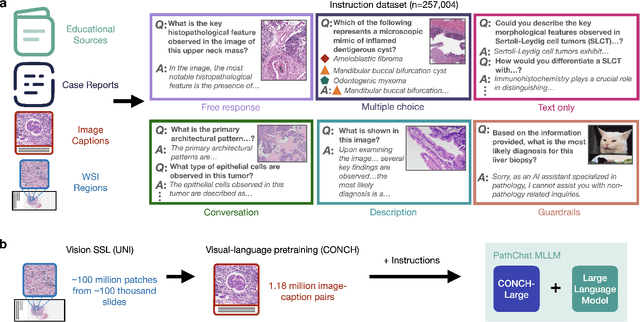
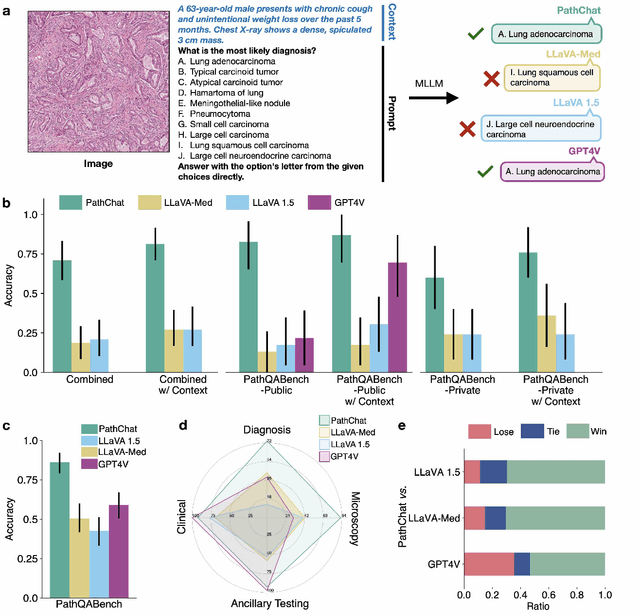
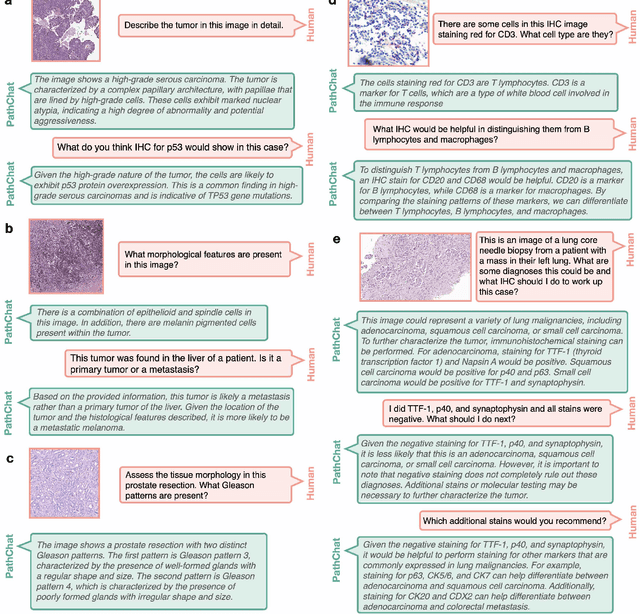

The field of computational pathology has witnessed remarkable progress in the development of both task-specific predictive models and task-agnostic self-supervised vision encoders. However, despite the explosive growth of generative artificial intelligence (AI), there has been limited study on building general purpose, multimodal AI assistants tailored to pathology. Here we present PathChat, a vision-language generalist AI assistant for human pathology using an in-house developed foundational vision encoder pretrained on 100 million histology images from over 100,000 patient cases and 1.18 million pathology image-caption pairs. The vision encoder is then combined with a pretrained large language model and the whole system is finetuned on over 250,000 diverse disease agnostic visual language instructions. We compare PathChat against several multimodal vision language AI assistants as well as GPT4V, which powers the commercially available multimodal general purpose AI assistant ChatGPT-4. When relevant clinical context is provided with the histology image, PathChat achieved a diagnostic accuracy of 87% on multiple-choice questions based on publicly available cases of diverse tissue origins and disease models. Additionally, using open-ended questions and human expert evaluation, we found that overall PathChat produced more accurate and pathologist-preferable responses to diverse queries related to pathology. As an interactive and general vision language AI assistant that can flexibly handle both visual and natural language inputs, PathChat can potentially find impactful applications in pathology education, research, and human-in-the-loop clinical decision making.