 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating a Fusion Image: One's Identity and Another's Shape
Paper and Code
Apr 20, 2018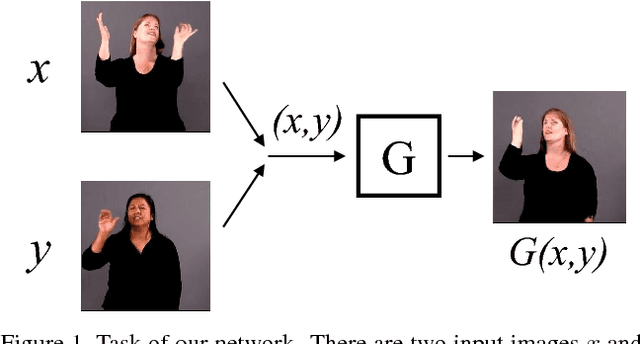
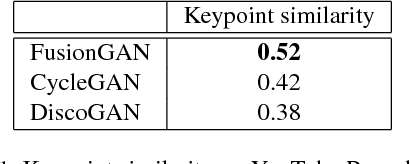
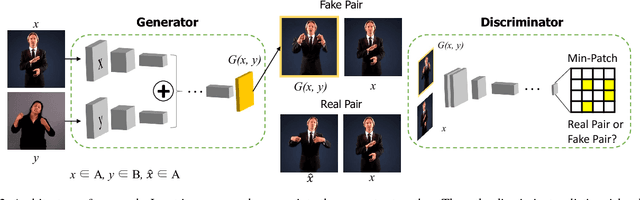
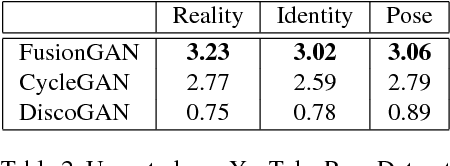
Generating a novel image by manipulating two input images is an interesting research problem in the study of generative adversarial networks (GANs). We propose a new GAN-based network that generates a fusion image with the identity of input image x and the shape of input image y. Our network can simultaneously train on more than two image datasets in an unsupervised manner. We define an identity loss LI to catch the identity of image x and a shape loss LS to get the shape of y. In addition, we propose a novel training method called Min-Patch training to focus the generator on crucial parts of an image, rather than its entirety. We show qualitative results on the VGG Youtube Pose dataset, Eye dataset (MPIIGaze and UnityEyes), and the Photo-Sketch-Cartoon dataset.