 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal-Local Path Networks for Monocular Depth Estimation with Vertical CutDepth
Jan 25, 2022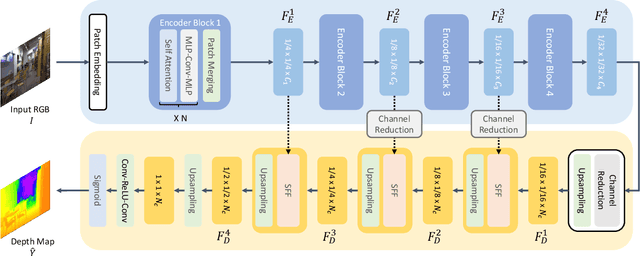
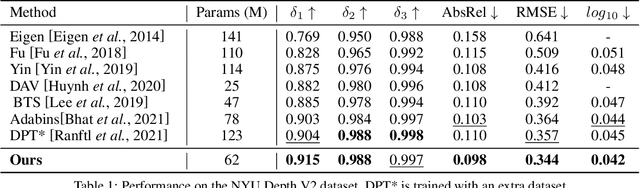
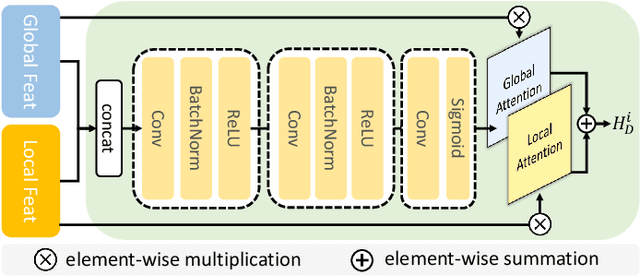
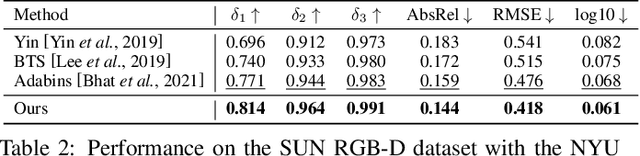
Depth estimation from a single image is an important task that can be applied to various fields in computer vision, and has grown rapidly with the development of convolutional neural networks. In this paper, we propose a novel structure and training strategy for monocular depth estimation to further improve the prediction accuracy of the network. We deploy a hierarchical transformer encoder to capture and convey the global context, and design a lightweight yet powerful decoder to generate an estimated depth map while considering local connectivity. By constructing connected paths between multi-scale local features and the global decoding stream with our proposed selective feature fusion module, the network can integrate both representations and recover fine details. In addition, the proposed decoder shows better performance than the previously proposed decoders, with considerably less computational complexity. Furthermore, we improve the depth-specific augmentation method by utilizing an important observation in depth estimation to enhance the model. Our network achieves state-of-the-art performance over the challenging depth dataset NYU Depth V2. Extensive experiments have been conducted to validate and show the effectiveness of the proposed approach. Finally, our model shows better generalisation ability and robustness than other comparative models.
TiVGAN: Text to Image to Video Generation with Step-by-Step Evolutionary Generator
Sep 04, 2020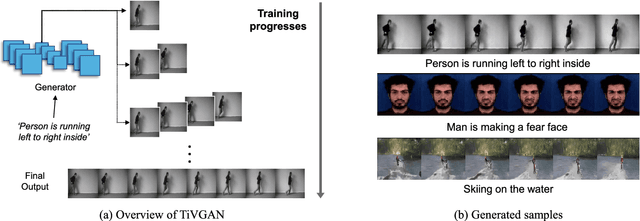
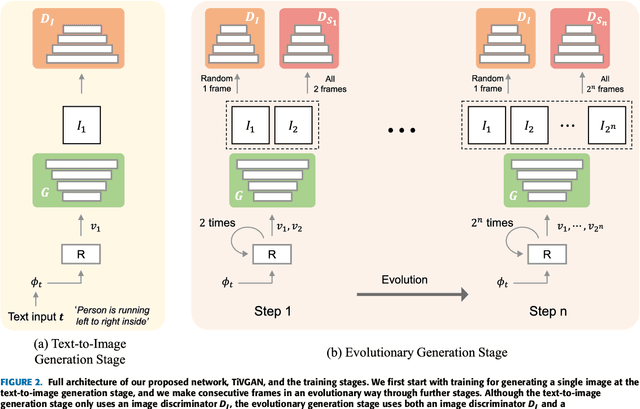
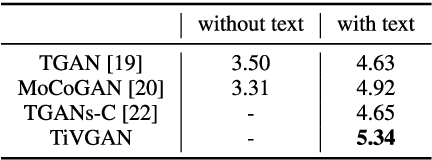
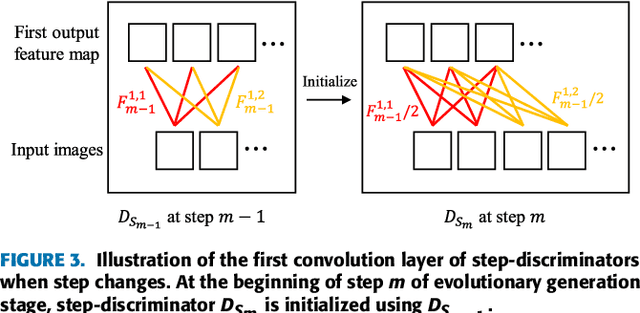
