 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Passive Learning Trap: An Active Perception Strategy for Human Motion Prediction
Nov 18, 2025Forecasting 3D human motion is an important embodiment of fine-grained understanding and cognition of human behavior by artificial agents. Current approaches excessively rely on implicit network modeling of spatiotemporal relationships and motion characteristics, falling into the passive learning trap that results in redundant and monotonous 3D coordinate information acquisition while lacking actively guided explicit learning mechanisms. To overcome these issues, we propose an Active Perceptual Strategy (APS) for human motion prediction, leveraging quotient space representations to explicitly encode motion properties while introducing auxiliary learning objectives to strengthen spatio-temporal modeling. Specifically, we first design a data perception module that projects poses into the quotient space, decoupling motion geometry from coordinate redundancy. By jointly encoding tangent vectors and Grassmann projections, this module simultaneously achieves geometric dimension reduction, semantic decoupling, and dynamic constraint enforcement for effective motion pose characterization. Furthermore, we introduce a network perception module that actively learns spatio-temporal dependencies through restorative learning. This module deliberately masks specific joints or injects noise to construct auxiliary supervision signals. A dedicated auxiliary learning network is designed to actively adapt and learn from perturbed information. Notably, APS is model agnostic and can be integrated with different prediction models to enhance active perceptual. The experimental results demonstrate that our method achieves the new state-of-the-art, outperforming existing methods by large margins: 16.3% on H3.6M, 13.9% on CMU Mocap, and 10.1% on 3DPW.
Shortcut Learning in In-Context Learning: A Survey
Nov 04, 2024
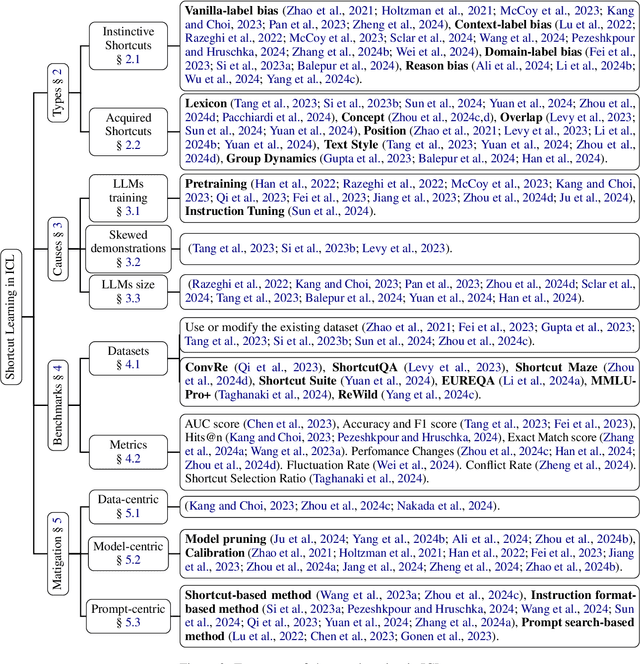
Shortcut learning refers to the phenomenon where models employ simple, non-robust decision rules in practical tasks, which hinders their generalization and robustness. With the rapid development of large language models (LLMs) in recent years, an increasing number of studies have shown the impact of shortcut learning on LLMs. This paper provides a novel perspective to review relevant research on shortcut learning in In-Context Learning (ICL). It conducts a detailed exploration of the types of shortcuts in ICL tasks, their causes, available benchmarks, and strategies for mitigating shortcuts. Based on corresponding observations, it summarizes the unresolved issues in existing research and attempts to outline the future research landscape of shortcut learning.
