 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiVGAN: Text to Image to Video Generation with Step-by-Step Evolutionary Generator
Paper and Code
Sep 04, 2020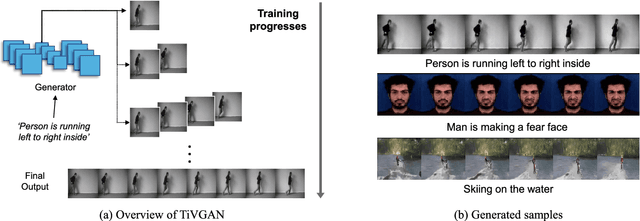
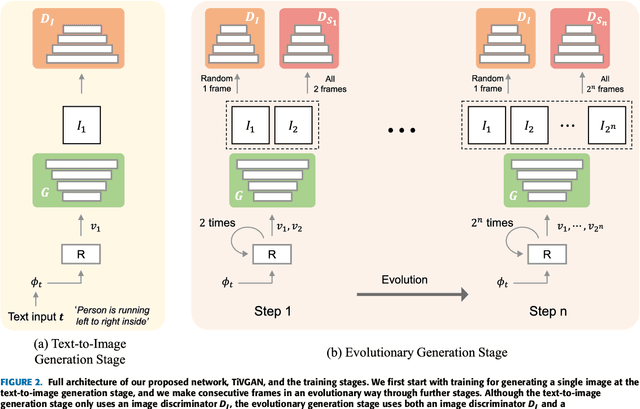
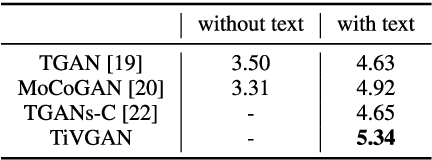
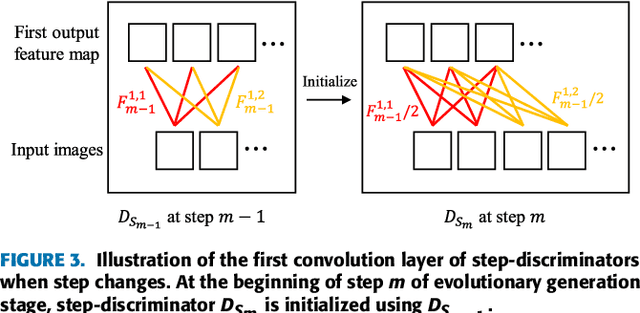
Advances in technology have led to the development of methods that can create desired visual multimedia. In particular, image generation using deep learning has been extensively studied across diverse fields. In comparison, video generation, especially on conditional inputs, remains a challenging and less explored area. To narrow this gap, we aim to train our model to produce a video corresponding to a given text description. We propose a novel training framework, Text-to-Image-to-Video Generative Adversarial Network (TiVGAN), which evolves frame-by-frame and finally produces a full-length video. In the first phase, we focus on creating a high-quality single video frame while learning the relationship between the text and an image. As the steps proceed, our model is trained gradually on more number of consecutive frames.This step-by-step learning process helps stabilize the training and enables the creation of high-resolution video based on conditional text descriptions. Qualitative and quantitative experimental results on various datasets demonstrate the effectiveness of the proposed method.