 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoiding Biased Clinical Machine Learning Model Performance Estimates in the Presence of Label Selection
Paper and Code
Sep 15, 2022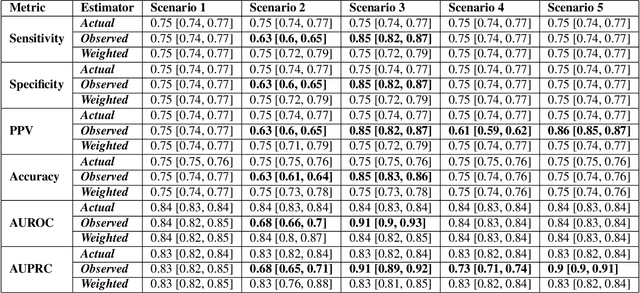

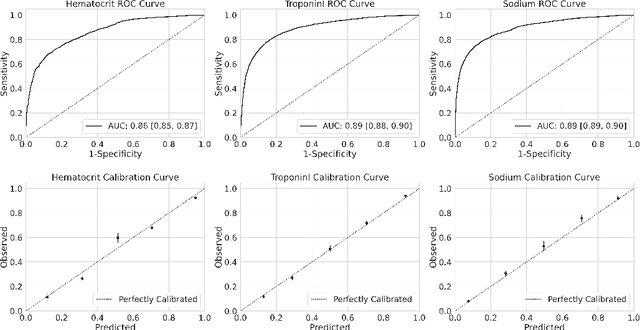

When evaluating the performance of clinical machine learning models, one must consider the deployment population. When the population of patients with observed labels is only a subset of the deployment population (label selection), standard model performance estimates on the observed population may be misleading. In this study we describe three classes of label selection and simulate five causally distinct scenarios to assess how particular selection mechanisms bias a suite of commonly reported binary machine learning model performance metrics. Simulations reveal that when selection is affected by observed features, naive estimates of model discrimination may be misleading. When selection is affected by labels, naive estimates of calibration fail to reflect reality. We borrow traditional weighting estimators from causal inference literature and find that when selection probabilities are properly specified, they recover full population estimates. We then tackle the real-world task of monitoring the performance of deployed machine learning models whose interactions with clinicians feed-back and affect the selection mechanism of the labels. We train three machine learning models to flag low-yield laboratory diagnostics, and simulate their intended consequence of reducing wasteful laboratory utilization. We find that naive estimates of AUROC on the observed population undershoot actual performance by up to 20%. Such a disparity could be large enough to lead to the wrongful termination of a successful clinical decision support tool. We propose an altered deployment procedure, one that combines injected randomization with traditional weighted estimates, and find it recovers true model performance.