 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Bridging the Digital Language Divide
Paper and Code
Jul 25, 2023
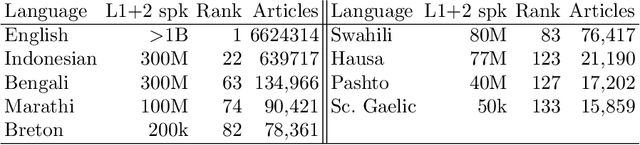


It is a well-known fact that current AI-based language technology -- language models, machine translation systems, multilingual dictionaries and corpora -- focuses on the world's 2-3% most widely spoken languages. Recent research efforts have attempted to expand the coverage of AI technology to `under-resourced languages.' The goal of our paper is to bring attention to a phenomenon that we call linguistic bias: multilingual language processing systems often exhibit a hardwired, yet usually involuntary and hidden representational preference towards certain languages. Linguistic bias is manifested in uneven per-language performance even in the case of similar test conditions. We show that biased technology is often the result of research and development methodologies that do not do justice to the complexity of the languages being represented, and that can even become ethically problematic as they disregard valuable aspects of diversity as well as the needs of the language communities themselves. As our attempt at building diversity-aware language resources, we present a new initiative that aims at reducing linguistic bias through both technological design and methodology, based on an eye-level collaboration with local communities.