Advances in technology have led to the development of methods that can create desired visual multimedia. In particular, image generation using deep learning has been extensively studied across diverse fields. In comparison, video generation, especially on conditional inputs, remains a challenging and less explored area. To narrow this gap, we aim to train our model to produce a video corresponding to a given text description. We propose a novel training framework, Text-to-Image-to-Video Generative Adversarial Network (TiVGAN), which evolves frame-by-frame and finally produces a full-length video. In the first phase, we focus on creating a high-quality single video frame while learning the relationship between the text and an image. As the steps proceed, our model is trained gradually on more number of consecutive frames.This step-by-step learning process helps stabilize the training and enables the creation of high-resolution video based on conditional text descriptions. Qualitative and quantitative experimental results on various datasets demonstrate the effectiveness of the proposed method.
Continual Learning with Extended Kronecker-factored Approximate Curvature
Apr 16, 2020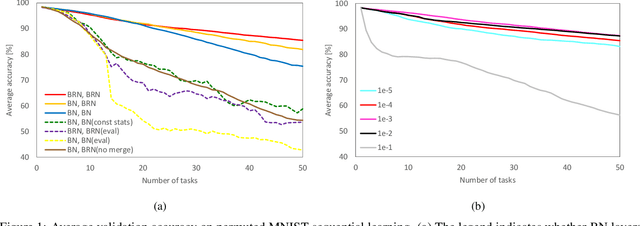
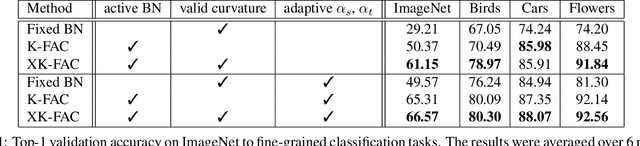
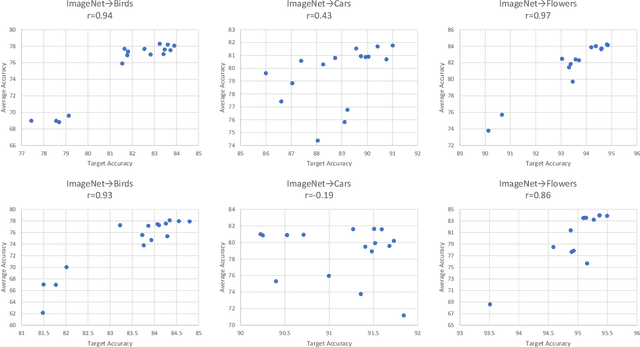
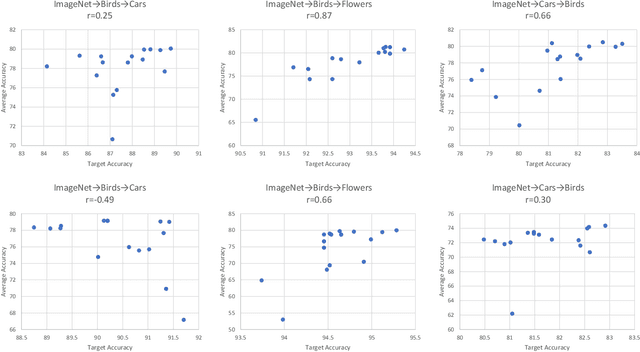
We propose a quadratic penalty method for continual learning of neural networks that contain batch normalization (BN) layers. The Hessian of a loss function represents the curvature of the quadratic penalty function, and a Kronecker-factored approximate curvature (K-FAC) is used widely to practically compute the Hessian of a neural network. However, the approximation is not valid if there is dependence between examples, typically caused by BN layers in deep network architectures. We extend the K-FAC method so that the inter-example relations are taken into account and the Hessian of deep neural networks can be properly approximated under practical assumptions. We also propose a method of weight merging and reparameterization to properly handle statistical parameters of BN, which plays a critical role for continual learning with BN, and a method that selects hyperparameters without source task data. Our method shows better performance than baselines in the permuted MNIST task with BN layers and in sequential learning from the ImageNet classification task to fine-grained classification tasks with ResNet-50, without any explicit or implicit use of source task data for hyperparameter selection.