TACIT: A Target-Agnostic Feature Disentanglement Framework for Cross-Domain Text Classification
Dec 25, 2023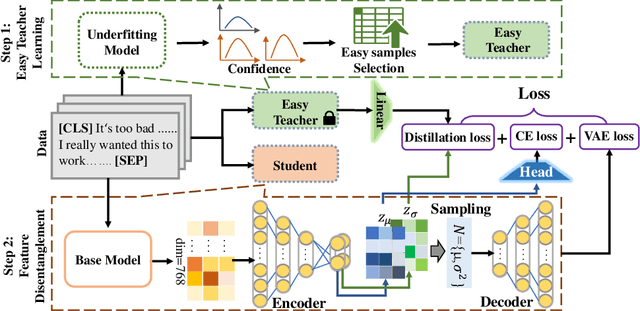
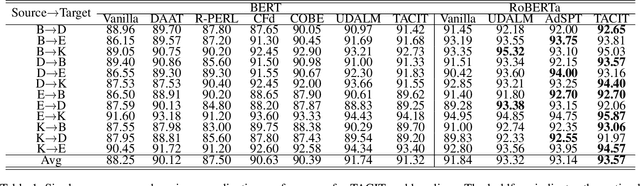
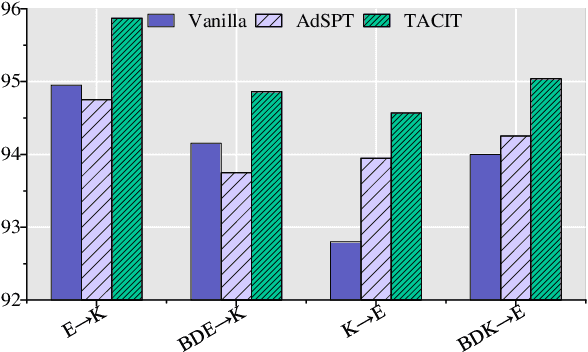

Cross-domain text classification aims to transfer models from label-rich source domains to label-poor target domains, giving it a wide range of practical applications. Many approaches promote cross-domain generalization by capturing domain-invariant features. However, these methods rely on unlabeled samples provided by the target domains, which renders the model ineffective when the target domain is agnostic. Furthermore, the models are easily disturbed by shortcut learning in the source domain, which also hinders the improvement of domain generalization ability. To solve the aforementioned issues, this paper proposes TACIT, a target domain agnostic feature disentanglement framework which adaptively decouples robust and unrobust features by Variational Auto-Encoders. Additionally, to encourage the separation of unrobust features from robust features, we design a feature distillation task that compels unrobust features to approximate the output of the teacher. The teacher model is trained with a few easy samples that are easy to carry potential unknown shortcuts. Experimental results verify that our framework achieves comparable results to state-of-the-art baselines while utilizing only source domain data.
A Survey on Fairness in Large Language Models
Aug 20, 2023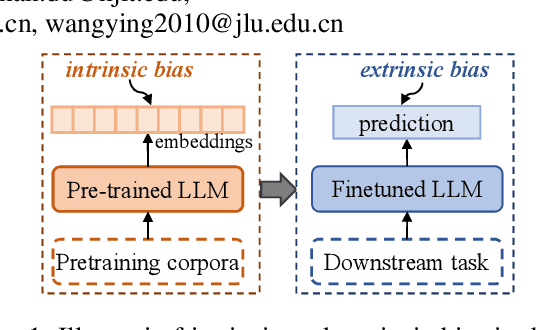
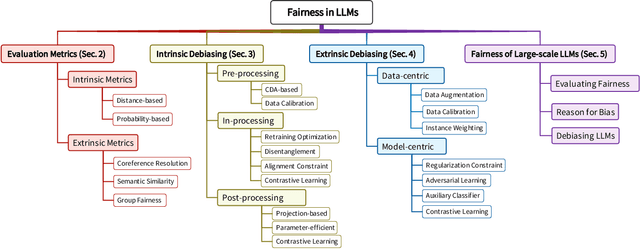
Large language models (LLMs) have shown powerful performance and development prospect and are widely deployed in the real world. However, LLMs can capture social biases from unprocessed training data and propagate the biases to downstream tasks. Unfair LLM systems have undesirable social impacts and potential harms. In this paper, we provide a comprehensive review of related research on fairness in LLMs. First, for medium-scale LLMs, we introduce evaluation metrics and debiasing methods from the perspectives of intrinsic bias and extrinsic bias, respectively. Then, for large-scale LLMs, we introduce recent fairness research, including fairness evaluation, reasons for bias, and debiasing methods. Finally, we discuss and provide insight on the challenges and future directions for the development of fairness in LLMs.
