 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Tuning Pushes Farther, Contrastive Learning Pulls Closer: A Two-Stage Approach to Mitigate Social Biases
Paper and Code
Jul 04, 2023
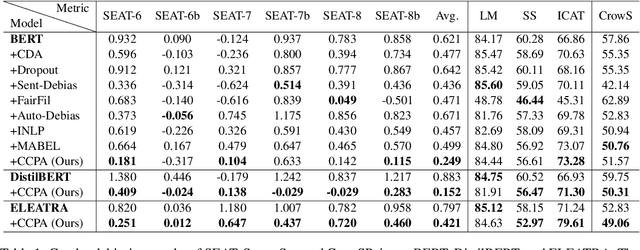
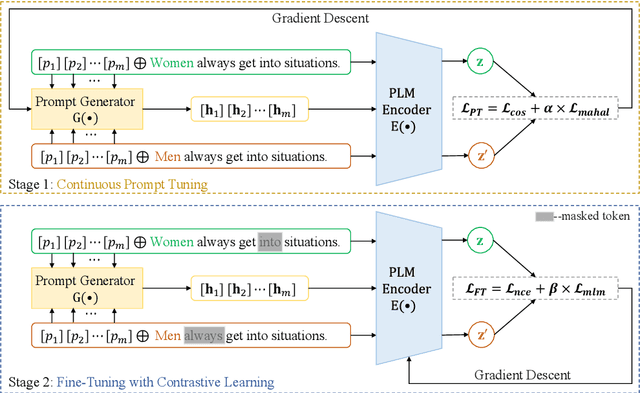
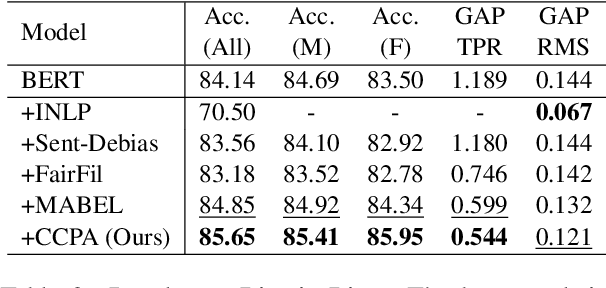
As the representation capability of Pre-trained Language Models (PLMs) improve, there is growing concern that they will inherit social biases from unprocessed corpora. Most previous debiasing techniques used Counterfactual Data Augmentation (CDA) to balance the training corpus. However, CDA slightly modifies the original corpus, limiting the representation distance between different demographic groups to a narrow range. As a result, the debiasing model easily fits the differences between counterfactual pairs, which affects its debiasing performance with limited text resources. In this paper, we propose an adversarial training-inspired two-stage debiasing model using Contrastive learning with Continuous Prompt Augmentation (named CCPA) to mitigate social biases in PLMs' encoding. In the first stage, we propose a data augmentation method based on continuous prompt tuning to push farther the representation distance between sample pairs along different demographic groups. In the second stage, we utilize contrastive learning to pull closer the representation distance between the augmented sample pairs and then fine-tune PLMs' parameters to get debiased encoding. Our approach guides the model to achieve stronger debiasing performance by adding difficulty to the training process. Extensive experiments show that CCPA outperforms baselines in terms of debiasing performance. Meanwhile, experimental results on the GLUE benchmark show that CCPA retains the language modeling capability of PLMs.