 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Fairness in Large Language Models
Paper and Code
Aug 20, 2023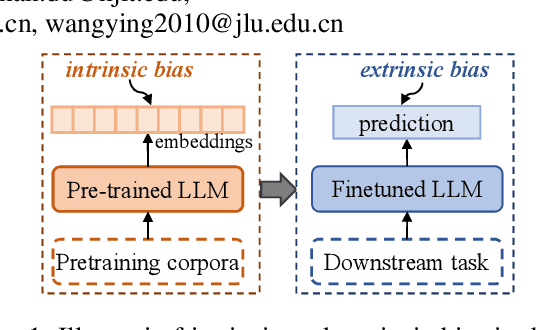
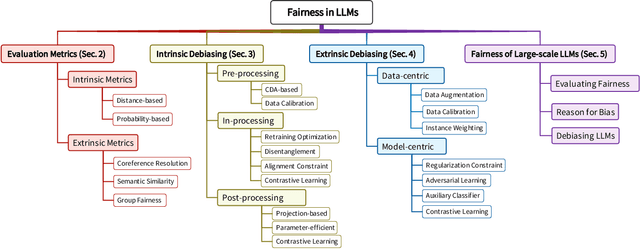
Large language models (LLMs) have shown powerful performance and development prospect and are widely deployed in the real world. However, LLMs can capture social biases from unprocessed training data and propagate the biases to downstream tasks. Unfair LLM systems have undesirable social impacts and potential harms. In this paper, we provide a comprehensive review of related research on fairness in LLMs. First, for medium-scale LLMs, we introduce evaluation metrics and debiasing methods from the perspectives of intrinsic bias and extrinsic bias, respectively. Then, for large-scale LLMs, we introduce recent fairness research, including fairness evaluation, reasons for bias, and debiasing methods. Finally, we discuss and provide insight on the challenges and future directions for the development of fairness in LLMs.