Residual Continual Learning
Feb 17, 2020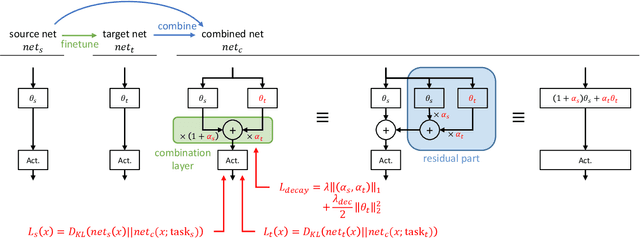

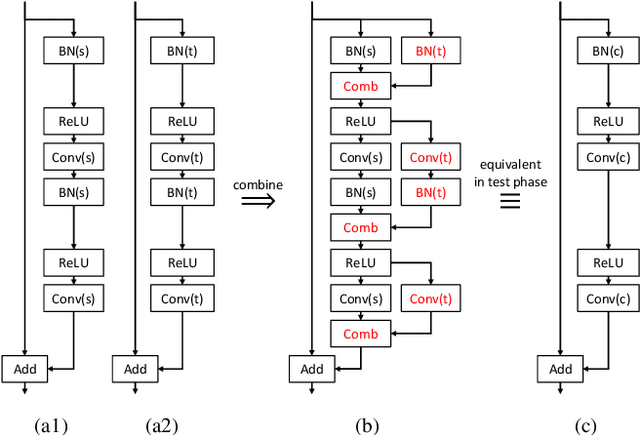

We propose a novel continual learning method called Residual Continual Learning (ResCL). Our method can prevent the catastrophic forgetting phenomenon in sequential learning of multiple tasks, without any source task information except the original network. ResCL reparameterizes network parameters by linearly combining each layer of the original network and a fine-tuned network; therefore, the size of the network does not increase at all. To apply the proposed method to general convolutional neural networks, the effects of batch normalization layers are also considered. By utilizing residual-learning-like reparameterization and a special weight decay loss, the trade-off between source and target performance is effectively controlled. The proposed method exhibits state-of-the-art performance in various continual learning scenarios.
Generating a Fusion Image: One's Identity and Another's Shape
Apr 20, 2018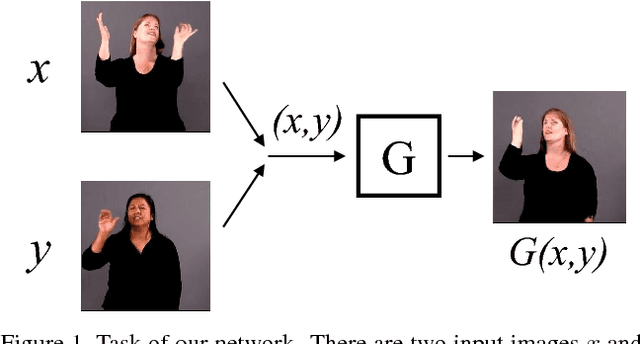
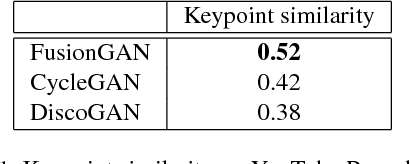
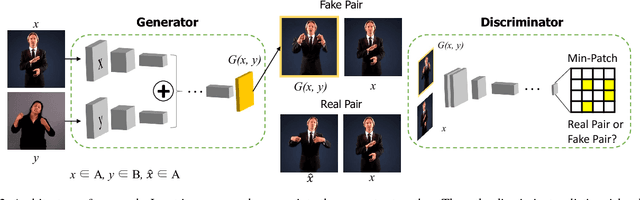
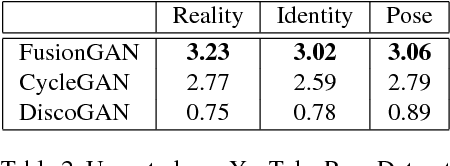
Generating a novel image by manipulating two input images is an interesting research problem in the study of generative adversarial networks (GANs). We propose a new GAN-based network that generates a fusion image with the identity of input image x and the shape of input image y. Our network can simultaneously train on more than two image datasets in an unsupervised manner. We define an identity loss LI to catch the identity of image x and a shape loss LS to get the shape of y. In addition, we propose a novel training method called Min-Patch training to focus the generator on crucial parts of an image, rather than its entirety. We show qualitative results on the VGG Youtube Pose dataset, Eye dataset (MPIIGaze and UnityEyes), and the Photo-Sketch-Cartoon dataset.