 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailoring and Evaluating the Wikipedia for in-Domain Comparable Corpora Extraction
Paper and Code
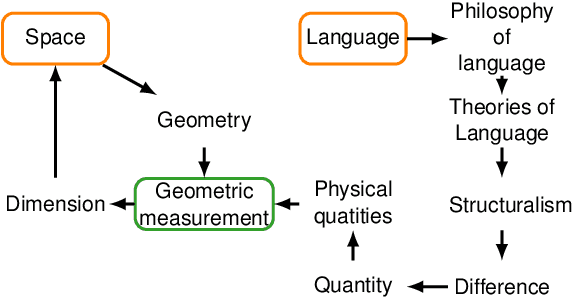
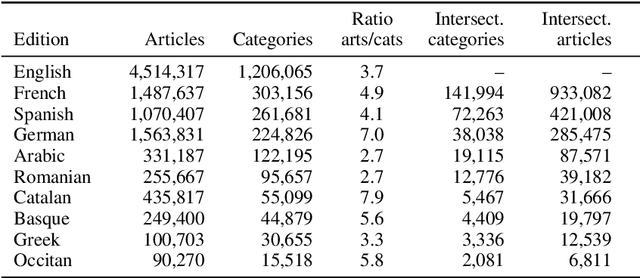
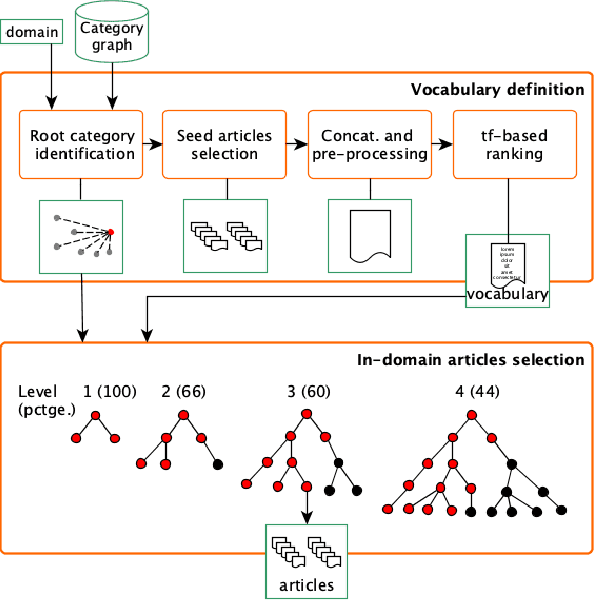
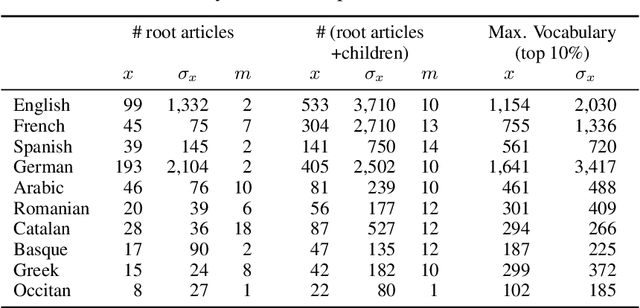
We propose an automatic language-independent graph-based method to build \`a-la-carte article collections on user-defined domains from the Wikipedia. The core model is based on the exploration of the encyclopaedia's category graph and can produce both monolingual and multilingual comparable collections. We run thorough experiments to assess the quality of the obtained corpora in 10 languages and 743 domains. According to an extensive manual evaluation, our graph-based model outperforms a retrieval-based approach and reaches an average precision of 84% on in-domain articles. As manual evaluations are costly, we introduce the concept of "domainness" and design several automatic metrics to account for the quality of the collections. Our best metric for domainness shows a strong correlation with the human-judged precision, representing a reasonable automatic alternative to assess the quality of domain-specific corpora. We release the WikiTailor toolkit with the implementation of the extraction methods, the evaluation measures and several utilities. WikiTailor makes obtaining multilingual in-domain data from the Wikipedia easy.