Prompt Tuning Pushes Farther, Contrastive Learning Pulls Closer: A Two-Stage Approach to Mitigate Social Biases
Jul 04, 2023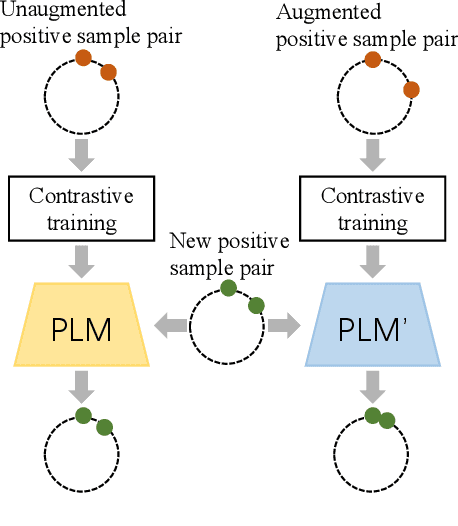
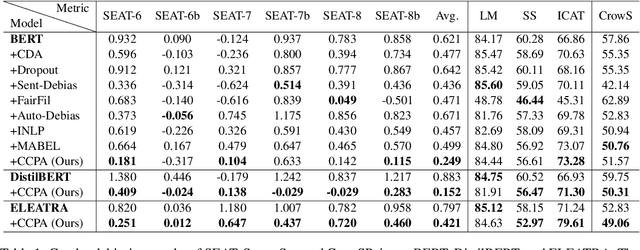
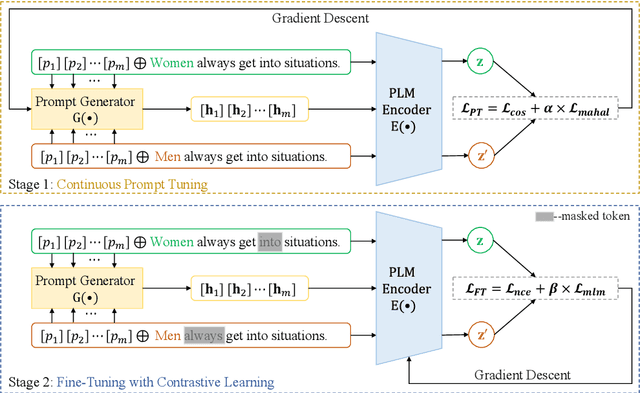
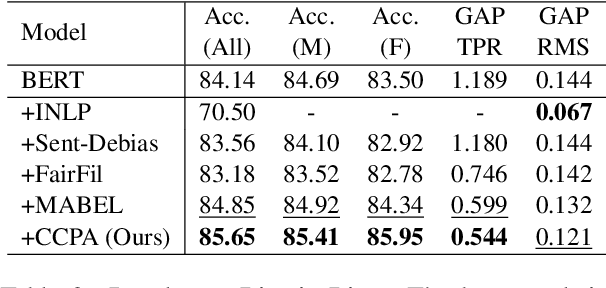
As the representation capability of Pre-trained Language Models (PLMs) improve, there is growing concern that they will inherit social biases from unprocessed corpora. Most previous debiasing techniques used Counterfactual Data Augmentation (CDA) to balance the training corpus. However, CDA slightly modifies the original corpus, limiting the representation distance between different demographic groups to a narrow range. As a result, the debiasing model easily fits the differences between counterfactual pairs, which affects its debiasing performance with limited text resources. In this paper, we propose an adversarial training-inspired two-stage debiasing model using Contrastive learning with Continuous Prompt Augmentation (named CCPA) to mitigate social biases in PLMs' encoding. In the first stage, we propose a data augmentation method based on continuous prompt tuning to push farther the representation distance between sample pairs along different demographic groups. In the second stage, we utilize contrastive learning to pull closer the representation distance between the augmented sample pairs and then fine-tune PLMs' parameters to get debiased encoding. Our approach guides the model to achieve stronger debiasing performance by adding difficulty to the training process. Extensive experiments show that CCPA outperforms baselines in terms of debiasing performance. Meanwhile, experimental results on the GLUE benchmark show that CCPA retains the language modeling capability of PLMs.
Automatic Counterfactual Augmentation for Robust Text Classification Based on Word-Group Search
Jul 01, 2023Despite large-scale pre-trained language models have achieved striking results for text classificaion, recent work has raised concerns about the challenge of shortcut learning. In general, a keyword is regarded as a shortcut if it creates a superficial association with the label, resulting in a false prediction. Conversely, shortcut learning can be mitigated if the model relies on robust causal features that help produce sound predictions. To this end, many studies have explored post-hoc interpretable methods to mine shortcuts and causal features for robustness and generalization. However, most existing methods focus only on single word in a sentence and lack consideration of word-group, leading to wrong causal features. To solve this problem, we propose a new Word-Group mining approach, which captures the causal effect of any keyword combination and orders the combinations that most affect the prediction. Our approach bases on effective post-hoc analysis and beam search, which ensures the mining effect and reduces the complexity. Then, we build a counterfactual augmentation method based on the multiple word-groups, and use an adaptive voting mechanism to learn the influence of different augmentated samples on the prediction results, so as to force the model to pay attention to effective causal features. We demonstrate the effectiveness of the proposed method by several tasks on 8 affective review datasets and 4 toxic language datasets, including cross-domain text classificaion, text attack and gender fairness test.